drf序列化
辜老板 人气:0目录
- 序列化流程
- 内部类
- DRF响应类:Response
- 序列化基类控制接口参数
- 局部钩子
- 全局钩子
- read_only与write_only限制
- 小结
- 案例
- models.py:
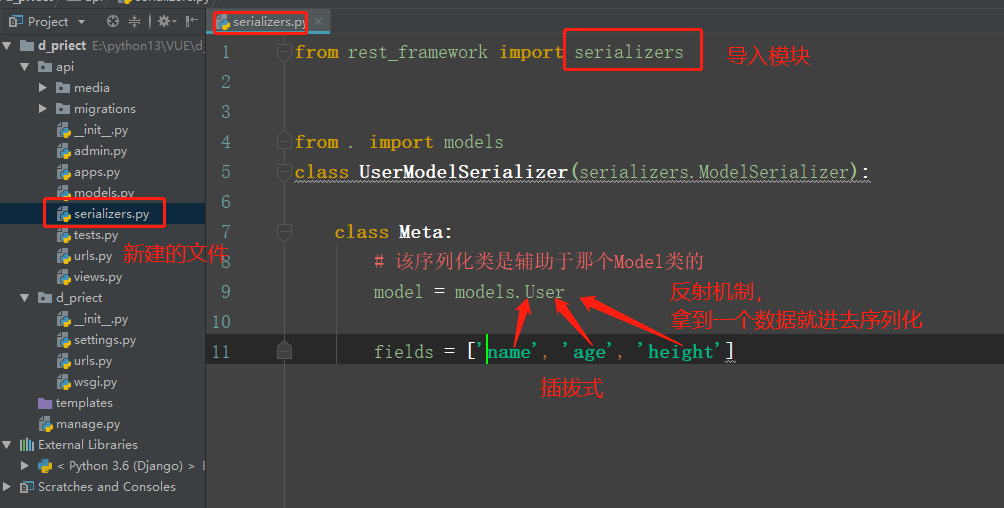
- serializers.py:
- views.py:单查群查单增
- 测试:
- 连表操作
- 配置图片和性别
序列化流程
"""
开发流程:
1)在model类中自定义 读字段,在serializer类中自定义 写字段
2)将model自带字段和所以自定义字段书写在fields中,用write_only和read_only区别model自带字段
3)可以写基础校验规则,也可以省略
4)制定局部及全局钩子
"""内部类
# 概念:将类定义在一个类的内部,被定义的类就是内部类
# 特点:内部类及内部类的所以名称空间,可以直接被外部类访问的
# 应用:通过内部类的名称空间,给外部类额外拓展一些特殊的属性(配置),典型的Meta内部类 - 配置类
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Car
fields = ['name', 'color', 'price', 'brand', 'img']DRF响应类:Response
"""
def __init__(self, data=None, status=None, template_name=None, headers=None, exception=False, content_type=None):
pass
data:响应的数据 - 空、字符串、数字、列表、字段、布尔
status:网络状态码
template_name:drf说自己也可以支持前后台不分离返回页面,但是不能和data共存(不会涉及)
headers:响应头(不用刻意去管)
exception:是否是异常响应(如果是异常响应,可以赋值True,没什么用)
content_type:响应的结果类型(如果是响应data,默认就是application/json,所有不用管)
"""
# 常见使用
Response(
data={
'status': 0,
'msg': 'ok',
'result': '正常数据'
}
)
Response(
data={
'status': 1,
'msg': '客户端错误提示',
},
status=status.HTTP_400_BAD_REQUEST,
exception=True
)序列化基类控制接口参数
"""
def __init__(self, instance=None, data=empty, **kwargs):
pass
instance:是要被赋值对象的 - 对象类型数据赋值给instance
data:是要被赋值数据的 - 请求来的数据赋值给data
kwargs:内部有三个属性:many、partial、context
many:操作的对象或数据,是单个的还是多个的
partial:在修改需求时使用,可以将所有校验字段required校验规则设置为False
context:用于视图类和序列化类直接传参使用
"""
# 常见使用
# 单查接口
UserModelSerializer(instance=user_obj)
# 群查接口
UserModelSerializer(instance=user_query, many=True)
# 增接口
UserModelSerializer(data=request.data)
# 整体改接口
UserModelSerializer(instance=user_obj, data=request.data)
# 局部改接口
UserModelSerializer(instance=user_obj, data=request.data, partial=True)
# 删接口,用不到序列化类局部钩子
# 局部钩子:validate_要校验的字段(self, 要校验的字段值)
exceptions.ValidationError('异常信息') 异常
# 全局钩子:validate(self, 所以字段值的字典)class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Car
fields = ['name', 'color', 'price', 'brand', 'img']
def validate_price(self,value):
if value < 0:
raise exceptions.ValidationError('小宝贝,价格必须是正数哟')
else:
return value全局钩子
# 局部钩子:validate_要校验的字段(self, 要校验的字段值)
# 全局钩子:validate(self, 所以字段值的字典)
后端密码二次校验:
def validate(self, attrs):
print(attrs)
password = attrs.get('password') # 只是拿出来校验
re_password = attrs.pop('re_password') # 必须取出校验,因为不能入库
if password != re_password:
raise exceptions.ValidationError({'re_password': '两次密码不一致'})
else:
return attrsread_only与write_only限制
不做write_only和read_only任何限制 => 序列化反序列化字段
只做read_only限制 => 只序列化字段(后台到前台)
只做write_only限制 => 只反序列化字段(前台到后台)
比如:密码用 write_only:True 。用户只能传密码给后端,不能从后端拿密码。案例:给密码做限制
xtra_kwargs = {
'password': {
'write_only': True,
'min_length': 3,
'max_length': 8,
'error_messages': { # 可以被国际化配置替代
'min_length': '太短',
'max_length': '太长'
}小结
"""
标注:序列化 => 后台到前台(读) | 反序列化 => 前台到后台(写)
1)不管是序列化还是反序列化字段,都必须在fields中进行声明,没有声明的不会参与任何过程(数据都会被丢弃)
2)用 read_only 表示只读,用 write_only 表示只写,不标注两者,代表可读可写
3)
i)自定义只读字段,在model类中用@property声明,默认就是read_only
@property
def gender(self):
return self.get_sex_display()
ii)自定义只写字段,在serializer类中声明,必须手动明确write_only
re_password = serializers.CharField(write_only=True)
特殊)在serializer类中声明,没有明确write_only,是对model原有字段的覆盖,且可读可写
password = serializers.CharField()
4)用 extra_kwargs 来为 写字段 制定基础校验规则(了解)
5)每一个 写字段 都可以用局部钩子 validate_字段(self, value) 方法来自定义校验规则,成功返回value,失败抛出 exceptions.ValidationError('异常信息') 异常
6)需要联合校验的 写字段们,用 validate(self, attrs) 方法来自定义校验规则,,成功返回attrs,失败抛出 exceptions.ValidationError({'异常字段': '异常信息'}) 异常
7)extra_kwargs中一些重要的限制条件
i)'required':代表是否必须参与写操作,有默认值或可以为空的字段,该值为False;反之该值为True;也可以手动修改值
"""
"""
开发流程:
1)在model类中自定义 读字段,在serializer类中自定义 写字段
2)将model自带字段和所以自定义字段书写在fields中,用write_only和read_only区别model自带字段
3)可以写基础校验规则,也可以省略
4)制定局部及全局钩子
"""案例
models.py:
from django.db import models
from django.conf import settings
class User(models.Model):
SEX_CHOICES = ((0,'男'), (1,'女'))
name = models.CharField(max_length=64, verbose_name='姓名')
age = models.IntegerField()
sex = models.IntegerField(choices=SEX_CHOICES, default=0)
# sex = models.CharField(choices=[('0', '男'), ('1', '女')])
height = models.DecimalField(max_digits=5, decimal_places=2, default=0)
icon = models.ImageField(upload_to='media/icon', default='media/iconhttps://img.qb5200.com/download-x/default.jpg')
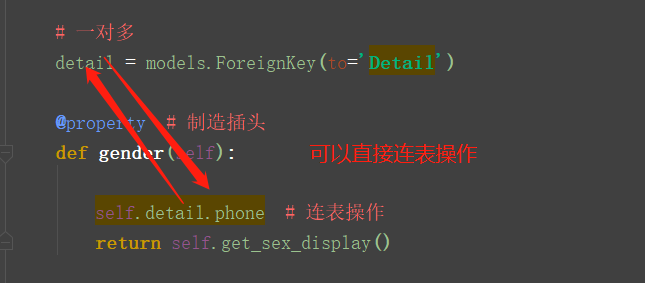
# 一对多
# detail = models.ForeignKey(to='Detail')
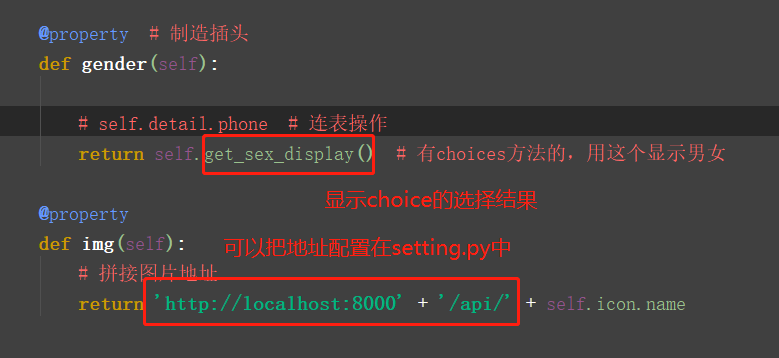
@property # 制造插头
def gender(self):
# self.detail.phone # 连表操作
return self.get_sex_display() # 有choices方法的,用这个显示男女
@property
def img(self):
# 拼接图片地址
return 'http://localhost:8000' + '/api/' + self.icon.name
class Meta:
verbose_name_plural = '用户表'
def __str__(self):
return self.name
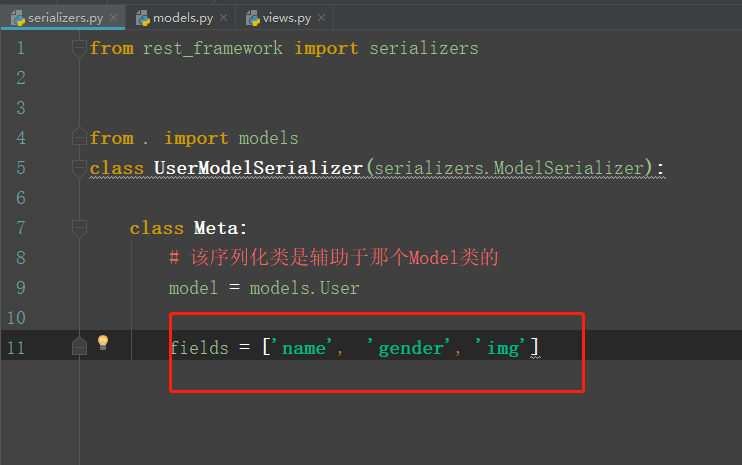
serializers.py:
from rest_framework import serializers
from rest_framework import exceptions
from . import models
class UserModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Car
fields = ['name', 'color', 'price', 'brand', 'img']
def validate_price(self,value):
if value < 0:
raise exceptions.ValidationError('小宝贝,价格必须是正数哟')
else:
return value
def validate_brand(self, value):
for _char in value:
# 过滤:不是汉字或者不是字母
if not '\u4e00' <= _char <= '\u9fa5' or not _char.isalpha():
raise exceptions.ValidationError('brand必须是字母或者汉字')
else:
return value
views.py:单查群查单增
from rest_framework.views import APIView
from rest_framework.response import Response
from . import models
from rest_framework import status
from . import serializers
class CarAPIView(APIView):
def get(self, request, *args, **kwargs):
pk = kwargs.get('pk')
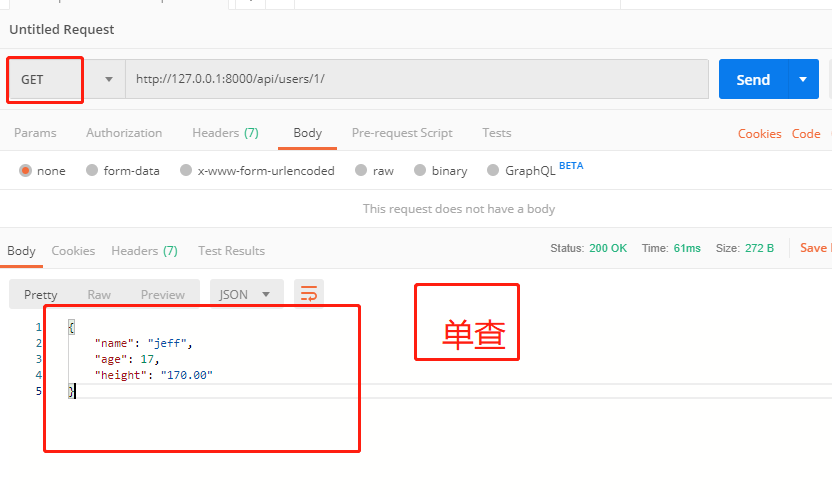
if pk: # 单查
try:
obj = models.Car.objects.get(pk=pk)
serializer = serializers.UserModelSerializer(obj,many=False) # # many=True表示:操作多个数据.默认为False
return Response({
'status':0,
'msg':'ok',
'result': serializer.data
})
except:
return Response(
status=status.HTTP_400_BAD_REQUEST,
exception=True,
data={
'status': 1,
'msg': 'pk error'
},
)
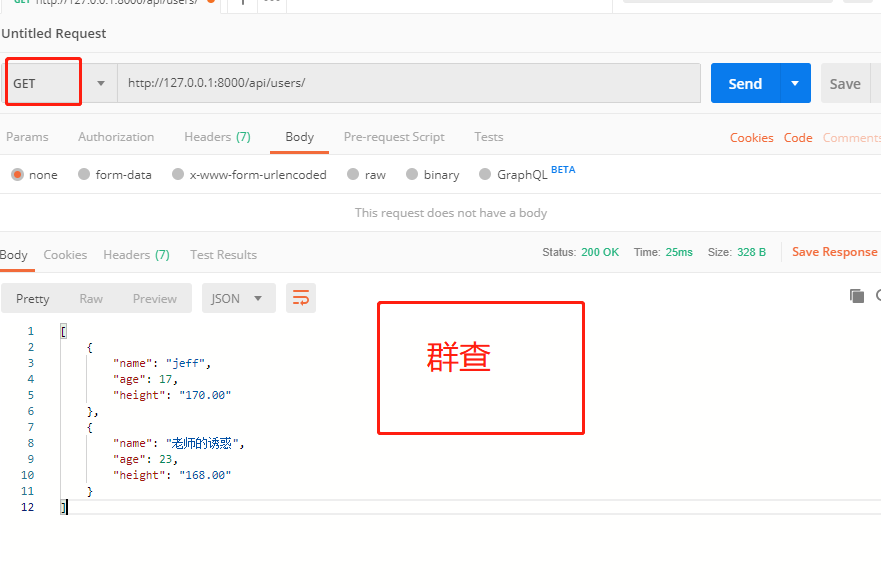
else: # 群查
queryset = models.Car.objects.all()
serializer = serializers.UserModelSerializer(queryset, many=True) # many=True表示:操作多个数据
return Response({
'status': 0,
'msg': 'ok',
'results': serializer.data
})
def post(self, request, *args, **kwargs):
# 单增
serializer = serializers.UserModelSerializer(data=request.data)
if serializer.is_valid():
# 校验成功 => 入库 => 正常响应
serializer.save()
return Response({
'status': 0,
'msg': 'ok',
'result': '新增的那个对象'
}, status=status.HTTP_201_CREATED)
else:
# 校验失败 => 异常响应
print('失败')
return Response({
'status': 1,
'msg': serializer.errors,
}, status=status.HTTP_400_BAD_REQUEST)
测试:
连表操作
配置图片和性别
测试:


加载全部内容