一条Sql的Spark之旅
starqiu 人气:1背景
SQL作为一门标准的、通用的、简单的DSL,在大数据分析中有着越来越重要的地位;Spark在批处理引擎领域当前也是处于绝对的地位,而Spark2.0中的SparkSQL也支持ANSI-SQL 2003标准。因此SparkSQL在大数据分析中的地位不言而喻。
本文将通过分析一条SQL在Spark中的解析执行过程来梳理SparkSQL执行的一个流程。
案例分析
代码
val spark = SparkSession.builder().appName("TestSql").master("local[*]").enableHiveSupport().getOrCreate()
val df = spark.sql("select sepal_length,class from origin_csvload.csv_iris_qx order by sepal_length limit 10 ")
df.show(3)我们在数仓中新建了一张表origin_csvload.csv_iris_qx,然后通过SparkSQL执行了一条SQL,由于整个过程由于是懒加载的,需要通过Terminal方法触发,此处我们选择show方法来触发。
源码分析
词法解析、语法解析以及分析
sql方法会执行以下3个重点:
sessionState.sqlParser.parsePlan(sqlText):将SQL字符串通过ANTLR解析成逻辑计划(Parsed Logical Plan)sparkSession.sessionState.executePlan(logicalPlan):执行逻辑计划,此处为懒加载,只新建QueryExecution实例,并不会触发实际动作。需要注意的是QueryExecution其实是包含了SQL解析执行的4个阶段计划(解析、分析、优化、执行)QueryExecution.assertAnalyzed():触发语法分析,得到分析计划(Analyzed Logical Plan)
def sql(sqlText: String): DataFrame = {
//1:Parsed Logical Plan
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = {
val qe = sparkSession.sessionState.executePlan(logicalPlan)/https://img.qb5200.com/download-x/d-1
qe.assertAnalyzed()/https://img.qb5200.com/download-x/d-2
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
}
/https://img.qb5200.com/download-x/d-1
def executePlan(plan: LogicalPlan): QueryExecution = new QueryExecution(sparkSession, plan)
//2:Analyzed Logical Plan
lazy val analyzed: LogicalPlansparkSession.sessionState.analyzer.executeAndCheck(logical)解析计划和分析计划
sql解析后计划如下:
== Parsed Logical Plan ==
'GlobalLimit 10
+- 'LocalLimit 10
+- 'Sort ['sepal_length ASC NULLS FIRST], true
+- 'Project ['sepal_length, 'class]
+- 'UnresolvedRelation `origin_csvload`.`csv_iris_qx`主要是将SQL一一对应地翻译成了catalyst的操作,此时数据表并没有被解析,只是简单地识别为表。而分析后的计划则包含了字段的位置、类型,表的具体类型(parquet)等信息。
== Analyzed Logical Plan ==
sepal_length: double, class: string
GlobalLimit 10
+- LocalLimit 10
+- Sort [sepal_length#0 ASC NULLS FIRST], true
+- Project [sepal_length#0, class#4]
+- SubqueryAlias `origin_csvload`.`csv_iris_qx`
+- Relation[sepal_length#0,sepal_width#1,petal_length#2,petal_width#3,class#4] parquet此处有个比较有意思的点,UnresolvedRelation origin_csvload.csv_iris_qx被翻译成了一个子查询别名,读取文件出来的数据注册成了一个表,这个是不必要的,后续的优化会消除这个子查询别名。
优化以及执行
以DataSet的show方法为例,show的方法调用链为showString->getRows->take->head->withAction,我们先来看看withAction方法:
def head(n: Int): Array[T] = withAction("head", limit(n).queryExecution)(collectFromPlan)
private def withAction[U](name: String, qe: QueryExecution)(action: SparkPlan => U) = {
val
result= SQLExecution.withNewExecutionId(sparkSession, qe) {
action(qe.executedPlan)
}
result
}withAction方法主要执行如下逻辑:
1. 拿到缓存的解析计划,使用遍历优化器执行解析计划,得到若干优化计划。
2. 获取第一个优化计划,遍历执行前优化获得物理执行计划,这是已经可以执行的计划了。
3. 执行物理计划,返回实际结果。至此,这条SQL之旅就结束了。
//3:Optimized Logical Plan,withCachedData为Analyzed Logical Plan,即缓存的变量analyzed
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
lazy val sparkPlan: SparkPlan = planner.plan(ReturnAnswer(optimizedPlan)).next()
//4:Physical Plan
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)优化计划及物理计划
优化后的计划如下,可以看到SubqueryAliases已经没有了。
== Optimized Logical Plan ==
GlobalLimit 10
+- LocalLimit 10
+- Sort [sepal_length#0 ASC NULLS FIRST], true
+- Project [sepal_length#0, class#4]
+- Relation[sepal_length#0,sepal_width#1,petal_length#2,petal_width#3,class#4] parquet具体的优化点如下图所示,行首有!表示优化的地方。
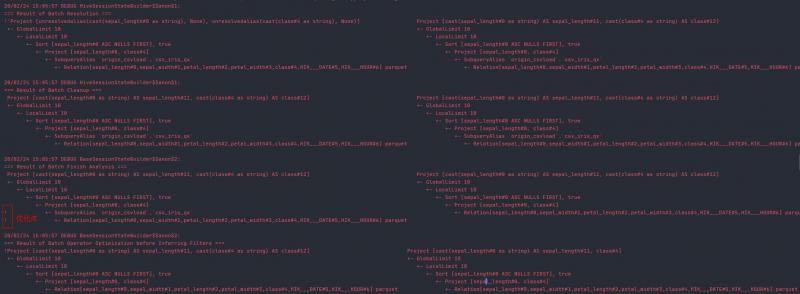
其中"=== Result of Batch Finish Analysis ==="表示"Finish Analysis"的规则簇(参见附录一)被应用成功,可以看到该规则簇中有一个消除子查询别名的规则EliminateSubqueryAliases
Batch("Finish Analysis", Once,
EliminateSubqueryAliases,
ReplaceExpressions,
ComputeCurrentTime,
GetCurrentDatabase(sessionCatalog),
RewriteDistinctAggregates)最后根据物理计划生成规则(附录二)可以得到物理计划,这就是已经可以执行的计划了。具体如下:
== Physical Plan ==
TakeOrderedAndProject(limit=10, orderBy=[sepal_length#0 ASC NULLS FIRST], output=[sepal_length#0,class#4])
+- *(1) Project [sepal_length#0, class#4]
+- *(1) FileScan parquet origin_csvload.csv_iris_qx[sepal_length#0,class#4] Batched: true, Format: Parquet, Location: CatalogFileIndex[hdfs:/https://img.qb5200.com/download-x/di124:8020/user/hive/warehouse/origin_csvload.db/csv_iris_qx], PartitionCount: 1, PartitionFilters: [], PushedFilters: [], ReadSchema: struct<sepal_length:double,class:string>总结
本文简述了一条SQL是如何从字符串经过词法解析、语法解析、规则优化等步骤转化成可执行的物理计划,最后以一个Terminal方法触发逻辑返回结果。本文可为后续SQL优化提供一定思路,之后可再详述具体的SQL优化原则。
附录一:优化方法
分析计划会依次应用如下优化:
- 前置优化。当前为空。
- 默认优化。主要有如下类别,每个类别分别有若干优化规则。
- Optimize Metadata Only Query
- Extract Python UDFs
- Prune File Source Table Partitions
- Parquet Schema Pruning
- Finish Analysis
- Union
- Subquery
- Replace Operators
- Aggregate
- Operator Optimizations
- Check Cartesian Products
- Decimal Optimizations
- Typed Filter Optimization
- LocalRelation
- OptimizeCodegen
- RewriteSubquery
- 后置优化。当前为空。
- 用户提供的优化。来自
experimentalMethods.extraOptimizations,当前也没有。
附录二:物理计划生成规则
生成物理执行计划的规则如下:
- PlanSubqueries
- EnsureRequirements
- CollapseCodegenStages
- ReuseExchange
- ReuseSubquery
本文由博客一文多发平台 OpenWrite 发布!
加载全部内容