区块链技术基础原理与算法(比特币为例,主要是比特币的原理),密码学原理
白杨的博客 人气:1密码学原理
对称加密算法
原理
对称加密:使用同一密钥进行加密和解密
传统密码加密,私钥算法加密,加密速度快,密文是紧凑的安全的
加密过程
A同学生成明文->通过私钥和加密算法->生成密文->将密文通过网络传输到目的地B同学->通过同一私钥以及解密算法->解密为明文
对称加密算法的缺点:
两个人有一对密钥,那么3个人就需要3个密钥,两两之间都需要一个密钥,人越多密钥越多,并且为了安全起见,密钥用过一次就会丢弃更换密钥,就出现了一系列问题:密钥分发、密钥存储和管理、缺乏对数字签名/不可否认的支持
常用对称算法:
DES :
l des是一种块或分组加密算法,20世纪70年代IBM公司发明,1976年11月纳为美国国家标准
l DES密钥是固定的56bit,不够安全
l DES以块模式对64bit的块进行操作,解释如下:
假如有一段1G的明文数据需要加密,加密算法首先将这段明文数据按照64bit一段一段分开,然后加密64bit的明文块。(如果加密的数据长度不是64位的倍数,可以按照某种具体的规则来填充位。)
64bit明文->初始置换IP->在密钥控制下16轮迭代->交换左右32bit->初始逆向置换IP->输出64bit密文
DES有两种方式ECB和CBC
ECB方式:
就是将数据按照8个字节一段进行DES加密或解密得到一段段的8个字节的密文或者明文,最后一段不足8个字节,按照需求补足8个字节(一般补0或者F)进行计算(并行计算),之后按照顺序将计算所得的数据连在一起即可,各段数据之间互不影响。这样一来相同的明文和密钥得到的是相同的密文,经过大量的统计分析和尝试攻击,密文很有可能被破解,比如中文出现最多的字“的”,可能很快就能到这个明文对应的密文。
CBC方式:
- 首先将数据按照8个字节一组进行分组得到D1D2…Dn(若数据不是8的整数倍,用指定的补位数据补位)
- 第一组数据D1与初始化向量IV异或后的结果进行DES加密得到第一组密文C1(初始化向量IV为全零)
- 第二组数据D2与第一组的加密结果C1异或以后的结果进行DES加密,得到第二组密文C2
- 之后的数据以此类推,得到Cn
- 按顺序连为C1C2C3…Cn即为加密结果。
简单讲就是首先将明文分组与前一个密文分组进行异或运算,然后再进行加密,上面提到的初始化向量IV,是因为当加密第一个明文分组时,不存在前一个密文分组,因此需要准备一个长度为一个分组的比特序列来代替前一个密文分组,通常缩写为IV。这样的方式就保证了明文和密文并不是一一对应关系,即同一组明文不一定为同一组密文。安全性提高了很多。
虽然des算法是安全的,但是56bit的密钥长度太短,容易被暴力破解,不够安全,所以需要经常修改密钥,防止暴力破解,另外交换密钥的方式或者说通道,必须是安全的,防止密钥泄露。
3DES
3des算法密钥长度达到了168位,并且做了3遍des加密(严格意义上说是两遍),所以暴力破解可能性很低,达到了更高程度的安全。但是会变慢增加延时,不适用与语音视频的加解密。
AES
l 因为des算法不够安全了,所以出现了AES,AES适合于高速网络,适合在硬件上实现
l 密钥长度可以为128bit,192bit,或者256bit(还能以32bit的倍数扩展)。
l 软硬件运行效率较高,AES可用于无线/语言视频加密
RC系列
包括RC2、RC4、RC5,其中最常用的是RC4
RC4是基于流模式加密算法,面向bit操作,应用范围很广,比如https、WEP、WPA。
WPA2用的AES算法。
轻量级加密算法,运行速度快,对加密硬件要求低,以后可能会用到物联网的一些硬件设备上。
IDEA
类似于DES,IDEA算法也是一种数据块加密算法,它设计了一系列加密轮次,每轮加密都使用从完整的加密密钥中生成的一个子密钥。与DES的不同处在于,它采用软件实现和采用硬件实现同样快速。速度都比des快。
Blowfish
Blowfish是一个对称加密块算法,由Bruce Schneider于1993年设计,现已应用在多种加密产品。Blowfish能保证很好的加密速度,并且目前为止没有发现有效地破解方法。
易于软件快速实现,所需存储空间不到5KB,适用于密钥不经常改变的加密,比如监测水质的设备,可能放到水中三五年不便,就可以用Blowfish。
国密算法
SM1、SM2算法,都是对称算法,但是不能出口,一般用到国家政务、警务通等领域
非对称加密算法
两支对应密钥,称为公钥和私钥,一般是公钥加密私钥解密。
签名一般是私钥签名,公钥验签。
加解密过程
同学A产生明文->使用同学B的公钥加密成密文->通过网络传输到同学B->通过同学B的私钥解密->同学B得到明文
同学B的私钥始终保存在B的本地,且公钥不能推导出私钥,所以即使密文被截获,也是很难被解密的,安全的。
非对称加密算法的特点
加密速度非常慢,密文非紧凑的,
公钥和私钥不相同,通过私钥可以推导出公钥但是不能通过公钥推导出私钥。
三种用途:
加密解密
数字签名:保证信息的不可否认性
密钥交换:双方协商会话密钥
常用算法:
RSA算法:支持上面所说的三种用途
DH算法:只支持密钥交换
DSA算法:只支持数字签名
DH算法
解决对称加密算法中密钥分发的问题:前面提到对称算法中密钥交换的过程必须用安全通道交换,但是很难能做到真正的安全通道,DH算法就可以解决这个问题。
算法过程:
第一步:同学A和同学B两个人各自生成自己的DH公私钥,私钥自己保存,公钥发送给对方。
第二步:同学A用同学B的公钥和自己的私钥通过DH算法生成一个key,同学B同理生成一个key,最终AB同学生成的key应该是一样的,这样就实现了密钥的交换。
这样即使公钥在传输过程中被截获了,但是并不能从截获到的公钥推导出key。
RSA算法
密钥长度在512-4096bit之间
RSA比用软件实现的DES慢100倍
RSA比用硬件实现的DES慢1000倍
RSA的主要功能:加密、数字签名和密钥交换
其他公钥算法
Elgamal:DH的一种变形
椭圆曲线加密算法(ECC):原理是给定椭圆曲线上两个点A和B,如A=kB,要找到整数k非常困难,比特币底层就是用的这种算法。ECC密钥更小,与1024位的RSA密钥具有同样安全的ECC密钥只有160位
数字签名
RSA可以提供数字签名功能,提供认证和抗抵赖。
私钥加密的过程:
同学A生成明文->通过发送方的私钥加密成密文->通过网络传给B->B拿到密文用A同学的公钥解密->得到明文
通过这个过程,B可以用A的公钥解密开密文,就表示这段密文就是A发送的,A就不能抵赖了。
数字签名过程:
- 发送方A生成明文
- 用接收方B的公钥加密这段明文,生成密文。同时对明文信息进行哈希计算,得到摘要,将摘要用发送方A的私钥进行签名,得到签名值。
- 通过网络将密文和签名值发送给接收方B
- B收到密文和签名后,首先将密文用自己的私钥解密,得到明文。然后对明文进行哈希,得到一个哈希值,也就是上面说的摘要
- 接下来,B继续对A发来的签名,用发送方的公钥进行解密,得到一个摘要
- 最后接收方B将两个摘要进行对比,如果一样,就说明消息是A发的并且中途没有被篡改。
上面这段可以理解数字签名的过程,但是真实使用过程中,并不会使用公钥加密,一般对明文加密用的还是对称算法,可以保证速度,后面会讲到,如何将对称和非对称算法结合使用。
hash算法:无论多长的明文数据,经过hash后,得到的都是一段定长的128或者256字节数据,同一段明文对应同一个hash值,并且算法不可逆,即不能通过摘要值逆算出明文,所以这里既能保证速度,又可以保证安全。
数字证书与CA
首先,从上面那些加密过程中提出一个问题:发送方A将明文加密的时候,如果判断使用的加密公钥就是接收方B的,而不是其他什么人的呢?
这里就引出了CA机构。
CA机构:颁发数字证书的机构,作为电子商务交易中受信任的第三方,承担公钥体系中公钥的合法性检验的责任。CA中心(GlobalSign)为每个使用公开密钥的用户发放一个数字证书,数字证书的作用是证明证书中列出的用户合法拥有证书中列出的公开密钥。
也就是说,CA机构给了用户B一个数字证书,数字证书中包含用户B的信息、公钥以及认证有效期等,类似网络上的SFZ。
哈希与HMAC
哈希Hash(散列函数)
将一段任意长的数据,经过计算,得到一段定长数据。
hash算法有几个特点:
l 不可逆:几乎无法从得到的hash结果值,推导出原文
l 无碰撞:两段不一样的原文,几乎不可能得到一个同样的hash值。
l 雪崩效应:原文有轻微的变化,得到的hash值会产生巨大变化
使用场景:
l 发布文件的完整性(比如下载一个炒股软件,该软件会给你一个MD值,下载成功后的MD5值和软件告诉你的一样,说明下载过程没有问题)
l 服务器中保存用户密码
l 数字签名
hash算法有很多,常用的有MD5,SHA256
用户密码的存储:
|
用户名 |
密码 |
|
test |
123456 |
明文存储的情况下:
哈希存储:
|
用户名 |
密码 |
|
test |
e10adc3949ba59abbe56e057f20f883e |
盐+哈希:
|
用户名 |
盐 |
密码 |
|
test |
2020-2-2 12:12:00 |
74acf6b6ef47772151b4b4666bde6c8c |
密码用明文存储,如果你的数据库被攻击,那么密码直接就被盗走了,但是将密码哈希过后再存储,即使密码被盗走了也不会有问题了。那么为什么又会有第三种存储方式?
这里首先有一个概念叫彩虹表攻击,彩虹表是一个预先准备好的表,表的内容就是一些有限字符组成的固定长度的纯文本密码对应的hash值,类似下面这样的表,表的内容能达到100G以上,这样就可以逆向的通过密码的hash找到密码的原文了。
|
密码 |
密码经过MD5算法hash后 |
|
123456 |
e10adc3949ba59abbe56e057f20f883e |
|
432432 |
d9aeba5e7bcdacec33d2504cfcbfc33b |
为了防止彩虹表攻击,就对hash的明文稍微改了一下,将密码和盐一起hash加密,盐可以是一个时间,也可以是别的什么值,
HMAC
HMAC是一种基于Hash函数和密钥进行消息认证的方法
具体说就是增加一个key做hash:HMAC=Hash(文件+key)
这个key是双方预先都知道的。
HMAC:可以做源认证以及完整性校验,具体如下
同学A 发起认证->到PPPOE服务端->服务端查到有保存同学A的用户名和密码,返回随机数x->同学A用自己的密码和随机数x做hash,将hash值发回给服务器->服务器同样做hash,之后比对验证。
为什么要返回一个随机数x,用随机数x和密码一起做哈希,还是和上面说的一样,防止彩虹表攻击。
对称加密和非对称加密结合使用
l 在对称算法中有些问题,比如如何将同学A的密钥传递给同学B,不能做数字签名等
l 非对称算法中也有问题,比如加密速度慢,密文非紧凑。
因为这些优缺点,我们应该想到,如何将优点结合起来使用呢?可以这样:
使用对称加密算法,对大文件进行加密,使用非对称加密算法对对称算法使用的密钥进行加密。
流程:
1、同学A 对明文进行哈希,形成摘要->利用发送方A的私钥,对摘要进行签名,得到发送方签名值
2、将明文+ 签名+发送方A的公钥或者数字证书打包起来,使用一个随机对称密钥,对其加密(这里使用的就是对称加密算法),得到密文
3、用接收方B的公钥对第二步中的随机对称密钥加密,得到密钥密文,将上一步的密文和本步骤的密钥密文打包,形成数字信封,发送给接收方B
4、B得到了两个密文,一个是密钥密文,一个是第2步骤的密文。使用接收方B的私钥对密钥密文进行解密,得到密钥。
5、使用解开的密钥对第2步骤的密文进行解密。解密得到了3个东西:一个明文,一个发送方A的签名,一个发送方A的公钥或者数字证书。
6、对上一步骤得到的明文进行hash计算,得到摘要。用发送方A的公钥对发送方A的签名进行解密,得到密文中的摘要,将两个摘要进行比对。结果一样就说明确实是发送方A发的。
比特币
区块链层次与架构
|
层次 |
主要用到的技术 |
|
应用层 |
|
|
合约层 |
|
|
激励层 |
|
|
共识层 |
通过各种共识算法,达到共识。常用的: PoW(工作量证明)Pos(权益证明)DPOS(股份授权证明) |
|
网络层 |
P2P技术 |
|
数据层 |
密码学技术(公钥密码学) |
下三层 数据层、网络层、共识层是区块链的核心,上三层就是应用层。
比特币和区块链的关系
区块链是一种技术的集合/思想(去中心化),比特币是基于区块链的一种应用(移动互联网与微信的关系)
比如互联网,最早就是诞生了web等应用,后面又出现qq,微信,淘宝等,从只能传输文字,到传输语音,位置等。区块链也是一样,目前区块链交易信息是比特币,但是也可以封装其他的内容,将来会有各种应用,目前最牛的只有比特币,其次以太坊。
中心化:
目前我们做交易,所有人的所有的交易都需要通过银行,比如转账,消费等;央行可以无穷无尽印钞票,导致通货膨胀;银行可以随意冻结/没收你的资产。所以银行就是一个中心化产物。去中心化就是交易过程脱离银行,完全个人对个人。
比特币就是一个完全脱离银行,只依靠互联网运行的货币系统,即使政府执法部门,也无法查封或没收比特币。比特币在人类历史上第一次用技术手段保证了私有财产神圣不可侵犯。
比特币的共识机制:
POW工作量证明:简单讲就是谁干的活多谁说了算
算法:
非对称密码学
比特币的特性:
硬通货:跨境交易(包括暗网的一些黄赌毒交易,以及正常的跨境支付汇款等)
易携带:只需要一个私钥
隐秘性:只暴露钱包地址;非法用途
无货币超发:货币紧缩(只有固定数量的比特币,不会超发)
P2P网络
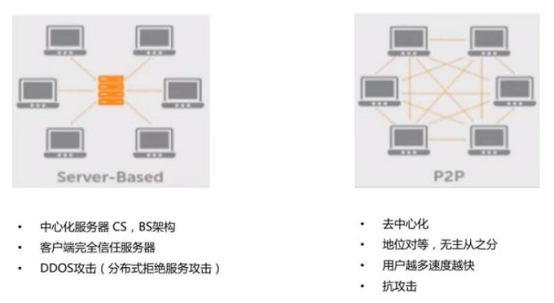
深入理解区块链结构
区块链分为区块和链两部分
区块里面包括一笔一笔的交易,然后将一个一个区块链接起来,形成链式结构。
比特币的区块里面封装的是交易信息,比如转账金额,收款人等;区块链还可以封装各种信息,如证件、私人记录、实物资产、留存证明等。封装交易信息形成了比特币应用,封装其他的信息就可以形成其他应用。
比特币结构:

每个区块包含一个区块头部和N个交易。
区块头部包含:上面那个图中的版本号,父区块哈希,Merkle树根,时间戳,难度值,Nonce
版本号:比特币的版本
父区块哈希:区块0的哈希值
Merkle树根:区块链非常重要的数据结构,也是一个哈希
难度值:确保区块链不会被很快挖出来,目前是约10分钟出来一个区块
时间戳:什么时间生成的区块
Nonce:随机数,挖矿就是找到随机数的过程
上面都是简单说明一下,后面有重点讲解,
比特币常用术语
去中心化的账本管理方式

每个人都有一个自己的账本,当李四跟张三转账,比如100元,首先形成一个交易信息,然后将这个交易信息记录到每个人的账本上,所有人的账本自始至终是一致的。这个账本取代了银行记账的方式。
挖矿
比特币矿工通过解决具有一定工作量的工作量证明机制问题,来管理比特币网络—确认交易并且防止双重支付。挖矿的过程就是在全网中和其他节点竞争记账的过程,为什么要竞争记账呢?比如上面那张图,转账完毕,每个人都要记账,那么第一个记账的人就可以得到一些比特币,所以第一个记账的人就等于挖到了矿。
百度百科:矿工们在挖矿过程中会得到两种类型的奖励:创建新区块的新币奖励,以及区块中所含交易的交易费。为了得到这些奖励,矿工们争相完成一种基于加密哈希算法的数学难题,也就是利用比特币挖矿机进行哈希算法的计算,这需要强大的计算能力,计算过程多少,计算结果好坏作为矿工的计算工作量的证明,被称为“工作量证明”。该算法的竞争机制以及获胜者有权在区块链上进行交易记录的机制,这二者保障了比特币的安全
除了上面说的奖励,还会获得相应权利和义务:记账的权利(把交易记录到账本)和广播义务(将区块全网广播)
创世区块
Block #0 2009.01.03诞生
区块高度:
就是从#0、#1、 #2一直加,增加的区块数
区块深度
比如产生一个交易,开始一段时间深度为0,交易可以更改/撤销(退换货),隔一段时间,深度或逐渐加深,深度大于6的时候,交易就达到了非常安全的程度,不可再更改/撤销.
深度是以产生交易的区块为起点,比如在第10个区块产生了这笔交易,那么第10个区块就是深度1,第11个区块产生出来后就是深度2,第12个区块就是深度3,以此类催,达到深度6,也就是创建出来第16个区块后,交易就不可更改了。
交易确认
当一项交易被区块链收录后,就是交易确认
在此区款连之后每产生一个区块,此项交易的确认数相应加1
比特币钱包对交易确认数有相应设置(快速2次确认,非常安全6次确认收到钱)
UTXO 未花费的交易输出
我们都知道比特币是虚拟的,本质上就是一串代码。而记录比特币交易的账户模型,就是UTXO。比特币系统中没有比特币,只有UTXO,即系统中没有保存谁有几个比特币,而是记录的一笔一笔的交易,比如A给B转了100元,那么区块中就多出两笔交易,一笔是A减少100元,一笔是B增加100元。每一笔交易后的输出就是一个UTXO。
举个例子,假如我们现在钱包里有100块钱,你要花5块钱,然后找零95块。当你拿出来100块大洋花出去的时候,这100块就已经不能再算作UTXO,只有找零得到的95块,才会算作UTXO。
每笔交易都有若干交易输入,也就是资金来源,也都有若干笔交易输出,也就是资金去向。一般来说,每一笔交易都要花费(spend)一笔输入,产生一笔输出,而其所产生的输出,就是“未花费过的交易输出”,也就是 UTXO。当之前的 UTXO 出现在后续交易的输入时,就表示这个 UTXO 已经花费掉了,不再是 UTXO 了。
比特币存在比特币钱包中,比特币钱包中的比特币是怎么来的呢?是将一笔一笔的交易数加起来,比如A同学先增加了200,又减少了100,又增加了300,那么他的比特币数量就是200-100+300=400
比特币系统中没有账户这个概念,也没有账户余额的概念,只有UTXO(被公钥锁定),没有登录概念,只要自己有私钥就可以使用这个比特币。
转账将消耗掉你自己的UTXO,同时生成新的UTXO,用接收UTXO方的公钥进行锁定。
另外还要提一下,UTXO与传统的账户系统有什么区别。假如有两个人,一个是小明,一个是小美。小明要给小美转100块钱。那么传统的账户模型是这样的:先判断小明账户里是否有100块的余额,然后在小明的账户里减少100块,在小美账户里增加100块。
但UTXO的机制是这样的:小明的账户里有200块钱,他要想给小美转账,必须将200块钱全部消耗掉。所以他不仅要给小美转100块,还要给自己账户转100块。这样一个好处就是,如果从第一个区块开始逐步计算所有比特币地址中的余额,就可以计算出不同时间的各个比特币账户的余额了
比特币交易锁定与解锁全过程
交易的输出(UTXO),包含两个东西:
l 锁定的比特币数量
l 锁定脚本(用接受者公钥的哈希)
只要接收者才能有权利花费这笔比特币,所以用接收者的公钥进行锁定,但是为了更安全,比特币是用的公钥的哈希值加密的这笔比特币。
交易的输入(UTXO+解锁脚本)
l 解锁脚本(签名和发送者公钥)
比特币锁定/解锁脚本工作过程

B打算向C转10个比特币,怎么判断B有权利花掉这10个比特币?
第一步,判断锁定脚本:B会提供一个B私钥签名和一个B公钥,系统将B公钥进行hash,和锁定脚本那种的B公钥哈希如果相同,就证明B提供的确实是B的公钥。
第二步,用B的公钥解B的私钥签名,如果能解开,就证明确实是B的私钥做的签名,B确实有私钥。
再举一个例子,下面这个例子,假设交易手续费为0:
1、用户A挖矿获得了12.5BTC
这里的12.5btc UTXO用旷工A的公钥哈希进行锁定(加密)
注意:刚挖到的比特币要100个区块确认后才能花。
2、第一个交易:A向B和C各转5 BTC
B多了5 BTC的TUXO,用B的公钥哈希进行锁定
C多了5 BTC的UTXO,用C的公钥哈希进行锁定
A去掉原来有的12.5的UTXO,换成2.5的UTXO,用A的公钥哈希进行锁定
3、第二个交易:B向C转2个BTC
B去掉原来的5 BTC的UYXO,改成3BTC的UTXO,仍然用B的公钥哈希进行加密锁定
C多一个2 BTC的UTXO
4、第四个交易 :C向B转6 BTC
C转给B之前有一个5BTC,一个2BTC,要给B 6BTC,就会将原来的5和2BTC的UTXO全部删掉,换成1BTC的UTXO用C的公钥哈希加密和6BTC
以及给B的6BTC的UTXO用B的公钥哈希加密
经过上面一些交易,最后剩下的UTXO,就只有步骤2中A的2.5BTC,步骤3中B的3BTC和步骤4中B的6BTC以及C的1BTC。此时比特币的总和依然是最开始旷工A挖矿挖出来的12.5。
交易的传播与验证
交易
交易包含两部分:输入n和输出m。n>=0,m>0
输入:要被花费的UTXO+解锁脚本(私钥签名+公钥)
输出:一个或多个UTXO(币值+锁定脚本(公钥的哈希))
n>=0怎么理解呢?第一笔交易,例如上面那个例子中的旷工A,挖矿得到奖励,是没有输入的,只有输出,此时就是n=0的情况。其他的交易都是n>0的情况,你要花钱首先得有钱。所以除了第一笔那样的交易,其他的交易都包含两部分,输入和输出。
m>0:输出就是你买东西或者转账等,给人家钱,不可能给0
交易传播与验证过程:
- 钱包软件生成交易,并向邻居节点传播
- 节点对收到的交易进行验证,并丢弃不合法交易
- 交易的size要小于区块size的上限
- 交易输入的UTXO是存在的(向全节点的UTXO数据库检索)
- 交易输入的UTXO没有被其他交易引用,防止双花
- 输入的总金额>=输出总金额
- 验证解锁脚本
- 将合法的交易加入本地Transaction数据库中,并发送给临近节点。
区块的生成与连接
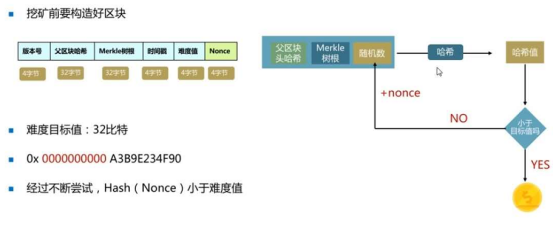
旷工在挖矿前要组件区块
1、将coinbase交易打包进区块(每个区块的第一笔交易都是这个,旷工挖矿挖来的12.5BTC)
2、将交易池中高优先级的交易打包进区块
优先级:交易额度*UTXO深度/交易size(类比银行)
交易size:防止粉尘攻击(类似银行的存款期限,存起来不经常动,size就小)
UTXO深度:防止频繁转账攻击(很久没有转账的深度更大,转账越频繁的深度越小)
创建区块头部

区块链:
区块0--区块1--区块2--区块3.。。。
区块1的父区块哈希是区块0的区块哈希
区块2的父区块哈希是区块2的区块哈希
。。。
这样一来只要中间有一个交易信息改变,会导致他后面的所有区块都要变。
算出随机数Nonce,意味着挖矿成功,之后将计算出来的随机数nonce填入区块头部,向邻近节点传播(接力赛)
区块0存储的信息:
当时正是英国财政大臣第二次出手疏解银行危机之时,表示对中心化银行和政府的不满。
相邻节点收到新区块后,立即做如下检查:
验证POW的nonce值是否符合难度值
检查时间戳是否小于当前时间2小时
检查Merkle树根是否正确
检查区块size要小于区块size上限
第一笔交易必须是coinbase交易
验证每个交易
比特币代码网站:http://btc.yt/lxr/satoshi/ident?_i=CheckBlock
二叉树与Merkle树
树:由多个节点组成的一种数据结构,每个节点存储数据,节点包括:根节点、父节点、子节点、兄弟节点
特殊树:二叉树(方便查找)
比如有数据:12、5、2、18、19、15、17、16、9
如下图,第一个数12,放到顶端;5小于12,放到左边,2小于12,到左边,小于5,放到5的左边,18大于12,放右边,19大于12,大于18,放18右边。。。
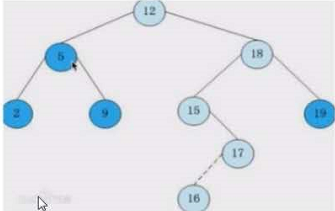
Merkle树作用
防止数据篡改(节点存储Hash值)
快速验证某个交易是否存在
从叶子节点构造树
Merkle树存储的是交易信息的哈希,比如现在有三笔交易信息:a、b、c,将这三笔交易做哈希得到Ha、Hb、Hc,就会如图中所示,将Ha和Hb再次哈希,生成Hab,因为没有Hd,所以将Hc和Hc做哈希,生成Hcc,然后再将Hab和Hcc哈希,生成根节点。
如何防止数据篡改的?任何一个交易的改变,交易的哈希就会改变,那么上层所有的哈希都会变,比如Ha改变了,那么Hab也会改变,root也会变。所以只要根节点哈希值没变,和头部的Merkle树根一致,那么就可以保证交易都没有被篡改。

怎么验证区块是否在交易里面?
比如a那笔交易是张三给李四转钱的交易,如何验证这笔交易在这个区块里,就用a这笔交易的哈希Ha跟他兄弟节点Hb做哈希,得到Hab,再用Hab和他兄弟节点Hcc做哈希,得到根节点,判断根节点和头部的Merkle树根一致,就说明这个交易在这个区块中。
root就是头部的Merkle树根,Merkle树根是负责一个区块内部的所有交易的hash,父区块哈希是区块和区块之间的hash。父区块哈希是防止整个区块被篡改。
比特币存在的问题
比特币网络拥堵
跟P2P没有关系,跟底层区块链有关系,因为区块每10分钟生成一个导致的。每10分钟就会有一个新的区块被“挖掘”出来,每个区块里包含着从上一个区块产生到目前这段时间内发生的所有交易,这些交易被依次添加到区块链中。由于每次矿工在打包新区块时,最多也就能打包几千条交易信息。所以以前交易量没那么多时,一般等到下一个区块打包完,就能到账了,也就是10分钟左右就到账了;但是一旦交易量上去了,那么对不起,这次甚至下次打包新区块时,估计都不能打包上这笔新交易了。因为前面还有好多交易都在排着队等着被打包被验证呢!
为什么一个区块最多只能打包几千条信息?
现在一个区块的大小差不多是1MB,也就是1000KB,可以把一个区块比做一个书包的大小。一笔交易差不多是250B,也就是0.25KB,可以把一笔交易比做一根铅笔的大小。现在要往1000KB的书包里放0.25KB的铅笔,能放多少根笔?不难算出,是4000根:
即,一个区块,最多也就包含差不多4000笔交易。
交易费用昂贵
交易费用给的高,会被优先处理,因为网络拥堵,速度慢,交易费用也会更高
以太坊的出现,也会成为比特币发展的阻碍
因为有上面的这些问题,所以目前正在考虑比特币扩容
比特币扩容
有人会问:书包太小了,换个大书包吧!
也有人会说:交易能不能压缩一下啊,铅笔再小一点!
没错,这些都是解决目前交易拥堵的方式。即:
1.扩大区块的大小,从1MB提升到2MB甚至4MB甚至更大。
2.交易压缩,将没用的信息去掉,节约每笔交易的空间,好让区块里能存放更多的交易。
对于第一个解决方案,扩大区块大小,从几年前起,比特币社区、矿场、比特币主要核心开发人员之间就开始讨论了。吴忌寒等旷工团队主张扩容,但核心开发人员反对将区块扩容。
对于第二个解决方案,人们确实找到了可以压缩交易的方法,压缩的方式有两种:
1)存储一半的公钥。
这是因为私钥在生成公钥时,采用的是椭圆曲线加密法,最开始人们都没当回事,后来受交易拥堵的影响,有人关注到,因为是椭圆算法的,所以是对称的,所以只需要存储一半的公钥,就能表达出之前的意思,这样既没有什么影响,又能节省空间,让一个区块包含更多的交易,何乐而不为?于是大家就开始接受压缩公钥的方式了。
2)隔离见证,即将一笔交易的交易部分和签名部分拆开。
开发者们发现,一笔0.25KB的交易记录中,实际交易信息占了一小部分,还有一部分叫做签名信息,这签名信息占了一大部分,于是开发者们把签名信息从交易记录中剥离出去,单独开发了一块空间存储签名信息。于是之前一个区块里包含了众多交易的交易信息和签名信息,现在一个区块里只需要包含这些交易记录的交易信息就好了,签名信息在另一个附属的块中捆绑在区块上,一并发给其他矿工。这样的话,也能节省出来一部分空间。
针对隔离见证,旷工和核心开发团队们有过两次共识,第一次共识,是2016年2月在香港的会议,称为香港共识:Core团队的代表同意在实施隔离见证后,区块大小扩容到2M。(前提是95%以上的算力旷工支持)
第二次共识,2017年5月的纽约会议,称为纽约共识:全网80%算力的矿主达成Segwit(隔离见证)2x扩容,意思是只要80%以上的矿主同意扩容,就将区块大小扩容到2M。
BIP:意思是比特币改进建议,针对扩容就搞了如下几个BIP:
BIP141(95%支持就实施)+BIP 91(80%支持即可)+BIP102(升级到2M)
这里就看出去中心化的一点缺点:没有中心,没有权威,大家都可以说话,意见统一起来就很困难,就比如这次扩容,搞了三个BIP,来回开会,才有一点结论出来。
Core团队反对扩容区块的原因:
- 不愿意轻易更改系统,比如银行仍使用COBOK语言编写的系统
- 防止个人不能运行全节点,因为每个区块太大了,总体容易激增(违背去中心化)
- 增加到2M没太大作用,主推 闪电网络/侧链 解决交易拥堵
闪电网络/侧链 :闪电网络的主要思路十分简单 -- 将大量交易放到比特币区块链之外进行。核心的概念主要有两个:RSMC(Recoverable Sequence Maturity Contract)和 HTLC(Hashed Timelock Contract)。前者解决了链下交易的确认问题,后者解决了支付通道的问题。
简单说一些交易没必要上主网络,在链下解决就足够了。中心化和去中心化结合。
旷工反对的原因
- 闪电网络将会导致交易中心化,违背比特币点对点交易的初衷
- 闪电网络属于BlockStream公司,大多数Core团队成员是BlockStream雇员。
- 如果将来绝大部分交易都在闪电网络/侧链,旷工会损失交易费
- Core垄断了海外论坛,利用社区影响力封杀反对core的开发者和社区成员
BCC分叉
因为上面的一些原因,就有人搞出来比特币的分叉,目前主要有BU团队,BitcoinABC团队。
BU团队:
比特币无限大小:放开区块大小限制,一次能处理足够的数据,提升网效率
BU方案曾经获得全网40%算力支持
代码BUG太多,未能获得社区广泛支持
BitcoinABC团队,团队成员还是来自BU团队:
基于BU代码,打造了BCC,2017.08.01执行硬分叉(ViaBTC推动)
BCC没有Segwit,区块容量8M
BCC官网:https://www.bitcoincash.org
比特币分叉
针对扩容有两种解决方案:软分叉(修辅路、侧链),硬分叉(重新修条更宽的路)
软分叉:
是在原来基础上进行优化,将区块提高到2M,8M,16M,以SegWit闪电网络未主流解决方案。链上的一部分升级到软分叉后,即使有些没有升级的,可以互相兼容,最终还是在一条链上。
硬分叉:
通过升级系统,改变代码,彻底解决扩容问题,以BU为主流解决方案。不能兼容以前的方案。所以这个链会分成两个链,BTC/BCH,ETC/ETH.
扩容是指硬分叉,隔离见证指的是软分叉。
比特币和以太坊都进行了硬分叉。BTC BCH ETC ETH
莱特币 利用隔离见证进行软分叉
临时分叉:
- 仅发生在几乎同时爆块(同时找到满足条件的随机数)的情况,这种分叉是暂时的
- 链分叉后,继续挖矿,挖着挖着就会出现有一个链长一个链段的情况。根据共识机制,旷工最终会切换到最长链上继续挖矿
- 短链上的交易全部无效,爆块旷工费(旷工费无效)
- 短链上的旷工就重新到长链上继续挖矿
比特币的三个地址
私钥地址
私钥地址可以产生公钥和比特币地址
只需要保存私钥,就能够花费对应地址上的比特币
私钥的本质是随机数(比特币私钥256位)
私钥总数是2256,数据量超过了宇宙中原子总数,很难遍历所有私钥。
比特币私钥是安全的,并不是说不可能出现重复的私钥,而是说不可能通过遍历的方式找到某一个特定的私钥。
比特币私钥地址WIF(Wallet Import Format)
私钥的格式:
私钥前缀80+私钥本体+后缀(压缩私钥后缀是01,非压缩私钥无后缀)+校验
压缩私钥 (76位十六进制 2+64+2+8) <=>(52位Base58):

非压缩私钥 (74位十六进制 2+64+8) <=>(51位Base58):

如何生成WIF私钥:
第一步,随机选取一个32字节的数、大小介于1 ~ 0xFFFF FFFF FFFF FFFF FFFF FFFF FFFF FFFE BAAE DCE6 AF48 A03B BFD2 5E8C D036 4141之间,作为私钥。
private_key= bytes.fromhex('0C28FCA386C7A227600B2FE50B7CAE11EC86D3BF1FBE471BE89827E19D72AA1D01')
第二步,添加前缀0x80
rk = b'\x80' + private_key
第三步,取两次哈希的前4个字节(8位十六进制),作为校验值添加在后面
checksum = hashlib.sha256(hashlib.sha256(rk).digest()).digest()[0:4]
rk = rk + checksum
最后用Base58表示法转换一下
return base58.b58encode(rk)
如果运算正确,得出的私钥值应该是:
KwdMAjGmerYanjeui5SHS7JkmpZvVipYvB2LJGU1ZxJwYvP98617
第一步的64字符是标准格式私钥256bit,64个字符。
WIF格式私钥更短,是经过Base58编码得到的,叫作压缩格式私钥,以K或L开头,大小是52个字符。
未压缩格式私钥:5开头,大小51个字符
生成自己私钥的方法:
- 通过某些私钥生成网站,会存在安全性问题
- 掷骰子,16面的扔64次
- 用中文,英文,或汉语拼音的哈希值
- http://www.fileformat.info/tool/hash.htm
公钥地址
是由私钥,通过椭圆曲线加密算法(ECC)生成,是一个65byte数组
压缩公钥是02或03开头66位(2+64):

非压缩公钥是04开头130位十六进制(2+64+64):

注意它们的第二行内容完全一样
公钥的生成:
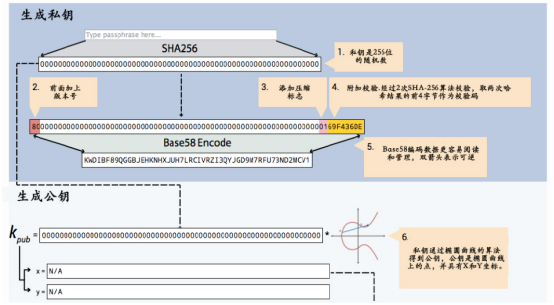
钱包地址
钱包地址的生成过程:

1、3935a3e3751b68e04(自己随机产生一个数)(或者是生成一个助记词)
2、填充,得到256bit的私钥(private_key):
000000000000000000000000000000000000000000000003935a3e3751b68e04
3、对私钥进行椭圆曲线算法加密(SECP256k1),得到64字节的公钥(public_key):
e8977d298d194929e92b1a87a37f232f8838aaa3e14746217c46def324d7577ca273075eb4edb98c18a6e27c4549aca44620aef4567bfb35d942e7ba0edce75f
4、添加0x04头(以0x04开头的公钥标记这是没有经过压缩的公钥),长度变为65字节:
04e8977d298d194929e92b1a87a37f232f8838aaa3e14746217c46def324d7577ca273075eb4edb98c18a6e27c4549aca44620aef4567bfb35d942e7ba0edce75f
5、对步骤4的公钥作sha256哈希加密,得到如下摘要(长度为32字节):
ac40cc78422db4050f1a99c2e539a68eca62b8c8c3496c330d588d2ed794e140
6、对步骤5的数据作ripemd160哈希加密,得到公钥hash(长度20字节):
e2d12b1c117fe64cb868a81ee3a61c74b64c59ed
以下步骤展示公钥hash生成钱包地址的过程:
7.1、假设 tem_hash = SHA256( SHA256(0x00+公钥hash) ), 取tem_hash前4个字节:f3891721
7.2、 checksum = f3891721
7.3、 0x00 + 公钥hash + checksum:
00c8db639c24f6dc026378225e40459ba8a9e54d1af3891721
7.4、将7.3中的字节流进行base58的转换,得到钱包地址:
1MgJHdTuHkyZ6gzzMQGkZHd4CPn6joU5GL
注:钱包地址与公钥hash从转换来看,完全可以互逆,所以大部分情形下二者是等价的,只是表现形式不一样而已。
轻钱包
轻钱包是比特币的非全节点,存储空间有限,只存储区块的头部,空间只有80字节,区块本身大小:1M,8M
SPV简单支付验证(Simplified Payment Verification),这个概念出现其实很简单,以比特币为例子,目前节点如果存储完整的区块链数据那么有几百G,一般的个人终端上无法满足这个量级的存储空间,而且这个数据量还会一直增加,那么针对个人的终端需要一种简单的验证模式,相应就出现了SPV,比如MultiBit这种轻量级钱包用的就是SPV模式。
轻钱包只存储区块头部,不存储区块信息,但是UTXO在区块内,所以如果想要交易,必须向邻近的全节点的区块链发送交易信息。
轻钱包的SPV验证
当SPV节点收到一个交易请求,其实节点是无法证实对端节点的可靠性的,那么在一个交易发起过程中,一般会包括对端节点的支付UTXO、对端节点的签名、交易金额、SPV节点的地址。SPV节点验证通过支付验证,检查区块头信息来确认发生这个交易的是否在区块链中,并且在当前的区块链系统中有多少区块进行确认。这里啰嗦下区块头,区块头中包括prev_block_hash和merkle_root_hash这两个最为重要的验证值。
1.SPV节点通过getheaders从相邻的全数据节点获得区块头信息(这里涉及一个问题,SPV对特定的几个交易选择读取,无疑会透露钱包地址信息)
2.计算当前交易的HASH值。
3.用计算后后的HASH值,去比对定位block head,确定是否存在目前的最长一条链接上。
4.从区块中获取构建merkle tree 所需的hash值,并计算merkle_root_hash
5.计算结果如果一致说明交易真实存在。
6.根据block header来确认有多少区块确认交易。
什么是挖矿/矿池
挖矿:
以抛硬币为例:
正面朝上: 1
反面朝上: 0
立起来: X
谁抛出如下组合,奖励50比特币:
11110000XX11110000XXXXXXX0101010101X01X1010X..
利用电脑CPU跑程序计算,一秒抛2次,专用GPU显卡,一秒抛200次
单位时间抛硬币次数可以理解成算力,算力越大,抛中可能性越大。
挖矿就是寻找上面的组合的过程。
矿池
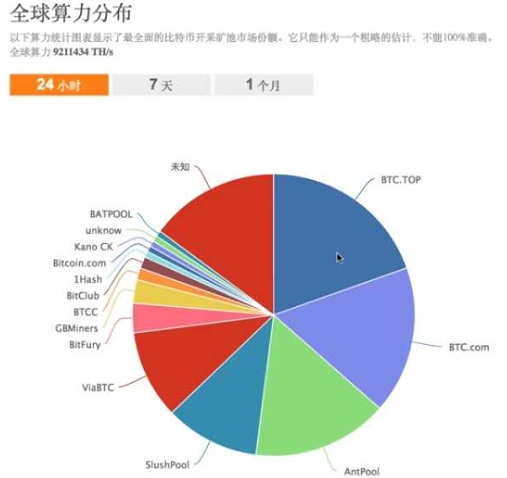
挖矿的本质:维护比特币网络,大家得记账,不能白记,得给奖励,最初奖励50个比特币,每4年减半。
比特币挖矿:消耗计算机+电力
黄金挖矿:消耗人力
挖矿底层机制
比特币系统里为什么要设计挖矿?
- 增加恶意行为的成本。比如黑客,想要挖矿,必须去购买很多大型设备
- 争夺记账权利,获取奖励(总共2100万枚比特币,都是靠挖矿来挖来的)
挖矿流程图
挖矿难度调整
- 每2016个区块调整难度
- 新目标值=当前目标值*(过去2016区块用时分钟/20160分钟)
- 目标值与难度值成反比(计算公式异常复杂)
区块链共识算法和激励机制
什么是区块链共识机制?
区块链具备:去中心化特性
没有类似银行的记账机构,全网节点怎么打成共识/一致?
- POW:通过评估你的工作量来决定你获得记账权的概率,算力越大,记账几率大 ---比特币
- POS:通过评估你持有代币数量和时长,决定你记账的几率 (币天)---点点币
不浪费电力 51%攻击更难
- POW+POS:用POW发行新币,用POS维护区块链网络安全
- DPOS:选定“人大代表”记账---EOS选21个根节点记账,委托选出来的这21个代表去记账,其他的人不能记。
比特币共识机制 工作量证明POW
怎么证明你英语好/网络牛人? CET6/CCIE证书
POW(Proof of Work)
- 通过付出大量的工作代价来证明自己是非恶意节点
- 计算出一个难题的随机数答案(nonce),如同掷骰子
- 获取记账权利
- 打包交易并通知其他节点
POS(Proof of Stake) 股权证明机制
- POS 根据你持有代币的量和时间(币天),给你发利息的一个制度
- 比如你持有100个币,总共持有了30天,那么,此时你的币天就为3000
- 如果你发现了一个POS区块,你的币天就会被清空为0
- 你每被清空365币天,你将会从区块中获得0.05个币的利息
- 假定利息可理解为年利率5%,利息 = 3000 * 5% / 365 = 0.41个币
问题:大股东控制,造成中心化。 人性: 有钱人犯罪率低
总结
- POW通过挖矿奖励,交易费激励大家维护比特币节点
- POS则由大股东负责维护区块链节点,产生利息
- DPOS选举“人大代表”记账,维护区块链
拜占庭将军问题
拜占庭将军问题(Byzantine failures),是由莱斯利·兰伯特(Leslie Lamport)提出的点对点通信中的基本问题。
拜占庭问题的最初描述是:n 个将军被分隔在不同的地方,忠诚的将军希望通过某种协议达成某个命令的一致(比如一起进攻或者一起后退)。但其中一些背叛的将军会通过发送错误的消息阻挠忠诚的将军达成命令上的一致。Lamport 证明了在将军总数大于3m ,背叛者为m 或者更少时,忠诚的将军可以达成命令上的一致。
背景:
- 拜占庭帝国派出10支军队,去包围一个强大的敌人
- 至少6支军队同时进攻才能攻下,不然会失败,损兵折将
难题:一些将军可能是叛徒,会发布假的(相反的)进攻意向
目的:将军需要找到一种共识机制,可以远程协商,一起进攻/不进攻
解决方案PBFT ( Practical Byzantine Fault Tolerance ,实用拜占庭容错算法)
- 每个节点向所有其他节点发送消息
- 每个节点根据收到的所有消息来决定最终的策略
- 缺点:每个节点向全网节点发送大量的消息,因为这个缺点,所以不适合在比特币世界里用,容易造成网络堵塞。
- 这个算法有解前提:n>=3m+1(n为将军总数,m为叛徒数量)
m<= ( n-1 )/3
整理了一下前段时间学习的区块链的视频内容,老师讲的挺好的,感觉确实理解了很多
加载全部内容