Standby Redo Logs的前世今生与最佳实践
vmsysjack 人气:3编辑手记:使用过Data Guard的人应该对于Standby Redo Logs都不陌生,在配置了 Standby Redo Logs的standby中,能够进行日志的实时应用,同时Standby Redo Logs能够给主库传输过来的日志增加一层安全保护。然而在很多的生产环境中,大家都很少使用Standby Redo Logs。本文将会深入剖析Standby Redo Logs的前世今生,工作机制以及一些最佳实践。
本文翻译自BPeaslandDBA的博客。
原文链接:https://community.oracle.comhttps://img.qb5200.com/download-x/docs/DOC-1007036
Introduction
在生产环境中,我发现大部分的Data Guard的standby上没有配置Standby Redo Logs,这让我感到很惊讶。我认为配置Standby Redo Logs是非常必要的,在我的环境中,我从来都会配置Standby Redo Logs。 当然配置Standby Redo Logs的确对于DBA来说,是增加了一项需要维护的内容,但这是完全值得的,并且Standby Redo Logs在配置并投入使用之后,后期基本上不需要花太多心思维护的。
我想大部分人不使用SRLs的原因是,他们不理解SRLs能够带来的好处,本文将会详解SRLs的优势,其创建维护方式及最佳实践。
为什么使用SRLs?
如果standby配置的是最大保护模式,那么必须配置Standby Redo Logs。
通过SRLs对几乎实时传输过来的日志进行存储并及时应用。当然,如果是最大性能模式,配置SRLs也同样会有很多好处,为了让读者更好地理解这一点,
首先我们来看一下在没有SRLs的情况下,日志的传输是怎么进行的。
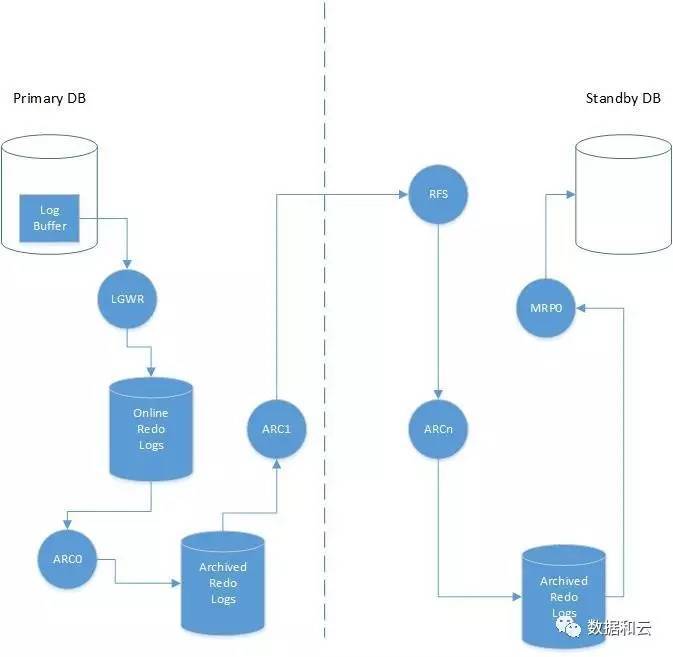
在上图中,staandby中没有配置SRLs,因此Redo传输和应用的过程如下:
1、事务将日志条目写入SGA中的Redo Log buffer。
2、LGWR进程将Redo 条目从Redo Log buffer写入到online Redo logs.
3、当online Redo logs发生切换(一般是由于当前日志写满了),ARC0进程会将online Redo logs中的内容写入到Archived Redo log.
4、在standby数据库存在的情况下,归档进程会多启用一条子进程ARC1,读取archived Redo log的内容,并传输到对端的RS进程(remote file server)。
5、RFS将主库接受过来的日志发送给standby库的ARCn进程。
6、standby的ARCn进程将日志写入到standby的archived redo log。
7、当日志成功发送到archived redo log之后,MRP0进程在备库进行日志应用。
以上过程虽然看着复杂,但逻辑是比较简单和清晰的。
那么如果在配置了SRLs的环境中,日志的传输过程又是怎么样的呢?
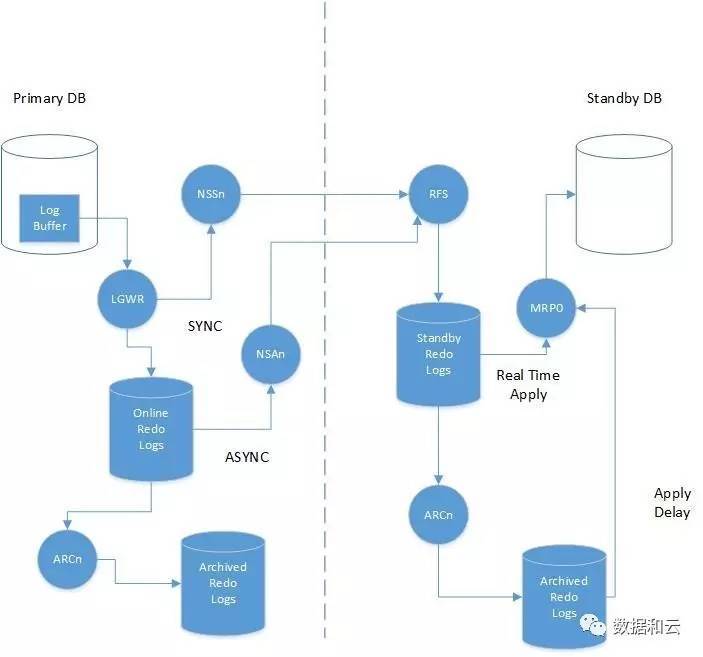
在配置了SRLs的情况下,日志的传输中不仅增加了新的元素,还增加了许多新的选择。
1、跟没有配置SRLs的时候一样,第一步仍然是事务产生的Redo条目写入。
2、LGWR进程将Redo写入到online Redo log。
3、明确是最大保护模式还是最大性能模式
a、在最大保护模式下,进行的是同步的日志传输(SYNC),网络服务器同步进程(NSSn)是LGWR的slave进程。它的作用是将Redo传输给standby的RFS进程。
b、在最大性能模式下,进行的是Redo的异步传输(ASYNS),网络服务器异步传输进程(NSAn)从主库的online Redo log中读取数据,并传输给standby库的RFS进程。
4、standby服务器上的RFS进程将Redo流 直接写入到SRLs。
5、日志的应用方式取决于系统是否配置了实时应用。
a、如果配置了实时应用,MRP0进程将直接将SRLs的日志读取并应用到standby数据库。
b、如果没有配置实时的日志应用的话,MRP0进程将等待SRLs中的日志完成归档之后,再将归档后的日志应用到standby数据库。
在上述的步骤中,步骤三基本上解释了我们为什么要使用SRLs,在DG的最大保护模式下,也就是日志的同步传输模式下,必须要配置SRLs,否则同步的机制就不能生效。
在最大性能模式下,配置SRLs仍然是有必要的,因为SRLs能够将数据的丢失从小时降低到秒级别。在最大性能模式下配置SRLs能够实现几乎零数据丢失的数据传输。
使用SRLs的另外一个比较重要的原因是当配置了实时的日志应用,能够带来很大的好处。只要将Redo传输到了SRLs里面,就能够立即应用到standby数据库当中,不需要等待日志切换。只有配置了SRLs,才能保证在实时应用日志的时候,failover的切换和恢复时间降到最低。
很多用户在基于日志的异步传输的情况下的操作都有这样一个误区。
认为只有ARCn进程才可以将主库的日志传输到备库。这样的观点在早期的版本中是对的。
但是从10g,甚至是9i开始,只有在没有配置SRLs的情况下,才由ARCn进程来传输日志。如果配置了SRLs,12c之前,是由LNS进程传输,而12c以后,传输日志的任务是由NSAn进程完成的。NSAn的传输几乎实时实时的。
在没有配置SRLs的情况下,日志的传输必须要等待主库的日志的切换,如果在主库日志一个小时切换一次,那么就有可能产生一个小时的数据的损失风险,如果主库日志切换频率更低,那么面临的数据损失的概率就更高。
当然,这种情况可以通过主库的初始化参数 ARCHIVE_LAG_TARGET的设置来改善,如果DBA将该参数设置为3600秒,那么一个小时最多可能发生一次日志切换。但即使是这样,一个小时的数据损失仍然是很大的,而且对于大部分的企业用户来说,这种损失都是不可接受的。
为了减少等待日志切换带来的数据损失的风险,你需要做的只是配置一下SRLs,非常简单,但是却能给你的系统带来很大的性能和安全保障。
如何创建SRLs
创建SRLs的方式跟创建普通的online redo logs的方式是很相近的,在alter Database命令中多添加一个属性的设置就好,也就是增加关键字 “Standby”。
首先我们来看当前系统中online Redo logs的大小设置。
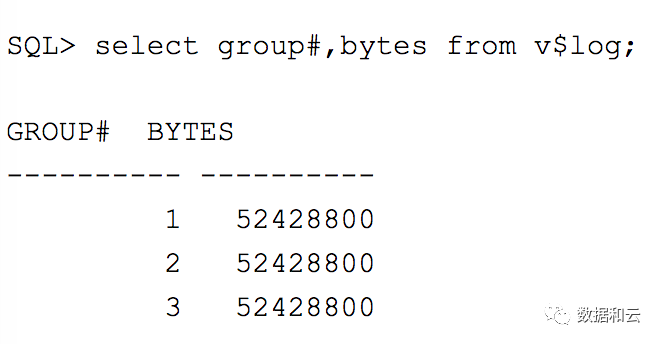
对于上面的结果,我曾看到有人将它理解为“50MB”,然后他们就将SRLs的大小设置为50MB,这样是不精确的。
我在操作的过程中,都是完全按照online Redo Log的大小精确设置SRLs的大小的。还有一点是,有时候我们看到ORL的不同的组里面,日志的大小设置是不一样的,在这种情况下,不能直接配置SRLs。
建议先将所有的online Redo Log大小是指一样,然后再配置SRLs。
接下来我们进行SRLs的配置。
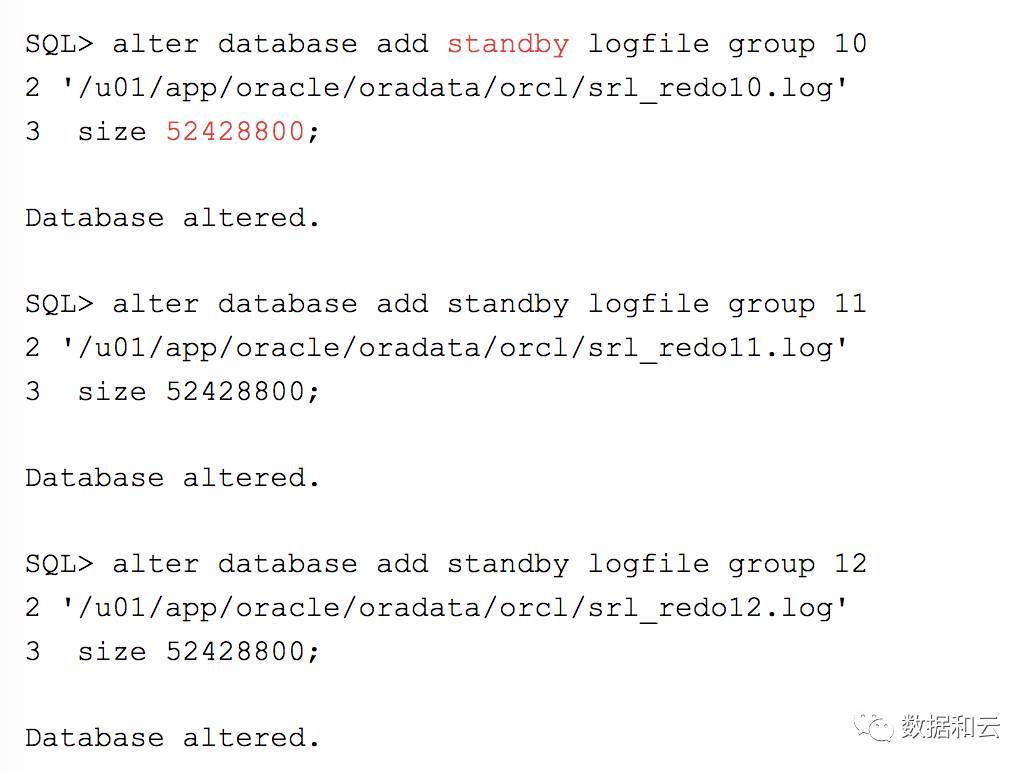
lSRLs的创建语句跟普通的online Redo logd 的创建唯一不同的地方在于多了一个关键字 standby。 并且在我创建的时候,SRLs的大小是完全按照ORL 的大小设置的。
由于系统当前有三组online Redo Log,在创建SRLs 的时候,如果不指定组数的话,系统默认会写成 group 4-6。那么后续如果需要增加日志组的话,就可能产生混乱。因此我从group 10开始配置SRLs.
接下来我们通过数据字典来查看SRLs
我们看到SRLs对应的thread# 为0,在配置SRLs的时候,尽量避免将SRLs制定到特定的thread上,这样就能够被主库中的所有节点的ORLs使用。
接下来我们查看所有的日志类型的组。
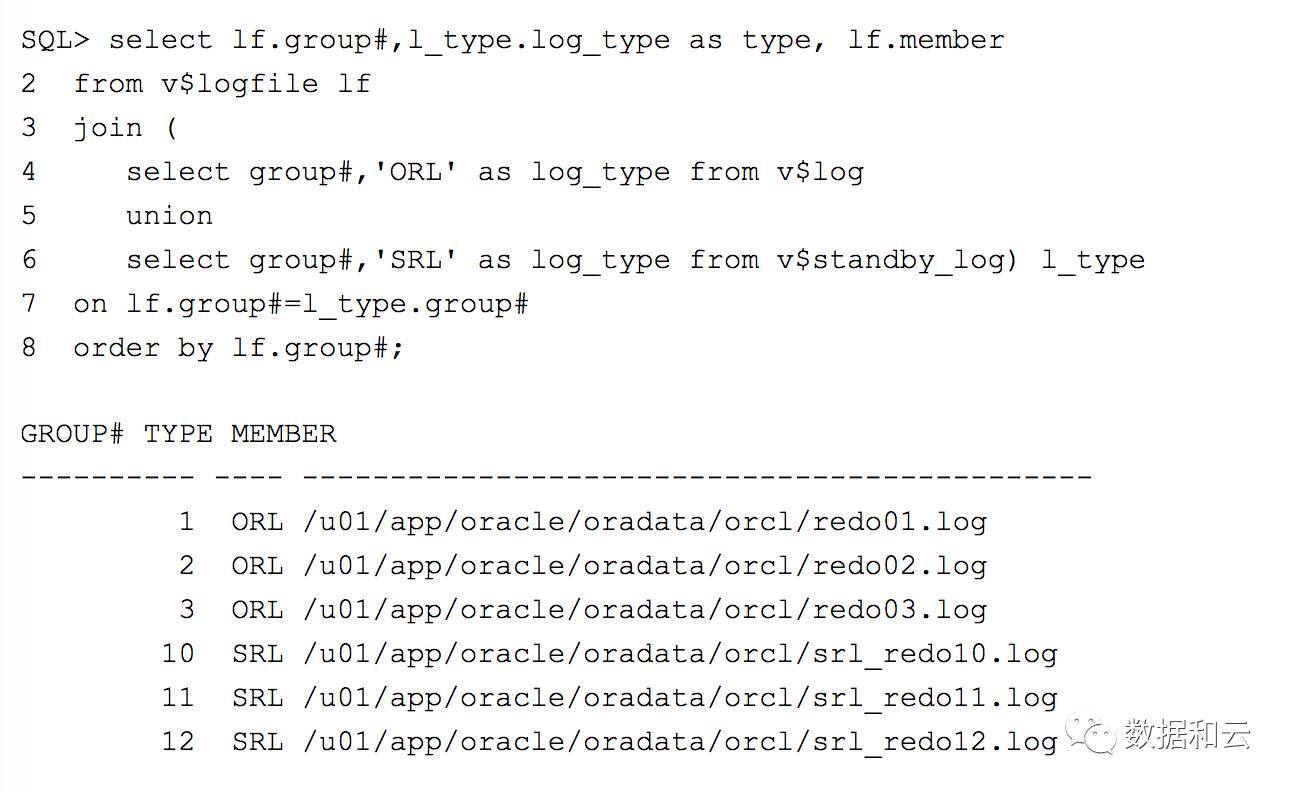
由于在创建的时候,group的编号是分开的。因此,这样在查询的时候,结果就可以按照日志的类型排列。
最佳实践
其实在介绍SRLs的时候,已经设计到了一些最佳实践。这部分,将会更全面地介绍SRLs的最佳实践。
1
确保所有配置的SRLs的组,其日志大小是一致的。
2
确保所有的SRLs的组中的日志跟ORL的大小一致。保证所有从主库传输过来的日志能够在SRLs中有足够的空间保存。当然,如果实在没有办法保证SRLs跟ORLs的大小一致的,可以设置SRLs的大小大于ORLs的大小。
3
在SRLs中不要配置任何thread,这样,SRLs就能够被所有的节点使用,包含在RAC中的主节点。
4
当在standby数据库上配置SRLs的时候,也需要同时在Primary数据库上配置,正常情况下,在主库上配置的SRLs是不会被使用的,但如果某一天你需要执行switchover的话,提前配置好SRLs会带来很大的便利。
5
对于Oracle RAC的主备方案来说,最好是在standby上配置SRLs数量跟所有Primary节点上的一样多。 比如说,如果你有一个3个节点的Oracle RAC数据库,并在每一个节点上配置了4组SRLs的话,那么在standby的节点上就需要配置3*4=12组的SRLs,不管你的standby上有多少个实例,standby数据库必须要保证能够能够容纳所有Primary数据库节点上的ORLs。
加载全部内容