Solr查询配置及优化【eDisMax查询解析器】
云山之巅 人气:0一.简介
Lucene查询解析器语法支持创建任意复杂的布尔查询,但还有一些缺点,它不是用户查询处理的理想解决方案。这里面最大的问题是Lucene查询解析器的语法要求严格,一旦破坏就会抛出异常。指望用户在输入关键词时能够理解Lucene查询语法并始终能输入完美的查询表达式,这显然是不合理的。这意味着,Lucene查询解析器在许多搜索应用中对用户不够友好。
Lucene查询解析器的另一个缺点是它不能默认搜索多个字段。df参数定义了查询解析器默认搜索哪个字段,但是如果想要以不同权重对多个字段进行搜索时,就必须先对查询进行预处理。对大多数Solr开发人员来说,这样的查询预处理工作量过大。为了将用户查询直接传入Solr并优雅地进行处理,扩展的析取最大化查询解析器eDisMax应运而生。
二.eDisMax查询解析器概述
eDisMax查询解析器实际上是由Lucene查询解析器和DisMax查询解析器组成。DisMax查询解析器是eDisMax查询解析器的旧版本,只接受关键词和少数几个基本的布尔运算,允许在多个字段中搜索关键词。因为DisMax查询解析器是eDisMax查询解析器的一个子集,所有不建议使用原始的DisMax查询解析器。
虽然eDisMax查询解析器不是Solr的默认查询解析器,但它具有查询语法容错性,不像Lucene查询解析器那样严格。
三.eDisMax查询参数
eDisMax查询解析器支持Lucene查询解析器的所有查询语法。它们之间只有一个明显差异,eDisMax的输入语法不会抛出异常,而是将无效的输入作为文本字符串进行搜索。它还在语法解析上具有一定的容错性,支持特殊关键词。例如,可以理解小写转换后的AND和OR。这种灵活性和容错性让它比Lucene查询解析器更适合处理用户输入。

四.搜索多个字段
除了安全地处理用户输入文本和自由地解析查询语法,eDisMax查询解析器最有用的一个功能是对多个字段进行搜索。eDisMax查询解析器会将每个内容放在各自的字段中。通过指定查询和查询字段。例如:
q=solr in action&qf=title description author
另外,还可以根据意愿在每个查询基础上调整权重。
q=solr in action&qf=title^1.5 description author^3

五.查询与短语权重调整
eDisMax查询解析器的一个重要功能是调整彼此邻近的词项的相关度。使用Lucene查询解析器的典型查询,不管词项是否彼此邻近,或是否视为一个短语,所有词项的相关度都是一样的。eDisMax查询解析器的另一个功能是,对独立于用户主查询的函数进行任意地相关度调整。
1.pf【短语字段】、pf2和pf3参数
pf参数用于调整那些q参数中所有词项彼此非常靠近的文档得分。pf参数与qf参数使用相同的格式,获取字段列表及可选的相应权重。eDisMax查询解析器尝试对q参数中所有词项进行短语查询,如果能在任何短语字段中找到确切的短语,则对匹配的文档调整相应的权重。
除了pf参数,eDisMax查询解析器还支持pf2和pf3参数。这些参数功能与pf参数类似,不过不需要q参数中所有词项,它们将词项分解为二元【pf2】或三元【pf3】,只对包含少量词项的文档调整权重。例如:在查询Solr finds relevant documents中,pf3参数会对包含短语"solr finds relevant" 或 "finds relevant documents"的文档调整权重。pf2与之类似,对包含其中任意两个连续词短语的文档进行权重调整。
2.ps【短语间隔】、ps2和ps3参数
使用pf参数时,可能不希望查询中的所有词项作为一个精确的短语出现。使用ps参数可以指定查询中的词项间隔位置界限,以此在短语字段上判断匹配情况。eDisMax查询解析器还支持ps2和ps3参数,允许为ps2和ps3修改短语间隔值。不明确指定时默认为ps参数。
3.qs【查询短语间隔】参数
qs参数对用户在主查询q参数上明确指定短语的处理方式类似。将qs参数视为重新定义要匹配的确切内容,可以将间隔默认值为0修改为更高的数值。
4.tie【决胜局】参数
当查询的词项与文档的多个字段匹配时,tie参数可以决定如何处理这种情况。为匹配到的每个字段的每个词项计算其相关度得分,默认情况下,每个文档中得分最高的字段用于该词项的相关度计算。这是析取的最大得分,也是该查询解析器得名“析取最大值”的原因所在。这与Lucene查询解析器形成鲜明对比,Lucene查询解析器通常将每个字段的每个词项的相关度得分相加,计算出每个文档的综合相关度得分。
tie参数决定了最匹配的字段之外的其他字段的词项相关度得分有多少应该贡献给总体相关度得分。tie参数的默认值为0.0,这表示其它字段不贡献权重。当tie为1时,表示贡献全部权重,此时相关等同于Lucene查询解析器。在这种情况下,相关度评分使用的是析取和而不是析取最大值。
5.bq【提升查询】参数
bq参数接受查询字符串,其包含在主查询q参数中,用来影响相关度得分。它不会影响匹配到的文档数,只影响文档返回的顺序。如果想为最近的文档提升相关度,可以在请求中添加一下内容:
bq=date:[NOW/DAY-1YEAR TO NOW/DAY]
这将有效提升日期属于去年的所有文档的相关度得分。另外,还可以指定多个bq参数,在查询解析时针对不同子句分别进行提升。
6.bf【提升函数】参数
bf参数能够通过函数查询来提升主查询的相关度。例如,提升最新日期的文档的相关度:
recip(rord(date),1,1000,1000)
bf参数接受Solr支持的所有函数及其权重值。
六.字段别名
有时候需要在Solr中使用内部字段名,这些字段名并不适合显示给用户。对于动态字段来说尤为如此,动态字段名可能类似title_t_en这样,但是我们希望在搜索中使用对用户更友好的语法,例如,title:"some title"。eDisMax查询解析器为此提供了字段别名机制。
eDisMax查询中的字段别名通过在请求中添加参数f.{alias}.qf={realfield}来实现。例如:
/select?defType=edismax&q=title:"some title"&f.title.qf=title_t_en
查询在title_t_en字段上执行,接下来它会被查询中出现的title字段替换。字段别名参数在默认的qf参数后使用,这意味着,可以将一个别名分别以不同的权重对应到多个内部字段。在请求中添加任意数量的别名也是可以的。
多别名字段的搜索类似于默认字段的搜索,其中每个查询词项被分布在别名定义的查询字段上。唯一的区别是可以为每个别名定义单独的qf字段,而不是为默认字段定义一个qf参数。因此,与每个别名相关的查询部分会对字段列表进行搜索。
七.可访问字段
在许多情况下,用户只能对默认字段以及可能的一小部分其它字段进行关键词搜索。由于有些内部字段可能会包含某些敏感信息【例如,用户ID或其他内部标识符】,可能不希望用户从Solr索引中猜出其他字段并查询它们。
虽然eDisMax查询解析器允许主查询q参数对任何字段进行搜索,但也可以使用uf【用户字段】参数来加以限制。默认值是uf=*,允许用field:expression语法查询所有字段。如果要限制可用字段为单个title字段,指定uf=title即可。多字段的访问使用空格隔开:uf=title city date。如果要对用户禁用所有字段,则使用否定语法:uf=-*。如果要对指定字段列表之外的其他字段进行访问,则使用uf=* -hiddenField1 -hiddenField2...
为确保完全控制用户查询,可以将uf参数和字段别名参数结合使用。uf参数既接受真实字段,也接受别名。这样设置可以保护搜索引擎不访问未经授权的字段。
八.最小匹配
在布尔逻辑中使用二元运算符:AND和OR。它们是Lucene对必须匹配和应该匹配的内部表达形式。查询表达式hello AND world可以改写为+hello +world,这表示hello和world都必须匹配。OR用法于此类似,表示此中存在匹配的即可。
eDisMax查询解析器通过mm【最小匹配】参数模糊了传统布尔逻辑的界限。为了让文档实现匹配,mm参数在查询中可以定义必须匹配的特定数量的词项或词项的百分比。这是对搜索应用的查准率与查全率进行操作的一个好方式。原因在于,它不要求所有词项必须匹配【默认运算符为AND】或仅需要匹配其中一个词项即可【默认运算符为OR】。
mm参数语法非常丰富,很难一下子掌握。例如:

mm可以定义必须匹配的表达式数量【正整数】、遗漏的表达式数量【负整数】、必须匹配的表达式百分比【正百分比】以及遗漏的表达式百分比【负百分比】。要进一步控制的话,根据查询中现有的表达式数量,可以定义不同的最小匹配规则。以下面的查询结构为例:
/select?q={!edismax mm="2<50% 4<-45%" v=$example}&example=...
对于该查询,以下规则将对不同的示例参数值生效:

eDisMax查询解析器的最小匹配功能可以包含多个关键词的查询进行匹配质量和数量的细粒度控制。图解从交集的角度解释最小匹配阈值的作用:
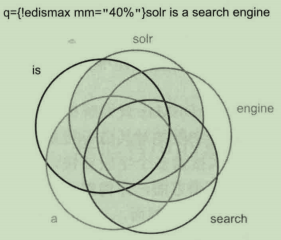
解释:5个词项的最小匹配值设置为40%。在这种情况下,5个词项至少需要匹配2个。与传统的布尔逻辑AND/OR相比,最小匹配支持不同的交集。
mm参数变大通常会提高查准率,mm参数变小通常会提高查全率。
从本质上讲,小于1的最小匹配值永远不会被使用【因为至少需要一个】,大于子句数量的最小匹配值也不会被使用【因为最大值是查询中的子句数量】。
九.eDisMax查询解析器的优缺点
eDisMax查询解析器除了支持Lucene查询解析器的所有查询语法外,还提供了许多附加功能。例如:多字段搜索、清理用户输入、字段别名和字段限制,以及通过多查询修正来改进短语相关度和其它权重因素。
使用eDisMax查询解析器也有一些缺点。首先是与eDisMax查询解析器进行多字段搜索相关的处理问题。如果将所有词项放入一个字段并对其进行搜索,Lucene查询解析器的查询速度比使用eDisMax查询解析器在相同的查询表达式搜索多个字段要快。当然,eDisMax查询解析器也可以单字段搜索。然而,eDisMax查询解析器可以实现轻松多字段搜索的同时,会为许多基于Solr的搜索应用带来额外的执行花销。
加载全部内容