C++_快速排序
#Hello_World 人气:0快速排序:二十世纪十大算法之一 !
快速排序的基本实现
快速排序是一种基于交换的高效排序算法,它采用了分治法的思想。步骤如下:
- 从数列中选出一个数作为基准数(枢轴,Pivot)
- 将数组进行划分(Partition),将比基准数大的元素移至枢轴右侧,将比基准数小的元素移至枢轴左侧。
- 对左右两区间分别进行第二步的划分操作,知道每个子区间只有一个元素。
快排最重要的步骤就是划分了(Partition)。划分的过程用通俗的语言讲就是“挖坑”和“填坑”。
图片较小,请原谅
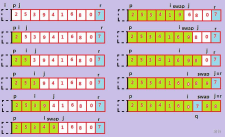
代码:
int partition(int arr[], int left, int right) //找基准数进行划分
{
int low = left + 1; //区间下端
int high = right; //区间上端
int pivot = left; //枢轴下标
int cur = pivot+1; //存储位置下标
for(int i=low; i<=high; i++) //从下端到上端的遍历
{
if(arr[i] < arr[pivot])
{
swap(arr[i], arr[cur]); //交换现在的值和存储位置的值
cur++; //将存储位置变为下一位
}
}
swap(arr[pivot], arr[cur-1]); //将枢轴移至数组正确位置
return cur-1; //返回枢轴位置
}
void quick_sort(int arr[], int left, int right)
{
if (left >= right)
return;
int mid = partition(arr, left, right); //获取枢轴位置
quick_sort(arr, left, mid - 1); //下端区间递归
quick_sort(arr, mid + 1, right); //上端区间递归
}
时间复杂度分析
快排的时间复杂度在最坏情况下是 O(n²),平均的时间复杂度是 O(n log n)。
怎么理解呢?其实很简单。假设数列中有n个数,则遍历一次的时间复杂度为 O(n),需要遍历至少 log (n + 1)次,最多 n次。
+Q1:为什么最少是 log (n + 1)次?
+A1:快速排序是采用分治法进行遍历的,所以可以看成一棵二叉树,它遍历的次数就是二叉树的深度。而根据二叉树的定义,它的深度至少为 log (n + 1)。因此快速排序的遍历次数至少是 log (n + 1)次。
+Q2:为什么最多是 n次遍历?
+A2:这个应该比较好理解。仍然将快速排序看作一棵二叉树,二叉树的最大深度为 n。所以快速排序的遍历次数最多是 n次。
快速排序的稳定性
快速排序是不稳定的算法,它不满足稳定排序算法的定义。 算法稳定性:假设在数列中存在 a[i] = a[j],若在排序之前,a[i] 在 a[j] 前面,并且排序后,a[i]仍然在 a[j]前面,则这个排序是稳定的!
That's all!Thank you for watching !
快速排序优化已更新!传送门
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说