如何正确使用redis分布式锁
悟空不败 人气:1前言
笔者在公司担任技术面试官,在笔者面试过程中,如果面试候选人提到了reids分布式锁,笔者都会问一下redis分布式锁的知识点,但是令笔者遗憾的是,该知识点十个人中有九个人都答得不清楚,或者回答错误,这让笔者有了写这篇文章的想法,来帮助童鞋们正确认识reids分布式锁.
什么是分布式锁?为什么需要分布式锁?
在java中,在单进程多线程的情况下,为了防止多个线程共同竞争同一个资源,因此需要锁,java中有显示锁和隐式锁来保证,而在多进程的情况下,普通的锁就无法满足要求了,因此我们需要分布式锁,常用的分布式锁解决方案有三种,分别是基于数据库/redis/zookeeper,本文我们主要讨论redis分布式锁.
redis分布式锁实现
笔者在面试过程中,问redis分布式锁知识点时的第一个问题就是如何实现一个redis分布式锁,许多候选人直接说,啊,这很简单啊,使用setNx()方法,设置一个过期时间就可以了,我接着问,那如何释放锁锁呢?候选人回答说,那很简单啊,直接调用delete方法就可以了,我接着问,释放锁直接调用delete方法就可以了吗?候选人回答,对啊,delete方法也是线程安全的,我.....那么如何实现一个redis分布式锁,我们用代码来演示一下,首先来看一下加锁的代码片段:
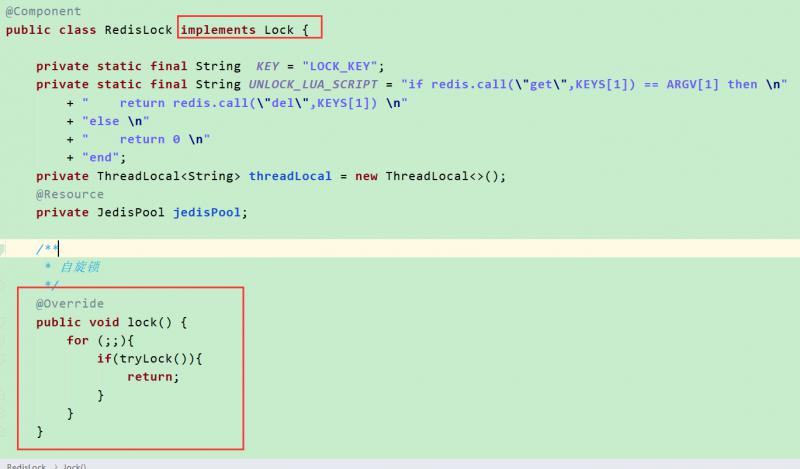
首先我们的分布式锁实现了Lock接口,然后主要看我们的lock方法,阻塞式自旋锁,加锁方法直接使用tryLock(),接下来我们再来看看tryLock()方法:

其实很简单,主要是调用redis的set方法(其中UUID笔者为了方便演示,直接使用UUID,在分布式的生产环境下应该使用诸如雪花算法等来保证分布式系统下UUDI的唯一性),如果返回OK则说明加锁成功,否则失败,再来看看释放锁的方法,面试过程中很多候选人童鞋说直接调用delete方法,我们写一段代码,然后分析一下直接调用delete方法的问题:

如上一段代码,假设一种极端场景下有两个线程A和B,A线程先获取锁,设置过期时间为10秒,然后A线程执行释放锁操作,执行到if判断语句并且成功进入时,此时耗时刚好10秒,锁过期了,并且CPU分配给A线程的时间片刚好用完,此时B线程开始执行并且成功获取到该分布式锁,然后执行一段时间后B线程的时间片用完,此时A继续执行删除操作,此时A删除的就是B线程的锁,会造成误删除操作,因此为了避免这种情况,我们需要一种机制来保证判断和删除操作的原子性,redis官方推荐我们使用lua脚本,因此正确的解锁方式如下:

其中的UNLOCK_LUA_SCRIPT如下:

redis使用lua脚本能保证该操作的原子性,因此这样才能正确释放分布式锁.这也回答了为什么之前说释放锁的时候直接调用delete方法是错误的.
有什么问题?
在上文中,我们使用redis构建了一个分布式锁,但是请注意,该代码在单机环境下没有任何问题,但是我们在生产中往往都是redis集群部署,由于redis主从节点的数据同步是异步的,如果Redis的master节点在锁未同步到Slave节点的时候宕机了怎么办?举例来说:
1.进程A在master节点获得了锁。
2.在锁同步到slave之前,master宕机,数据还没有同步到slave
3.slave变成了新的master节点
4.进程B也得到了和A相同的锁.
因此,如果你的业务允许在master宕机期间,多个客户端允许同时都持有锁,那如上的分布式锁是可以接受的,否则就不能使用上述的分布式锁,在这种情况下,redis官方为我们提供了另一种解决方案----RedLock算法.
RedLock算法
假设我们有N个Master节点(N一般为奇数),这些节点互相之间相互独立,不需要进行数据同步,我们用在单节点获取和释放锁的方式来操纵这些节点,具体过程为:
1.获取当前时间(单位是毫秒)。
2.轮流用相同的key和随机值在N个节点上请求锁,在这一步里,客户端在每个master上请求锁时,会有一个和总的锁释放时间相比小的多的超时时间。比如如果锁自动释放时间是10秒钟,那每个节点锁请求的超时时间可能是5-50毫秒的范围,这个可以防止一个客户端在某个宕掉的master节点上阻塞过长时间,如果一个master节点不可用了,我们应该尽快尝试下一个master节点。
3.客户端计算第二步中获取锁所花的时间,只有当客户端在大多数master节点上成功获取了锁(N/2+1在这里是3个),而且总共消耗的时间不超过锁释放时间,这个锁就认为是获取成功了。
4.如果锁获取成功了,那现在锁自动释放时间就是最初的锁释放时间减去之前获取锁所消耗的时间。
5.如果锁获取失败了,不管是因为获取成功的锁不超过一半(N/2+1)还是因为总消耗时间超过了锁释放时间,客户端都会到每个master节点上释放锁,即便是那些他认为没有获取成功的锁。
有关RedLock的算法,可以详见官网文档
RedLock算法是否真的足够安全?
要回答这个问题,可以看看国外大神Martin Kleppmann在他的一篇文章How to do distributed locking中详细描述了为什么他认为RedLock仍然是不安全的,简单来说,RedLock最大的弊端有两个:
1.进程由于各种原因pause,类似于上文说的多线程间的时间片切换,比如由于GC停顿等导致锁过期,但是进程并未感知到,同时另一个进程已经获取了该分布式锁,就会导致奇怪的结果发生.
2.算法对时钟依赖性太强,假设N个节点为5,按照超过一半的原则,假设进程X成功获取了A/B/C三个节点的锁,此时认为X获取锁成功,此时X在TTL时间段内没有执行完成,锁到期自动释放,此时由于C节点的时间比A/B节点快,导致C节点先释放锁,此时Y节点获取了C/D/E三个节点的锁,又导致两个进程获取了同一个锁.
无论如何,在多master节点的情况下,没有任何方案能完美保证RedLock的绝对安全,因此,我们在使用redis分布式锁的时候一定要弄清楚我们的目的是什么?一般来说,有两种情况:
1.为了提高性能.比如持有该锁使我们的程序不会进行重复的计算,在这种情况下,如果锁失败了我们付出的代价仅仅是进行了重复的计算,不会影响我们的业务结果.
2.为了保证业务的正确性.比如我们是一个银行系统,为了保证转账操作扣款唯一性,拥有该锁可以确保我们的扣款操作的唯一性,如果锁失效,会导致多次扣款,这是无法接受的.
如果我们是为了提升性能,那没有必要使用RedLock算法,它成本高(假设需要5个master节点,这些节点还要保证高可用,则需要更多的节点)且又复杂,不如使用在单机情况下的分布式锁,前提是你的业务能容忍我们上述说的宕机期间相同锁的问题.
如果是为了保证业务的正确性,我们说了RedLock也不能完美保证绝对安全,因此也不能放心的使用RedLock.
总结
总而言之,使用Redis分布式锁实在不是一个好的选择,Redis设计的初衷也并不是满足分布式锁的需求.对于需求性能的分布式锁应用它太重了且成本高;对于需求正确性的应用来说它不够安全.如果你的应用只需要高性能的分布式锁并且不要求多高的正确性,那么单节点的Redis分布式锁足够了;如果你的应用想要保证正确性,那么不建议 RedLock,建议使用一个合适的一致性协调系统,比如基于Zookeeper的分布式锁!
本文由博客一文多发平台 OpenWrite 发布!
加载全部内容