几篇关于无限分类算法的文章
人气:0http://dev.mysql.com/tech-resources/articles/hierarchical-data.html
Introduction
Most users at one time or another have dealt with hierarchical data in a SQL database and no doubt learned that the management of hierarchical data is not what a relational database is intended for. The tables of a relational database are not hierarchical (like XML), but are simply a flat list. Hierarchical data has a parent-child relationship that is not naturally represented in a relational database table.
For our purposes, hierarchical data is a collection of data where each item has a single parent and zero or more children (with the exception of the root item, which has no parent). Hierarchical data can be found in a variety of database applications, including forum and mailing list threads, business organization charts, content management categories, and product categories. For our purposes we will use the following product category hierarchy from an fictional electronics store:

These categories form a hierarchy in much the same way as the other examples cited above. In this article we will examine two models for dealing with hierarchical data in MySQL, starting with the traditional adjacency list model.
The Adjacency List Model
Typically the example categories shown above will be stored in a table like the following (I'm including full CREATE and INSERT statements so you can follow along):
CREATE TABLE category( category_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, parent INT DEFAULT NULL); INSERT INTO category VALUES(1,'ELECTRONICS',NULL),(2,'TELEVISIONS',1),(3,'TUBE',2), (4,'LCD',2),(5,'PLASMA',2),(6,'PORTABLE ELECTRONICS',1), (7,'MP3 PLAYERS',6),(8,'FLASH',7), (9,'CD PLAYERS',6),(10,'2 WAY RADIOS',6); SELECT * FROM category ORDER BY category_id; +-------------+----------------------+--------+ | category_id | name | parent | +-------------+----------------------+--------+ | 1 | ELECTRONICS | NULL | | 2 | TELEVISIONS | 1 | | 3 | TUBE | 2 | | 4 | LCD | 2 | | 5 | PLASMA | 2 | | 6 | PORTABLE ELECTRONICS | 1 | | 7 | MP3 PLAYERS | 6 | | 8 | FLASH | 7 | | 9 | CD PLAYERS | 6 | | 10 | 2 WAY RADIOS | 6 | +-------------+----------------------+--------+ 10 rows in set (0.00 sec)
In the adjacency list model, each item in the table contains a pointer to its parent. The topmost element, in this case electronics, has a NULL value for its parent. The adjacency list model has the advantage of being quite simple, it is easy to see that FLASH is a child of mp3 players, which is a child of portable electronics, which is a child of electronics. While the adjacency list model can be dealt with fairly easily in client-side code, working with the model can be more problematic in pure SQL.
Retrieving a Full Tree
The first common task when dealing with hierarchical data is the display of the entire tree, usually with some form of indentation. The most common way of doing this is in pure SQL is through the use of a self-join:
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4 FROM category AS t1 LEFT JOIN category AS t2 ON t2.parent = t1.category_id LEFT JOIN category AS t3 ON t3.parent = t2.category_id LEFT JOIN category AS t4 ON t4.parent = t3.category_id WHERE t1.name = 'ELECTRONICS'; +-------------+----------------------+--------------+-------+ | lev1 | lev2 | lev3 | lev4 | +-------------+----------------------+--------------+-------+ | ELECTRONICS | TELEVISIONS | TUBE | NULL | | ELECTRONICS | TELEVISIONS | LCD | NULL | | ELECTRONICS | TELEVISIONS | PLASMA | NULL | | ELECTRONICS | PORTABLE ELECTRONICS | MP3 PLAYERS | FLASH | | ELECTRONICS | PORTABLE ELECTRONICS | CD PLAYERS | NULL | | ELECTRONICS | PORTABLE ELECTRONICS | 2 WAY RADIOS | NULL | +-------------+----------------------+--------------+-------+ 6 rows in set (0.00 sec)
Finding all the Leaf Nodes
We can find all the leaf nodes in our tree (those with no children) by using a LEFT JOIN query:
SELECT t1.name FROM category AS t1 LEFT JOIN category as t2 ON t1.category_id = t2.parent WHERE t2.category_id IS NULL; +--------------+ | name | +--------------+ | TUBE | | LCD | | PLASMA | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | +--------------+
Retrieving a Single Path
The self-join also allows us to see the full path through our hierarchies:
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3, t4.name as lev4 FROM category AS t1 LEFT JOIN category AS t2 ON t2.parent = t1.category_id LEFT JOIN category AS t3 ON t3.parent = t2.category_id LEFT JOIN category AS t4 ON t4.parent = t3.category_id WHERE t1.name = 'ELECTRONICS' AND t4.name = 'FLASH'; +-------------+----------------------+-------------+-------+ | lev1 | lev2 | lev3 | lev4 | +-------------+----------------------+-------------+-------+ | ELECTRONICS | PORTABLE ELECTRONICS | MP3 PLAYERS | FLASH | +-------------+----------------------+-------------+-------+ 1 row in set (0.01 sec)
The main limitation of such an approach is that you need one self-join for every level in the hierarchy, and performance will naturally degrade with each level added as the joining grows in complexity.
Limitations of the Adjacency List Model
Working with the adjacency list model in pure SQL can be difficult at best. Before being able to see the full path of a category we have to know the level at which it resides. In addition, special care must be taken when deleting nodes because of the potential for orphaning an entire sub-tree in the process (delete the portable electronics category and all of its children are orphaned). Some of these limitations can be addressed through the use of client-side code or stored procedures. With a procedural language we can start at the bottom of the tree and iterate upwards to return the full tree or a single path. We can also use procedural programming to delete nodes without orphaning entire sub-trees by promoting one child element and re-ordering the remaining children to point to the new parent.
The Nested Set Model
What I would like to focus on in this article is a different approach, commonly referred to as the Nested Set Model. In the Nested Set Model, we can look at our hierarchy in a new way, not as nodes and lines, but as nested containers. Try picturing our electronics categories this way:

Notice how our hierarchy is still maintained, as parent categories envelop their children.We represent this form of hierarchy in a table through the use of left and right values to represent the nesting of our nodes:
CREATE TABLE nested_category ( category_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, lft INT NOT NULL, rgt INT NOT NULL ); INSERT INTO nested_category VALUES(1,'ELECTRONICS',1,20),(2,'TELEVISIONS',2,9),(3,'TUBE',3,4), (4,'LCD',5,6),(5,'PLASMA',7,8),(6,'PORTABLE ELECTRONICS',10,19), (7,'MP3 PLAYERS',11,14),(8,'FLASH',12,13), (9,'CD PLAYERS',15,16),(10,'2 WAY RADIOS',17,18); SELECT * FROM nested_category ORDER BY category_id; +-------------+----------------------+-----+-----+ | category_id | name | lft | rgt | +-------------+----------------------+-----+-----+ | 1 | ELECTRONICS | 1 | 20 | | 2 | TELEVISIONS | 2 | 9 | | 3 | TUBE | 3 | 4 | | 4 | LCD | 5 | 6 | | 5 | PLASMA | 7 | 8 | | 6 | PORTABLE ELECTRONICS | 10 | 19 | | 7 | MP3 PLAYERS | 11 | 14 | | 8 | FLASH | 12 | 13 | | 9 | CD PLAYERS | 15 | 16 | | 10 | 2 WAY RADIOS | 17 | 18 | +-------------+----------------------+-----+-----+
We use lft and rgt because left and right are reserved words in MySQL, see http://dev.mysql.com/doc/mysql/en/reserved-words.html for the full list of reserved words.
So how do we determine left and right values? We start numbering at the leftmost side of the outer node and continue to the right:

This design can be applied to a typical tree as well:

When working with a tree, we work from left to right, one layer at a time, descending to each node's children before assigning a right-hand number and moving on to the right. This approach is called the modified preorder tree traversal algorithm.
Retrieving a Full Tree
We can retrieve the full tree through the use of a self-join that links parents with nodes on the basis that a node's lft value will always appear between its parent's lft and rgt values:
SELECT node.name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND parent.name = 'ELECTRONICS' ORDER BY node.lft; +----------------------+ | name | +----------------------+ | ELECTRONICS | | TELEVISIONS | | TUBE | | LCD | | PLASMA | | PORTABLE ELECTRONICS | | MP3 PLAYERS | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | +----------------------+
Unlike our previous examples with the adjacency list model, this query will work regardless of the depth of the tree. We do not concern ourselves with the rgt value of the node in our BETWEEN clause because the rgt value will always fall within the same parent as the lft values.
Finding all the Leaf Nodes
Finding all leaf nodes in the nested set model even simpler than the LEFT JOIN method used in the adjacency list model. If you look at the nested_category table, you may notice that the lft and rgt values for leaf nodes are consecutive numbers. To find the leaf nodes, we look for nodes where rgt = lft + 1:
SELECT name FROM nested_category WHERE rgt = lft + 1; +--------------+ | name | +--------------+ | TUBE | | LCD | | PLASMA | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | +--------------+
Retrieving a Single Path
With the nested set model, we can retrieve a single path without having multiple self-joins:
SELECT parent.name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'FLASH' ORDER BY node.lft; +----------------------+ | name | +----------------------+ | ELECTRONICS | | PORTABLE ELECTRONICS | | MP3 PLAYERS | | FLASH | +----------------------+
Finding the Depth of the Nodes
We have already looked at how to show the entire tree, but what if we want to also show the depth of each node in the tree, to better identify how each node fits in the hierarchy? This can be done by adding a COUNT function and a GROUP BY clause to our existing query for showing the entire tree:
SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft; +----------------------+-------+ | name | depth | +----------------------+-------+ | ELECTRONICS | 0 | | TELEVISIONS | 1 | | TUBE | 2 | | LCD | 2 | | PLASMA | 2 | | PORTABLE ELECTRONICS | 1 | | MP3 PLAYERS | 2 | | FLASH | 3 | | CD PLAYERS | 2 | | 2 WAY RADIOS | 2 | +----------------------+-------+
We can use the depth value to indent our category names with the CONCAT and REPEAT string functions:
SELECT CONCAT( REPEAT(' ', COUNT(parent.name) - 1), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+-----------------------+
Of course, in a client-side application you will be more likely to use the depth value directly to display your hierarchy. Web developers could loop through the tree, adding <li></li> and <ul></ul> tags as the depth number increases and decreases.
Depth of a Sub-Tree
When we need depth information for a sub-tree, we cannot limit either the node or parent tables in our self-join because it will corrupt our results. Instead, we add a third self-join, along with a sub-query to determine the depth that will be the new starting point for our sub-tree:
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth FROM nested_category AS node, nested_category AS parent, nested_category AS sub_parent, ( SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'PORTABLE ELECTRONICS' GROUP BY node.name ORDER BY node.lft )AS sub_tree WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt AND sub_parent.name = sub_tree.name GROUP BY node.name ORDER BY node.lft; +----------------------+-------+ | name | depth | +----------------------+-------+ | PORTABLE ELECTRONICS | 0 | | MP3 PLAYERS | 1 | | FLASH | 2 | | CD PLAYERS | 1 | | 2 WAY RADIOS | 1 | +----------------------+-------+
This function can be used with any node name, including the root node. The depth values are always relative to the named node.
Find the Immediate Subordinates of a Node
Imagine you are showing a category of electronics products on a retailer web site. When a user clicks on a category, you would want to show the products of that category, as well as list its immediate sub-categories, but not the entire tree of categories beneath it. For this, we need to show the node and its immediate sub-nodes, but no further down the tree. For example, when showing the PORTABLE ELECTRONICS category, we will want to show MP3 PLAYERS, CD PLAYERS, and 2 WAY RADIOS, but not FLASH.
This can be easily accomplished by adding a HAVING clause to our previous query:
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) AS depth FROM nested_category AS node, nested_category AS parent, nested_category AS sub_parent, ( SELECT node.name, (COUNT(parent.name) - 1) AS depth FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.name = 'PORTABLE ELECTRONICS' GROUP BY node.name ORDER BY node.lft )AS sub_tree WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt AND sub_parent.name = sub_tree.name GROUP BY node.name HAVING depth <= 1 ORDER BY node.lft; +----------------------+-------+ | name | depth | +----------------------+-------+ | PORTABLE ELECTRONICS | 0 | | MP3 PLAYERS | 1 | | CD PLAYERS | 1 | | 2 WAY RADIOS | 1 | +----------------------+-------+
If you do not wish to show the parent node, change the HAVING depth <= 1 line to HAVING depth = 1.
Aggregate Functions in a Nested Set
Let's add a table of products that we can use to demonstrate aggregate functions with:
CREATE TABLE product(
product_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(40),
category_id INT NOT NULL
);
INSERT INTO product(name, category_id) VALUES('20" TV',3),('36" TV',3),
('Super-LCD 42"',4),('Ultra-Plasma 62"',5),('Value Plasma 38"',5),
('Power-MP3 5gb',7),('Super-Player 1gb',8),('Porta CD',9),('CD To go!',9),
('Family Talk 360',10);
SELECT * FROM product;
+------------+-------------------+-------------+
| product_id | name | category_id |
+------------+-------------------+-------------+
| 1 | 20" TV | 3 |
| 2 | 36" TV | 3 |
| 3 | Super-LCD 42" | 4 |
| 4 | Ultra-Plasma 62" | 5 |
| 5 | Value Plasma 38" | 5 |
| 6 | Power-MP3 128mb | 7 |
| 7 | Super-Shuffle 1gb | 8 |
| 8 | Porta CD | 9 |
| 9 | CD To go! | 9 |
| 10 | Family Talk 360 | 10 |
+------------+-------------------+-------------+
Now let's produce a query that can retrieve our category tree, along with a product count for each category:
SELECT parent.name, COUNT(product.name) FROM nested_category AS node , nested_category AS parent, product WHERE node.lft BETWEEN parent.lft AND parent.rgt AND node.category_id = product.category_id GROUP BY parent.name ORDER BY node.lft; +----------------------+---------------------+ | name | COUNT(product.name) | +----------------------+---------------------+ | ELECTRONICS | 10 | | TELEVISIONS | 5 | | TUBE | 2 | | LCD | 1 | | PLASMA | 2 | | PORTABLE ELECTRONICS | 5 | | MP3 PLAYERS | 2 | | FLASH | 1 | | CD PLAYERS | 2 | | 2 WAY RADIOS | 1 | +----------------------+---------------------+
This is our typical whole tree query with a COUNT and GROUP BY added, along with a reference to the product table and a join between the node and product table in the WHERE clause. As you can see, there is a count for each category and the count of subcategories is reflected in the parent categories.
Adding New Nodes
Now that we have learned how to query our tree, we should take a look at how to update our tree by adding a new node. Let's look at our nested set diagram again:

If we wanted to add a new node between the TELEVISIONS and PORTABLE ELECTRONICS nodes, the new node would have lft and rgt values of 10 and 11, and all nodes to its right would have their lft and rgt values increased by two. We would then add the new node with the appropriate lft and rgt values. While this can be done with a stored procedure in MySQL 5, I will assume for the moment that most readers are using 4.1, as it is the latest stable version, and I will isolate my queries with a LOCK TABLES statement instead:
LOCK TABLE nested_category WRITE;
SELECT @myRight := rgt FROM nested_category
WHERE name = 'TELEVISIONS';
UPDATE nested_category SET rgt = rgt + 2 WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft + 2 WHERE lft > @myRight;
INSERT INTO nested_category(name, lft, rgt) VALUES('GAME CONSOLES', @myRight + 1, @myRight + 2);
UNLOCK TABLES;
We can then check our nesting with our indented tree query:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+-----------------------+
| name |
+-----------------------+
| ELECTRONICS |
| TELEVISIONS |
| TUBE |
| LCD |
| PLASMA |
| GAME CONSOLES |
| PORTABLE ELECTRONICS |
| MP3 PLAYERS |
| FLASH |
| CD PLAYERS |
| 2 WAY RADIOS |
+-----------------------+
If we instead want to add a node as a child of a node that has no existing children, we need to modify our procedure slightly. Let's add a new FRS node below the 2 WAY RADIOS node:
LOCK TABLE nested_category WRITE;
SELECT @myLeft := lft FROM nested_category
WHERE name = '2 WAY RADIOS';
UPDATE nested_category SET rgt = rgt + 2 WHERE rgt > @myLeft;
UPDATE nested_category SET lft = lft + 2 WHERE lft > @myLeft;
INSERT INTO nested_category(name, lft, rgt) VALUES('FRS', @myLeft + 1, @myLeft + 2);
UNLOCK TABLES;
In this example we expand everything to the right of the left-hand number of our proud new parent node, then place the node to the right of the left-hand value. As you can see, our new node is now properly nested:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft; +-----------------------+ | name | +-----------------------+ | ELECTRONICS | | TELEVISIONS | | TUBE | | LCD | | PLASMA | | GAME CONSOLES | | PORTABLE ELECTRONICS | | MP3 PLAYERS | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | | FRS | +-----------------------+
Deleting Nodes
The last basic task involved in working with nested sets is the removal of nodes. The course of action you take when deleting a node depends on the node's position in the hierarchy; deleting leaf nodes is easier than deleting nodes with children because we have to handle the orphaned nodes.
When deleting a leaf node, the process if just the opposite of adding a new node, we delete the node and its width from every node to its right:
LOCK TABLE nested_category WRITE; SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1 FROM nested_category WHERE name = 'GAME CONSOLES'; DELETE FROM nested_category WHERE lft BETWEEN @myLeft AND @myRight; UPDATE nested_category SET rgt = rgt - @myWidth WHERE rgt > @myRight; UPDATE nested_category SET lft = lft - @myWidth WHERE lft > @myRight; UNLOCK TABLES;
And once again, we execute our indented tree query to confirm that our node has been deleted without corrupting the hierarchy:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft; +-----------------------+ | name | +-----------------------+ | ELECTRONICS | | TELEVISIONS | | TUBE | | LCD | | PLASMA | | PORTABLE ELECTRONICS | | MP3 PLAYERS | | FLASH | | CD PLAYERS | | 2 WAY RADIOS | | FRS | +-----------------------+
This approach works equally well to delete a node and all its children:
LOCK TABLE nested_category WRITE; SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1 FROM nested_category WHERE name = 'MP3 PLAYERS'; DELETE FROM nested_category WHERE lft BETWEEN @myLeft AND @myRight; UPDATE nested_category SET rgt = rgt - @myWidth WHERE rgt > @myRight; UPDATE nested_category SET lft = lft - @myWidth WHERE lft > @myRight; UNLOCK TABLES;
And once again, we query to see that we have successfully deleted an entire sub-tree:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft; +-----------------------+ | name | +-----------------------+ | ELECTRONICS | | TELEVISIONS | | TUBE | | LCD | | PLASMA | | PORTABLE ELECTRONICS | | CD PLAYERS | | 2 WAY RADIOS | | FRS | +-----------------------+
The other scenario we have to deal with is the deletion of a parent node but not the children. In some cases you may wish to just change the name to a placeholder until a replacement is presented, such as when a supervisor is fired. In other cases, the child nodes should all be moved up to the level of the deleted parent:
LOCK TABLE nested_category WRITE; SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt - lft + 1 FROM nested_category WHERE name = 'PORTABLE ELECTRONICS'; DELETE FROM nested_category WHERE lft = @myLeft; UPDATE nested_category SET rgt = rgt - 1, lft = lft - 1 WHERE lft BETWEEN @myLeft AND @myRight; UPDATE nested_category SET rgt = rgt - 2 WHERE rgt > @myRight; UPDATE nested_category SET lft = lft - 2 WHERE lft > @myRight; UNLOCK TABLES;
In this case we subtract two from all elements to the right of the node (since without children it would have a width of two), and one from the nodes that are its children (to close the gap created by the loss of the parent's left value). Once again, we can confirm our elements have been promoted:
SELECT CONCAT( REPEAT( ' ', (COUNT(parent.name) - 1) ), node.name) AS name FROM nested_category AS node, nested_category AS parent WHERE node.lft BETWEEN parent.lft AND parent.rgt GROUP BY node.name ORDER BY node.lft; +---------------+ | name | +---------------+ | ELECTRONICS | | TELEVISIONS | | TUBE | | LCD | | PLASMA | | CD PLAYERS | | 2 WAY RADIOS | | FRS | +---------------+
Other scenarios when deleting nodes would include promoting one of the children to the parent position and moving the child nodes under a sibling of the parent node, but for the sake of space these scenarios will not be covered in this article.
http://www.nirvanastudio.org/php/hierarchical-data-database.html
中文翻译
在数据库中存储层次数据
作者:Gijs Van Tulder
翻译:ShiningRay @ NirvanaStudio
无论你要构建自己的论坛,在你的网站上发布消息还是书写自己的cms [1]程序,你都会遇到要在数据库中存储层次数据的情况。同时,除非你使用一种像XML [2]的数据库,否则关系数据库中的表都不是层次结构的,他们只是一个平坦的列表。所以你必须找到一种把层次数据库转化的方法。
存储树形结构是一个很常见的问题,他有好几种解决方案。主要有两种方法:邻接列表模型和改进前序遍历树算法
在本文中,我们将探讨这两种保存层次数据的方法。我将举一个在线食品店树形图的例子。这个食品店通过类别、颜色和品种来组织食品。树形图如下:
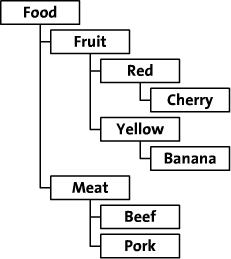
本文包含了一些代码的例子来演示如何保存和获取数据。我选择PHP [3]来写例子,因为我常用这个语言,而且很多人也都使用或者知道这个语言。你可以很方便地把它们翻译成你自己用的语言。
邻接列表模型(The Adjacency List Model)
我们要尝试的第一个——也是最优美的——方法称为“邻接列表模型”或称为“递归方法”。它是一个很优雅的方法因为你只需要一个简单的方法来在你的树中进行迭代。在我们的食品店中,邻接列表的表格如下:
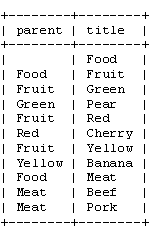
如你所见,对每个节点保存一个“父”节点。我们可以看到“Pear [4]”是“Green”的一个子节点,而后者又是“Fruit”的子节点,如此类推。根节点,“Food”,则他的父节点没有值。为了简单,我只用了“title”值来标识每个节点。当然,在实际的数据库中,你要使用数字的ID。
显示树
现在我们已经把树放入数据库中了,得写一个显示函数了。这个函数将从根节点开始——没有父节点的节点——同时要显示这个节点所有的子节点。对于这些子节点,函数也要获取并显示这个子节点的子节点。然后,对于他们的子节点,函数还要再显示所有的子节点,然后依次类推。
也许你已经注意到了,这种函数的描述,有一种普遍的模式。我们可以简单地只写一个函数,用来获得特定节点的子节点。这个函数然后要对每个子节点调用自身来再次显示他们的子节点。这就是“递归”机制,因此称这种方法叫“递归方法”。
<?php
// $parent 是我们要查看的子节点的父节点
// $level 会随着我们深入树的结构而不断增加,
// 用来显示一个清晰的缩进格式
function display_children($parent, $level) {
// 获取$parent的全部子节点
$result = mysql_query('SELECT title FROM tree '.
'WHERE parent="'.$parent.'";');
// 显示每个节点
while ($row = mysql_fetch_array($result)) {
// 缩进并显示他的子节点的标题
echo str_repeat(' ',$level).$row['title']."\n";
// 再次调用这个函数来显着这个子节点的子节点
display_children($row['title'], $level+1);
}
}
?>
要实现整个树,我们只要调用函数时用一个空字符串作为$parent 和$level = 0: display_children('',0); 函数返回了我们的食品店的树状图如下:
Food
Fruit
Red
Cherry
Yellow
Banana
Meat
Beef
Pork
注意如果你只想看一个子树,你可以告诉函数从另一个节点开始。例如,要显示“Fruit”子树,你只要display_children('Fruit',0);
The Path to a Node节点的路径
利用差不多的函数,我们也可以查询某个节点的路径如果你只知道这个节点的名字或者ID。例如,“Cherry”的路径是“Food”>“Fruit”>“Red”。要获得这个路径,我们的函数要获得这个路径,这个函数必须从最深的层次开始:“Cheery”。但后查找这个节点的父节点,并添加到路径中。在我们的例子中,这个父节点是“Red”。如果我们知道“Red”是“Cherry”的父节点。
<?php
// $node 是我们要查找路径的那个节点的名字
function get_path($node) {
// 查找这个节点的父节点
$result = mysql_query('SELECT parent FROM tree '.
'WHERE title="'.$node.'";');
$row = mysql_fetch_array($result);
// 在这个array [5] 中保存数组
$path = array();
// 如果 $node 不是根节点,那么继续
if ($row['parent']!='') {
// $node 的路径的最后一部分是$node父节点的名称
$path[] = $row['parent'];
// 我们要添加这个节点的父节点的路径到现在这个路径
$path = array_merge(get_path($row['parent']), $path);
}
// 返回路径
return $path;
}
?>
这个函数现在返回了指定节点的路径。他把路径作为数组返回,这样我们可以使用print_r(get_path('Cherry')); 来显示,其结果是:
Array
(
[0] => Food
[1] => Fruit
[2] => Red
)
不足
正如我们所见,这确实是一个很好的方法。他很容易理解,同时代码也很简单。但是邻接列表模型的缺点在哪里呢?在大多数编程语言中,他运行很慢,效率很差。这主要是“递归”造成的。我们每次查询节点都要访问数据库。
每次数据库查询都要花费一些时间,这让函数处理庞大的树时会十分慢。
造成这个函数不是太快的第二个原因可能是你使用的语言。不像Lisp这类语言,大多数语言不是针对递归函数设计的。对于每个节点,函数都要调用他自己,产生新的实例。这样,对于一个4层的树,你可能同时要运行4个函数副本。对于每个函数都要占用一块内存并且需要一定的时间初始化,这样处理大树时递归就很慢了。
改进前序遍历树
现在,让我们看另一种存储树的方法。递归可能会很慢,所以我们就尽量不使用递归函数。我们也想尽量减少数据库查询的次数。最好是每次只需要查询一次。
我们先把树按照水平方式摆开。从根节点开始(“Food”),然后他的左边写上1。然后按照树的顺序(从上到下)给“Fruit”的左边写上2。这样,你沿着树的边界走啊走(这就是“遍历”),然后同时在每个节点的左边和右边写上数字。最后,我们回到了根节点“Food”在右边写上18。下面是标上了数字的树,同时把遍历的顺序用箭头标出来了。
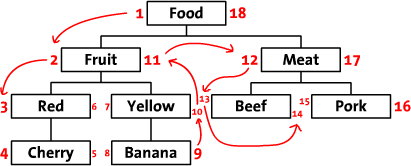
我们称这些数字为左值和右值(如,“Food”的左值是1,右值是18)。正如你所见,这些数字按时了每个节点之间的关系。因为“Red”有3和6两个值,所以,它是有拥有1-18值的“Food”节点的后续。同样的,我们可以推断所有左值大于2并且右值小于11的节点,都是有2-11的“Food”节点的后续。这样,树的结构就通过左值和右值储存下来了。这种数遍整棵树算节点的方法叫做“改进前序遍历树”算法。
在继续前,我们先看看我们的表格里的这些值:
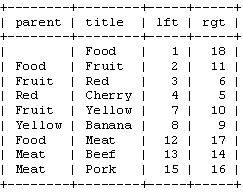
注意单词“left”和“right”在SQL中有特殊的含义。因此,我们只能用“lft”和“rgt”来表示这两个列。(译注——其实Mysql中可以用“`”来表示,如“`left`”,MSSQL中可以用“[]”括出,如“[left]”,这样就不会和关键词冲突了。)同样注意这里我们已经不需要“parent”列了。我们只需要使用lft和rgt就可以存储树的结构。
获取树
如果你要通过左值和右值来显示这个树的话,你要首先标识出你要获取的那些节点。例如,如果你想获得“Fruit”子树,你要选择那些左值在2到11的节点。用SQL语句表达:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;
这个会返回:

好吧,现在整个树都在一个查询中了。现在就要像前面的递归函数那样显示这个树,我们要加入一个ORDER BY子句在这个查询中。如果你从表中添加和删除行,你的表可能就顺序不对了,我们因此需要按照他们的左值来进行排序。
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
就只剩下缩进的问题了。
要显示树状结构,子节点应该比他们的父节点稍微缩进一些。我们可以通过保存一个右值的一个栈。每次你从一个节点的子节点开始时,你把这个节点的右值添加到栈中。你也知道子节点的右值都比父节点的右值小,这样通过比较当前节点和栈中的前一个节点的右值,你可以判断你是不是在显示这个父节点的子节点。当你显示完这个节点,你就要把他的右值从栈中删除。要获得当前节点的层数,只要数一下栈中的元素。
<?php
function display_tree($root) {
// 获得$root节点的左边和右边的值
$result = mysql_query('SELECT lft, rgt FROM tree '.
'WHERE title="'.$root.'";');
$row = mysql_fetch_array($result);
// 以一个空的$right栈开始
$right = array();
// 现在,获得$root节点的所有后序
$result = mysql_query('SELECT title, lft, rgt FROM tree '.
'WHERE lft BETWEEN '.$row['lft'].' AND '.
$row['rgt'].' ORDER BY lft ASC;');
// 显示每一行
while ($row = mysql_fetch_array($result)) {
// 检查栈里面有没有元素
if (count($right)>0) {
// 检查我们是否需要从栈中删除一个节点
while ($right[count($right)-1]<$row['rgt']) {
array_pop($right);
}
}
// 显示缩进的节点标题
echo str_repeat(' ',count($right)).$row['title']."\n";
// 把这个节点添加到栈中
$right[] = $row['rgt'];
}
}
?>
如果运行这段代码,你可以获得和上一部分讨论的递归函数一样的结果。而这个函数可能会更快一点:他不采用递归而且只是用了两个查询
节点的路径
有了新的算法,我们还要另找一种新的方法来获得指定节点的路径。这样,我们就需要这个节点的祖先的一个列表。
由于新的表结构,这不需要花太多功夫。你可以看一下,例如,4-5的“Cherry”节点,你会发现祖先的左值都小于4,同时右值都大于5。这样,我们就可以使用下面这个查询:
SELECT title FROM tree WHERE lft < 4 AND rgt > 5 ORDER BY lft ASC;
注意,就像前面的查询一样,我们必须使用一个ORDER BY子句来对节点排序。这个查询将返回:
+-------+
| title |
+-------+
| Food |
| Fruit |
| Red |
+-------+
我们现在只要把各行连起来,就可以得到“Cherry”的路径了。
有多少个后续节点?How Many Descendants
如果你给我一个节点的左值和右值,我就可以告诉你他有多少个后续节点,只要利用一点点数学知识。
因为每个后续节点依次会对这个节点的右值增加2,所以后续节点的数量可以这样计算:
descendants = (right – left - 1) / 2
利用这个简单的公式,我可以立刻告诉你2-11的“Fruit”节点有4个后续节点,8-9的“Banana”节点只是1个子节点,而不是父节点。
自动化树遍历
现在你对这个表做一些事情,我们应该学习如何自动的建立表了。这是一个不错的练习,首先用一个小的树,我们也需要一个脚本来帮我们完成对节点的计数。
让我们先写一个脚本用来把一个邻接列表转换成前序遍历树表格。
<?php
function rebuild_tree($parent, $left) {
// 这个节点的右值是左值加1
$right = $left+1;
// 获得这个节点的所有子节点
$result = mysql_query('SELECT title FROM tree '.
'WHERE parent="'.$parent.'";');
while ($row = mysql_fetch_array($result)) {
// 对当前节点的每个子节点递归执行这个函数
// $right 是当前的右值,它会被rebuild_tree函数增加
$right = rebuild_tree($row['title'], $right);
}
// 我们得到了左值,同时现在我们已经处理这个节点我们知道右值的子节点
mysql_query('UPDATE tree SET lft='.$left.', rgt='.
$right.' WHERE title="'.$parent.'";');
// 返回该节点的右值+1
return $right+1;
}
?>
这是一个递归函数。你要从rebuild_tree('Food',1); 开始,这个函数就会获取所有的“Food”节点的子节点。
如果没有子节点,他就直接设置它的左值和右值。左值已经给出了,1,右值则是左值加1。如果有子节点,函数重复并且返回最后一个右值。这个右值用来作为“Food”的右值。
递归让这个函数有点复杂难于理解。然而,这个函数确实得到了同样的结果。他沿着树走,添加每一个他看见的节点。你运行了这个函数之后,你会发现左值和右值和预期的是一样的(一个快速检验的方法:根节点的右值应该是节点数量的两倍)。
添加一个节点
我们如何给这棵树添加一个节点?有两种方式:在表中保留“parent”列并且重新运行rebuild_tree() 函数——一个很简单但却不是很优雅的函数;或者你可以更新所有新节点右边的节点的左值和右值。
第一个想法比较简单。你使用邻接列表方法来更新,同时使用改进前序遍历树来查询。如果你想添加一个新的节点,你只需要把节点插入表格,并且设置好parent列。然后,你只需要重新运行rebuild_tree() 函数。这做起来很简单,但是对大的树效率不高。
第二种添加和删除节点的方法是更新新节点右边的所有节点。让我们看一下例子。我们要添加一种新的水果——“Strawberry”,作为“Red”的最后一个子节点。首先,我们要腾出一个空间。“Red”的右值要从6变成8,7-10的“Yellow”节点要变成9-12,如此类推。更新“Red”节点意味着我们要把所有左值和右值大于5的节点加上2。
我们用一下查询:
UPDATE tree SET rgt=rgt+2 WHERE rgt>5;
UPDATE tree SET lft=lft+2 WHERE lft>5;
现在我们可以添加一个新的节点“Strawberry”来填补这个新的空间。这个节点左值为6右值为7。
INSERT INTO tree SET lft=6, rgt=7, title='Strawberry';
如果我们运行display_tree() 函数,我们将发现我们新的“Strawberry”节点已经成功地插入了树中:
Food
Fruit
Red
Cherry
Strawberry
Yellow
Banana
Meat
Beef
Pork
缺点
首先,改进前序遍历树算法看上去很难理解。它当然没有邻接列表方法简单。然而,一旦你习惯了左值和右值这两个属性,他就会变得清晰起来,你可以用这个技术来完成临街列表能完成的所有事情,同时改进前序遍历树算法更快。当然,更新树需要很多查询,要慢一点,但是取得节点却可以只用一个查询。
总结
你现在已经对两种在数据库存储树方式熟悉了吧。虽然在我这儿改进前序遍历树算法性能更好,但是也许在你特殊的情况下邻接列表方法可能表现更好一些。这个就留给你自己决定了
最后一点:就像我已经说得我部推荐你使用节点的标题来引用这个节点。你应该遵循数据库标准化的基本规则。我没有使用数字标识是因为用了之后例子就比较难读。
进一步阅读
数据库指导 Joe Celko写的更多关于SQL数据库中的树的问题:
http://searchdatabase.techtarget.com/tip/1,289483,sid13_gci537290,00.html [6]
另外两种处理层次数据的方法:
http://www.evolt.org/article/Four_ways_to_work_with_hierarchical_data/17/4047/index.html [7]
Xindice, “本地XML数据库”:
http://xml.apache.org/xindice/ [8]
递归的一个解释:
http://www.strath.ac.uk/IT/Docs/Ccourse/subsection3_9_5.html [9]
[1] /glossary.php?q=C#term_28
[2] /glossary.php?q=X#term_3
[3] /glossary.php?q=P#term_1
[4] /glossary.php?q=P#term_50
[5] /glossary.php?q=%23#term_72
[6] http://searchdatabase.techtarget.com/tip/1,289483,sid13_gci537290,00.html
[7] http://www.evolt.org/article/Four_ways_to_work_with_hierarchical_data/17/4047/index.html
[8] http://xml.apache.org/xindice/
[9] http://www.strath.ac.uk/IT/Docs/Ccourse/subsection3_9_5.html
标题:预排序遍历树算法
文章来自这里的3楼:http://bbs.chinaunix.net/viewthr ... 1%26filter%3Ddigest
可能作者参考了这里:http://dev.mysql.com/tech-resour ... rarchical-data.html
产品分类,多级的树状结构的论坛,邮件列表等许多地方我们都会遇到这样的问题:如何存储多级结构的数据?在PHP的应用中,提供后台数据存储的通常是关系型数据库,它能够保存大量的数据,提供高效的数据检索和更新服务。然而关系型数据的基本形式是纵横交错的表,是一个平面的结构,如果要将多级树状结构存储在关系型数据库里就需要进行合理的翻译工作。接下来我会将自己的所见所闻和一些实用的经验和大家探讨一下:
层级结构的数据保存在平面的数据库中基本上有两种常用设计方法:
1、毗邻目录模式(adjacency list model)
2、预排序遍历树算法(modified preorder tree traversal algorithm)
我不是计算机专业的,也没有学过什么数据结构的东西,所以这两个名字都是我自己按照字面的意思翻的,如果说错了还请多多指教。
这两个东西听着好像很吓人,其实非常容易理解。这里我用一个简单食品目录作为我们的示例数据。
我们的数据结构是这样的
以下是代码:
CODE:[Copy to clipboard]Food
|---Fruit
| |---Red
| | |--Cherry
| |---Yellow
| |--Banana
|---Meat
|--Beef
|--Pork
为了照顾那些英文一塌糊涂的PHP爱好者
Food:食物
Fruit:水果
Red:红色
Cherry:樱桃
Yellow:黄色
Banana:香蕉
Meat:肉类
Beef:牛肉
Pork:猪肉
毗邻目录模式(adjacency list model)
这种模式我们经常用到,很多的教程和书中也介绍过。我们通过给每个节点增加一个属性 parent 来表示这个节点的父节点从而将整个树状结构通过平面的表描述出来。根据这个原则,例子中的数据可以转化成如下的表:
以下是代码:
CODE:[Copy to clipboard]+-----------------------+
| parent | name |
+-----------------------+
| | Food |
| Food | Fruit |
| Fruit | Green |
| Green | Pear |
| Fruit | Red |
| Red | Cherry |
| Fruit | Yellow |
| Yellow | Banana |
| Food | Meat |
| Meat | Beef |
| Meat | Pork |
+-----------------------+
我们看到 Pear 是Green的一个子节点,Green是Fruit的一个子节点。而根节点'Food'没有父节点。 为了简单地描述这个问题, 这个例子中只用了name来表示一个记录。 在实际的数据库中,你需要用数字的id来标示每个节点,数据库的表结构大概应该像这样:id, parent_id, name, description。
有了这样的表我们就可以通过数据库保存整个多级树状结构了。
显示多级树
如果我们需要显示这样的一个多级结构需要一个递归函数。
以下是代码:
CODE:[Copy to clipboard]<?php
// $parent is the parent of the children we want to see
// $level is increased when we go deeper into the tree,
// used to display a nice indented tree
function display_children($parent, $level)
{
// 获得一个 父节点 $parent 的所有子节点
$result = mysql_query('SELECT name FROM tree '.
'WHERE parent="'.$parent.'";');
// 显示每个子节点
while ($row = mysql_fetch_array($result))
{
// 缩进显示节点名称
echo str_repeat(' ',$level).$row['name']."n";
//再次调用这个函数显示子节点的子节点
display_children($row['name'], $level+1);
}
}
?>;
对整个结构的根节点(Food)使用这个函数就可以打印出整个多级树结构,由于Food是根节点它的父节点是空的,所以这样调用: display_children('',0)。将显示整个树的内容:
CODE:[Copy to clipboard]Food
Fruit
Red
Cherry
Yellow
Banana
Meat
Beef
Pork
如果你只想显示整个结构中的一部分,比如说水果部分,就可以这样调用:display_children('Fruit',0);
几乎使用同样的方法我们可以知道从根节点到任意节点的路径。比如 Cherry 的路径是 "Food >; Fruit >; Red"。 为了得到这样的一个路径我们需要从最深的一级"Cherry"开始, 查询得到它的父节点"Red"把它添加到路径中, 然后我们再查询Red的父节点并把它也添加到路径中,以此类推直到最高层的"Food"
以下是代码:
CODE:[Copy to clipboard]<?php
// $node 是那个最深的节点
function get_path($node)
{
// 查询这个节点的父节点
$result = mysql_query('SELECT parent FROM tree '.
'WHERE name="'.$node.'";');
$row = mysql_fetch_array($result);
// 用一个数组保存路径
$path = array();
// 如果不是根节点则继续向上查询
// (根节点没有父节点)
if ($row['parent']!='')
{
// the last part of the path to $node, is the name
// of the parent of $node
$path[] = $row['parent'];
// we should add the path to the parent of this node
// to the path
$path = array_merge(get_path($row['parent']), $path);
}
// return the path
return $path;
}
?>;
如果对"Cherry"使用这个函数:print_r(get_path('Cherry')),就会得到这样的一个数组了:
CODE:[Copy to clipboard]Array
(
[0] =>; Food
[1] =>; Fruit
[2] =>; Red
)
接下来如何把它打印成你希望的格式,就是你的事情了。
缺点:
这种方法很简单,容易理解,好上手。但是也有一些缺点。主要是因为运行速度很慢,由于得到每个节点都需要进行数据库查询,数据量大的时候要进行很多查询才能完成一个树。另外由于要进行递归运算,递归的每一级都需要占用一些内存所以在空间利用上效率也比较低。
现在让我们看一看另外一种不使用递归计算,更加快速的方法,这就是预排序遍历树算法(modified preorder tree traversal algorithm)
这种方法大家可能接触的比较少,初次使用也不像上面的方法容易理解,但是由于这种方法不使用递归查询算法,有更高的查询效率。
我们首先将多级数据按照下面的方式画在纸上,在根节点Food的左侧写上 1 然后沿着这个树继续向下 在 Fruit 的左侧写上 2 然后继续前进,沿着整个树的边缘给每一个节点都标上左侧和右侧的数字。最后一个数字是标在Food 右侧的 18。 在下面的这张图中你可以看到整个标好了数字的多级结构。(没有看懂?用你的手指指着数字从1数到18就明白怎么回事了。还不明白,再数一遍,注意移动你的手指)。
这些数字标明了各个节点之间的关系,"Red"的号是3和6,它是 "Food" 1-18 的子孙节点。 同样,我们可以看到 所有左值大于2和右值小于11的节点 都是"Fruit" 2-11 的子孙节点
以下是代码:
CODE:[Copy to clipboard] 1 Food 18
+-------------------------------------------+
2 Fruit 11 12 Meat 17
+------------------------+ +-----------------------+
3 Red 6 7 Yellow 10 13 Beef 14 15 Pork 16
4 Cherry 5 8 Banana 9
这样整个树状结构可以通过左右值来存储到数据库中。继续之前,我们看一看下面整理过的数据表。
以下是代码:
CODE:[Copy to clipboard]+-----------------------+-----+-----+
| parent | name | lft | rgt |
+-----------------------+-----+-----+
| | Food | 1 | 18 |
| Food | Fruit | 2 | 11 |
| Fruit | Red | 3 | 6 |
| Red | Cherry | 4 | 5 |
| Fruit | Yellow | 7 | 10 |
| Yellow | Banana | 8 | 9 |
| Food | Meat | 12 | 17 |
| Meat | Beef | 13 | 14 |
| Meat | Pork | 15 | 16 |
+-----------------------+-----+-----+
注意:由于"left"和"right"在 SQL中有特殊的意义,所以我们需要用"lft"和"rgt"来表示左右字段。 另外这种结构中不再需要"parent"字段来表示树状结构。也就是 说下面这样的表结构就足够了。
以下是代码:
CODE:[Copy to clipboard]+------------+-----+-----+
| name | lft | rgt |
+------------+-----+-----+
| Food | 1 | 18 |
| Fruit | 2 | 11 |
| Red | 3 | 6 |
| Cherry | 4 | 5 |
| Yellow | 7 | 10 |
| Banana | 8 | 9 |
| Meat | 12 | 17 |
| Beef | 13 | 14 |
| Pork | 15 | 16 |
+------------+-----+-----+
好了我们现在可以从数据库中获取数据了,例如我们需要得到"Fruit"项下的所有所有节点就可以这样写查询语句:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;
这个查询得到了以下的结果。
以下是代码:
CODE:[Copy to clipboard]+------------+-----+-----+
| name | lft | rgt |
+------------+-----+-----+
| Fruit | 2 | 11 |
| Red | 3 | 6 |
| Cherry | 4 | 5 |
| Yellow | 7 | 10 |
| Banana | 8 | 9 |
+------------+-----+-----+
看到了吧,只要一个查询就可以得到所有这些节点。为了能够像上面的递归函数那样显示整个树状结构,我们还需要对这样的查询进行排序。用节点的左值进行排序:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
剩下的问题如何显示层级的缩进了。
以下是代码:
CODE:[Copy to clipboard]<?php
function display_tree($root)
{
// 得到根节点的左右值
$result = mysql_query('SELECT lft, rgt FROM tree '.'WHERE name="'.$root.'";');
$row = mysql_fetch_array($result);
// 准备一个空的右值堆栈
$right = array();
// 获得根基点的所有子孙节点
$result = mysql_query('SELECT name, lft, rgt FROM tree '.
'WHERE lft BETWEEN '.$row['lft'].' AND '.
$row['rgt'].' ORDER BY lft ASC;');
// 显示每一行
while ($row = mysql_fetch_array($result))
{
// only check stack if there is one
if (count($right)>;0)
{
// 检查我们是否应该将节点移出堆栈
while ($right[count($right)-1]<$row['rgt'])
{
array_pop($right);
}
}
// 缩进显示节点的名称
echo str_repeat(' ',count($right)).$row['name']."n";
// 将这个节点加入到堆栈中
$right[] = $row['rgt'];
}
}
?>;
如果你运行一下以上的函数就会得到和递归函数一样的结果。只是我们的这个新的函数可能会更快一些,因为只有2次数据库查询。
要获知一个节点的路径就更简单了,如果我们想知道Cherry 的路径就利用它的左右值4和5来做一个查询。
SELECT name FROM tree WHERE lft < 4 AND rgt >; 5 ORDER BY lft ASC;
这样就会得到以下的结果:
以下是代码:
CODE:[Copy to clipboard]+------------+
| name |
+------------+
| Food |
| Fruit |
| Red |
+------------+
那么某个节点到底有多少子孙节点呢?很简单,子孙总数=(右值-左值-1)/2
descendants = (right – left - 1) / 2
不相信?自己算一算啦。
用这个简单的公式,我们可以很快的算出"Fruit 2-11"节点有4个子孙节点,而"Banana 8-9"节点没有子孙节点,也就是说它不是一个父节点了。
很神奇吧?虽然我已经多次用过这个方法,但是每次这样做的时候还是感到很神奇。
这的确是个很好的办法,但是有什子孙总数=(右值-左值-1)/2
descendants = (right – left - 1) / 2
不相信?自己算一算啦。
用这个简单的公式,我们可以很快的算出"Fruit 2-11"节点有4个子孙节点,而"Banana 8-9"节点没有子孙节点,也就是说它不是一个父节点了。
很神奇吧?虽然我已经多次用过这个方法,但是每次这样做的时候还是感到很神奇。
这的确是个很好的办法,但是有什么办法能够帮我们建立这样有左右值的数据表呢?这里再介绍一个函数给大家,这个函数可以将name和parent结构的表自动转换成带有左右值的数据表。
以下是代码:
CODE:[Copy to clipboard]<?php
function rebuild_tree($parent, $left) {
// the right value of this node is the left value + 1
$right = $left+1;
// get all children of this node
$result = mysql_query('SELECT name FROM tree '.
'WHERE parent="'.$parent.'";');
while ($row = mysql_fetch_array($result)) {
// recursive execution of this function for each
// child of this node
// $right is the current right value, which is
// incremented by the rebuild_tree function
$right = rebuild_tree($row['name'], $right);
}
// we've got the left value, and now that we've processed
// the children of this node we also know the right value
mysql_query('UPDATE tree SET lft='.$left.', rgt='.
$right.' WHERE name="'.$parent.'";');
// return the right value of this node + 1
return $right+1;
}
?>;
当然这个函数是一个递归函数,我们需要从根节点开始运行这个函数来重建一个带有左右值的树
rebuild_tree('Food',1);
这个函数看上去有些复杂,但是它的作用和手工对表进行编号一样,就是将立体多层结构的转换成一个带有左右值的数据表。
那么对于这样的结构我们该如何增加,更新和删除一个节点呢?
增加一个节点一般有两种方法:
第一种,保留原有的name 和parent结构,用老方法向数据中添加数据,每增加一条数据以后使用rebuild_tree函数对整个结构重新进行一次编号。
第二种,效率更高的办法是改变所有位于新节点右侧的数值。举例来说:我们想增加一种新的水果"Strawberry"(草莓)它将成为"Red"节点的最后一个子节点。首先我们需要为它腾出一些空间。"Red"的右值应当从6改成8,"Yellow 7-10 "的左右值则应当改成 9-12。 依次类推我们可以得知,如果要给新的值腾出空间需要给所有左右值大于5的节点 (5 是"Red"最后一个子节点的右值) 加上2。 所以我们这样进行数据库操作:
UPDATE tree SET rgt=rgt+2 WHERE rgt>;5;
UPDATE tree SET lft=lft+2 WHERE lft>;5;
这样就为新插入的值腾出了空间,现在可以在腾出的空间里建立一个新的数据节点了, 它的左右值分别是6和7
INSERT INTO tree SET lft=6, rgt=7, name='Strawberry';
再做一次查询看看吧!怎么样?很快吧。
好了,现在你可以用两种不同的方法设计你的多级数据库结构了,采用何种方式完全取决于你个人的判断,但是对于层次多数量大的结构我更喜欢第二种方法。如果查询量较小但是需要频繁添加和更新的数据,则第一种方法更为简便。
另外,如果数据库支持的话 你还可以将rebuild_tree()和 腾出空间的操作写成数据库端的触发器函数, 在插入和更新的时候自动执行, 这样可以得到更好的运行效率, 而且你添加新节点的SQL语句会变得更加简单。
标题:基于嵌套模型的无限级分类
http://bbs.dvbbs.net/dispbbs.asp?boardID=1&ID=1272297
根据国外的: Nested Set Model of Trees
http://searchoracle.techtarget.com/tip/1,289483,sid13_gci537290,00.html
http://www.dbmsmag.com/9603d06.html
我觉得奇怪的是,这个SQL来实现树的算法早在1996、1999年就提出了,而为什么在国内的ASP系统中都没有见过用此来实现的?其实此算法的无限级才是真正是“无限”即结点数目可以达2^32=4G个(只局限于lft和rgt的取值范围),而且更新树的时候,只需要维护lft和rgt两个字段的整型数据(要知道整型数据的运算速度是最快的)。
而目前国内大家都是用的一个字符串字段来保存结点的路径,SQL对可索引字符串的长度是有限(Access:255,MSSQL:8000),但如果用备注类型来做的话,就根本没得什么索引和效率可言了。
演示测试地址:
http://www.lxasp.com/Test_NestedTree.asp
'数据表如下:
'CREATE TABLE [TreeNode] (
' [tn_id] [int] IDENTITY (1, 1) NOT NULL ,
' [tn_name] [nvarchar] (50) NULL ,
' [tn_lft] [int] NULL ,
' [tn_rgt] [int] NULL ,
' CONSTRAINT [PK_TreeNode] PRIMARY KEY CLUSTERED
' (
' [tn_id]
' ) ON [PRIMARY]
') ON [PRIMARY]
'GO
Public startime,endtime,conn,connstr,rs,sql,sqlcount
startime=Timer()
sqlcount=0
Set conn = Server.CreateObject("ADODB.Connection")
connstr="Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" & Server.MapPath("test.mdb")
conn.Open connstr
'############################################################
'* 名称: 插入结点到树
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function InsertNew(Parent_ID , NewName)
Dim p_lft,p_rgt
SQL = "SELECT * FROM TreeNode WHERE tn_id="&Parent_ID
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,3 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
'不存在Parent_ID,则出错
Else
rs.MoveFirst
p_lft=rs("tn_lft")
p_rgt=rs("tn_rgt")
conn.Execute "UPDATE TreeNode SET tn_rgt=tn_rgt+2 WHERE tn_rgt>" & CStr(p_rgt-1)
sqlcount=sqlcount+1
conn.Execute "UPDATE TreeNode SET tn_lft=tn_lft+2 WHERE tn_lft>" & CStr(p_rgt-1)
sqlcount=sqlcount+1
rs.AddNew
rs("tn_lft")=p_rgt
rs("tn_rgt")=p_rgt+1
rs("tn_name")=NewName
rs.Update
InsertNew=p_rgt+1
End If
rs.Close
Set rs = Nothing
End Function
'############################################################
'* 名称: 显示整棵树
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function ShowTree()
Dim stackd,stkpos,STACKMAX
Dim i,j
i=0
j=0
STACKMAX=100
stkpos=0
SQL = "SELECT * FROM TreeNode ORDER BY tn_lft ASC"
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Else
ReDim stackd(0,STACKMAX)
rs.MoveFirst
Do Until rs.EOF
If stkpos=0 Then
'至少要有一个结点,如果是网站,那么就以该网站的名称作为根结点
Response.Write rs("tn_name") & vbCrLf
End If
If stkpos>0 Then
'出栈
Do While stackd(0,stkpos-1)<rs("tn_rgt")
stkpos=stkpos-1
Loop
Response.Write Space(stkpos*4) & "(" & rs("tn_id") & ")" & rs("tn_name") & vbCrLf
End If
'进栈
stkpos=stkpos+1
If stkpos-1>STACKMAX Then ReDim Preserve stackd(0,stkpos-1+STACKMAX)
stackd(0,stkpos-1)=rs("tn_rgt")
rs.MoveNext
Loop
End If
rs.Close
Set rs = Nothing
End Function
'############################################################
'* 名称: 删除结点以及它的子树
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function DeleteNode(NodeID)
Dim lft,rgt,diff
SQL = "SELECT * FROM TreeNode WHERE tn_id="&NodeID
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Exit Function
Else
rs.MoveFirst
lft=rs("tn_lft")
rgt=rs("tn_rgt")
End If
rs.Close
Set rs = Nothing
diff=rgt-lft+1
conn.Execute "DELETE FROM TreeNode WHERE tn_lft>=" & lft & " AND tn_rgt<= " & rgt & " "
conn.Execute "UPDATE TreeNode SET tn_lft=tn_lft-" & diff & " WHERE tn_lft>" & lft & " "
conn.Execute "UPDATE TreeNode SET tn_rgt=tn_rgt-" & diff & " WHERE tn_rgt>=" & rgt & " "
End Function
'############################################################
'* 名称: 获得某结点的路径
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function GetNodePath(NodeID)
Dim lft,rgt
GetNodePath=""
SQL = "SELECT A.tn_name,A.tn_lft,A.tn_rgt FROM TreeNode A ,TreeNode B WHERE (A.tn_lft<=B.tn_lft) AND (A.tn_rgt>=B.tn_rgt) AND B.tn_id=" & NodeID & " ORDER BY A.tn_lft"
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Else
rs.MoveFirst
Do Until rs.EOF
Response.Write rs(0).Value & "\"
rs.MoveNext
Loop
End If
rs.Close
Set rs = Nothing
End Function
'############################################################
'* 名称: 获得某结点的直属子结点
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function GetChildNodes(RootID)
Dim tmpview
'如果为了提速,可以将下面的SQL语句作为视图
tmpview="SELECT a.tn_id AS pnt_id, a.tn_name AS pnt_name, b.tn_id AS sub_id, b.tn_name AS sub_name, b.tn_lft, b.tn_rgt " & _
"FROM TreeNode AS a, TreeNode AS b " & _
"WHERE b.tn_lft BETWEEN a.tn_lft AND a.tn_rgt AND NOT EXISTS " & _
"(SELECT * FROM TreeNode AS c " & _
"WHERE c.tn_lft BETWEEN a.tn_lft AND a.tn_rgt " & _
"AND b.tn_lft BETWEEN c.tn_lft AND c.tn_rgt " & _
"AND c.tn_id NOT IN (a.tn_id,b.tn_id) ) "
SQL="SELECT DISTINCT s1.sub_id,s1.sub_name " & _
"FROM (" & tmpview & ") as s1,(" & tmpview & ") as s2,TreeNode as o1 " & _
"WHERE s1.pnt_id=o1.tn_id " & _
"AND s2.pnt_id=s1.pnt_id " & _
"AND s1.sub_id<>s2.sub_id " & _
"AND s2.tn_lft <= s1.tn_lft " & _
"AND o1.tn_id=" & RootID & " "
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Else
rs.MoveFirst
Do Until rs.EOF
Response.Write "(" & rs(0) & ")" & rs(1) & vbCrLf
rs.MoveNext
Loop
End If
rs.Close
Set rs = Nothing
End Function
以下是代码:
CODE:[Copy to clipboard]<?php
function rebuild_tree($parent, $left) {
// the right value of this node is the left value + 1
$right = $left+1;
// get all children of this node
$result = mysql_query('SELECT name FROM tree '.
'WHERE parent="'.$parent.'";');
while ($row = mysql_fetch_array($result)) {
// recursive execution of this function for each
// child of this node
// $right is the current right value, which is
// incremented by the rebuild_tree function
$right = rebuild_tree($row['name'], $right);
}
// we've got the left value, and now that we've processed
// the children of this node we also know the right value
mysql_query('UPDATE tree SET lft='.$left.', rgt='.
$right.' WHERE name="'.$parent.'";');
// return the right value of this node + 1
return $right+1;
}
?>;
当然这个函数是一个递归函数,我们需要从根节点开始运行这个函数来重建一个带有左右值的树
rebuild_tree('Food',1);
这个函数看上去有些复杂,但是它的作用和手工对表进行编号一样,就是将立体多层结构的转换成一个带有左右值的数据表。
那么对于这样的结构我们该如何增加,更新和删除一个节点呢?
增加一个节点一般有两种方法:
第一种,保留原有的name 和parent结构,用老方法向数据中添加数据,每增加一条数据以后使用rebuild_tree函数对整个结构重新进行一次编号。
第二种,效率更高的办法是改变所有位于新节点右侧的数值。举例来说:我们想增加一种新的水果"Strawberry"(草莓)它将成为"Red"节点的最后一个子节点。首先我们需要为它腾出一些空间。"Red"的右值应当从6改成8,"Yellow 7-10 "的左右值则应当改成 9-12。 依次类推我们可以得知,如果要给新的值腾出空间需要给所有左右值大于5的节点 (5 是"Red"最后一个子节点的右值) 加上2。 所以我们这样进行数据库操作:
UPDATE tree SET rgt=rgt+2 WHERE rgt>;5;
UPDATE tree SET lft=lft+2 WHERE lft>;5;
这样就为新插入的值腾出了空间,现在可以在腾出的空间里建立一个新的数据节点了, 它的左右值分别是6和7
INSERT INTO tree SET lft=6, rgt=7, name='Strawberry';
再做一次查询看看吧!怎么样?很快吧。
好了,现在你可以用两种不同的方法设计你的多级数据库结构了,采用何种方式完全取决于你个人的判断,但是对于层次多数量大的结构我更喜欢第二种方法。如果查询量较小但是需要频繁添加和更新的数据,则第一种方法更为简便。
另外,如果数据库支持的话 你还可以将rebuild_tree()和 腾出空间的操作写成数据库端的触发器函数, 在插入和更新的时候自动执行, 这样可以得到更好的运行效率, 而且你添加新节点的SQL语句会变得更加简单。
标题:基于嵌套模型的无限级分类
http://bbs.dvbbs.net/dispbbs.asp?boardID=1&ID=1272297
根据国外的: Nested Set Model of Trees
http://searchoracle.techtarget.com/tip/1,289483,sid13_gci537290,00.html
http://www.dbmsmag.com/9603d06.html
我觉得奇怪的是,这个SQL来实现树的算法早在1996、1999年就提出了,而为什么在国内的ASP系统中都没有见过用此来实现的?其实此算法的无限级才是真正是“无限”即结点数目可以达2^32=4G个(只局限于lft和rgt的取值范围),而且更新树的时候,只需要维护lft和rgt两个字段的整型数据(要知道整型数据的运算速度是最快的)。
而目前国内大家都是用的一个字符串字段来保存结点的路径,SQL对可索引字符串的长度是有限(Access:255,MSSQL:8000),但如果用备注类型来做的话,就根本没得什么索引和效率可言了。
演示测试地址:
http://www.lxasp.com/Test_NestedTree.asp
'数据表如下:
'CREATE TABLE [TreeNode] (
' [tn_id] [int] IDENTITY (1, 1) NOT NULL ,
' [tn_name] [nvarchar] (50) NULL ,
' [tn_lft] [int] NULL ,
' [tn_rgt] [int] NULL ,
' CONSTRAINT [PK_TreeNode] PRIMARY KEY CLUSTERED
' (
' [tn_id]
' ) ON [PRIMARY]
') ON [PRIMARY]
'GO
Public startime,endtime,conn,connstr,rs,sql,sqlcount
startime=Timer()
sqlcount=0
Set conn = Server.CreateObject("ADODB.Connection")
connstr="Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" & Server.MapPath("test.mdb")
conn.Open connstr
'############################################################
'* 名称: 插入结点到树
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function InsertNew(Parent_ID , NewName)
Dim p_lft,p_rgt
SQL = "SELECT * FROM TreeNode WHERE tn_id="&Parent_ID
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,3 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
'不存在Parent_ID,则出错
Else
rs.MoveFirst
p_lft=rs("tn_lft")
p_rgt=rs("tn_rgt")
conn.Execute "UPDATE TreeNode SET tn_rgt=tn_rgt+2 WHERE tn_rgt>" & CStr(p_rgt-1)
sqlcount=sqlcount+1
conn.Execute "UPDATE TreeNode SET tn_lft=tn_lft+2 WHERE tn_lft>" & CStr(p_rgt-1)
sqlcount=sqlcount+1
rs.AddNew
rs("tn_lft")=p_rgt
rs("tn_rgt")=p_rgt+1
rs("tn_name")=NewName
rs.Update
InsertNew=p_rgt+1
End If
rs.Close
Set rs = Nothing
End Function
'############################################################
'* 名称: 显示整棵树
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function ShowTree()
Dim stackd,stkpos,STACKMAX
Dim i,j
i=0
j=0
STACKMAX=100
stkpos=0
SQL = "SELECT * FROM TreeNode ORDER BY tn_lft ASC"
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Else
ReDim stackd(0,STACKMAX)
rs.MoveFirst
Do Until rs.EOF
If stkpos=0 Then
'至少要有一个结点,如果是网站,那么就以该网站的名称作为根结点
Response.Write rs("tn_name") & vbCrLf
End If
If stkpos>0 Then
'出栈
Do While stackd(0,stkpos-1)<rs("tn_rgt")
stkpos=stkpos-1
Loop
Response.Write Space(stkpos*4) & "(" & rs("tn_id") & ")" & rs("tn_name") & vbCrLf
End If
'进栈
stkpos=stkpos+1
If stkpos-1>STACKMAX Then ReDim Preserve stackd(0,stkpos-1+STACKMAX)
stackd(0,stkpos-1)=rs("tn_rgt")
rs.MoveNext
Loop
End If
rs.Close
Set rs = Nothing
End Function
'############################################################
'* 名称: 删除结点以及它的子树
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function DeleteNode(NodeID)
Dim lft,rgt,diff
SQL = "SELECT * FROM TreeNode WHERE tn_id="&NodeID
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Exit Function
Else
rs.MoveFirst
lft=rs("tn_lft")
rgt=rs("tn_rgt")
End If
rs.Close
Set rs = Nothing
diff=rgt-lft+1
conn.Execute "DELETE FROM TreeNode WHERE tn_lft>=" & lft & " AND tn_rgt<= " & rgt & " "
conn.Execute "UPDATE TreeNode SET tn_lft=tn_lft-" & diff & " WHERE tn_lft>" & lft & " "
conn.Execute "UPDATE TreeNode SET tn_rgt=tn_rgt-" & diff & " WHERE tn_rgt>=" & rgt & " "
End Function
'############################################################
'* 名称: 获得某结点的路径
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function GetNodePath(NodeID)
Dim lft,rgt
GetNodePath=""
SQL = "SELECT A.tn_name,A.tn_lft,A.tn_rgt FROM TreeNode A ,TreeNode B WHERE (A.tn_lft<=B.tn_lft) AND (A.tn_rgt>=B.tn_rgt) AND B.tn_id=" & NodeID & " ORDER BY A.tn_lft"
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1 '11 for Read '13 for Write
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Else
rs.MoveFirst
Do Until rs.EOF
Response.Write rs(0).Value & "\"
rs.MoveNext
Loop
End If
rs.Close
Set rs = Nothing
End Function
'############################################################
'* 名称: 获得某结点的直属子结点
'* 说明:
'* 日期: 2006-09-20 作者: pkmaster
'############################################################
Function GetChildNodes(RootID)
Dim tmpview
'如果为了提速,可以将下面的SQL语句作为视图
tmpview="SELECT a.tn_id AS pnt_id, a.tn_name AS pnt_name, b.tn_id AS sub_id, b.tn_name AS sub_name, b.tn_lft, b.tn_rgt " & _
"FROM TreeNode AS a, TreeNode AS b " & _
"WHERE b.tn_lft BETWEEN a.tn_lft AND a.tn_rgt AND NOT EXISTS " & _
"(SELECT * FROM TreeNode AS c " & _
"WHERE c.tn_lft BETWEEN a.tn_lft AND a.tn_rgt " & _
"AND b.tn_lft BETWEEN c.tn_lft AND c.tn_rgt " & _
"AND c.tn_id NOT IN (a.tn_id,b.tn_id) ) "
SQL="SELECT DISTINCT s1.sub_id,s1.sub_name " & _
"FROM (" & tmpview & ") as s1,(" & tmpview & ") as s2,TreeNode as o1 " & _
"WHERE s1.pnt_id=o1.tn_id " & _
"AND s2.pnt_id=s1.pnt_id " & _
"AND s1.sub_id<>s2.sub_id " & _
"AND s2.tn_lft <= s1.tn_lft " & _
"AND o1.tn_id=" & RootID & " "
Set rs=Server.CreateObject("ADODB.Recordset")
rs.Open SQL,conn,1,1
sqlcount=sqlcount+1
If rs.EOF And rs.BOF Then
Else
rs.MoveFirst
Do Until rs.EOF
Response.Write "(" & rs(0) & ")" & rs(1) & vbCrLf
rs.MoveNext
Loop
End If
rs.Close
Set rs = Nothing
End Function
加载全部内容