软工实践寒假作业(2/2)疫情统计程序
索隆不喝酒 人气:2| 这个作业属于哪个课程 | 2020春|S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 设计、开发一个疫情统计的程序、学习对程序的优化、学习GitHub的使用、PSP(个人软件开发流程)的学习使用、《构建之法》的学习 |
| 作业正文 | https:////www.cnblogs.com/hhhqqq/p/12306200.html |
| 其他参考文献 | 几篇博客教程:GitHub|.gitignore|github desktop|fork、pr|JUnit4单元测试|性能分析|... |
GitHub仓库地址
https://github.com/904566722/InfectStatistic-main
《构建之法》1~3章学习&PSP表格
学习记录
学习笔记:https://www.cnblogs.com/hhhqqq/p/12287911.html
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(min) | 实际耗时(min) |
|---|---|---|---|
| Planning | 计划 | 60 | 50 |
| Estimate | 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 760 | 735 |
| Analysis | 需求分析 (包括学习新技术) | 180 | 200 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 30 |
| Design | 具体设计 | 60 | 90 |
| Coding | 具体编码 | 300 | 290 |
| Code Review | 代码复审 | 30 | 25 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 60 |
| Reporting | 报告 | 90 | 150 |
| Test Report | 测试报告 | 15 | 10 |
| Size Measurement | 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 45 | 25 |
| total | 合计 | 990 | 1005 |
解题思路
对照“疫情统计程序的需求文档”理清文档的结构
221701419 \--src //源代码 InfectStatistic.java Lib.java \--log //项目的输入文本, 2020-01-22.log.txt ... \--result //处理后最终结果的输出 ListOut1.txt ...找到合适的数据结构
- 分析“日志文本”,需要统计的是每个省的数据,可以创建一个**省类(Province)**来记录感染患者、疑似患者、治愈等信息
public class Province{ String provinceName; // 省份名称 int ip; // 感染患者 int sp; // 疑似患者 int cure; // 治愈 int dead; // 死亡 //构造等其他方法 ... }
- 分析“需求”,最终的处理结果要将每个省的信息按行输出,因此可以将之前参加统计的每个省类加入一个集合,输出时从该集合中依次取出,并打印结果,我选择了哈希表(HashTable),将省名作为键,Province作为值
Province Fujian = new Province(); HashTable<String, Province> hastable = new HashTable<String, Province>(35); hashtable.put("福建",Fujian);对日志文本详细分析
对log日志中出现的几种情况分析,可以用String的**split(" ")**来分割主谓宾
该日志中出现的几种情况 用split分割后的数组长度 1、<省> 新增 感染患者 n人 4 2、<省> 新增 疑似患者 n人 4 3、<省1> 感染患者 流入 <省2> n人 5 4、<省1> 疑似患者 流入 <省2> n人 5 5、<省> 死亡 n人 3 6、<省> 治愈 n人 3 7、<省> 疑似患者 确诊感染 n人 4 8、<省> 排除 疑似患者 n人 4 String line = "福建 新增 感染患者 1人"; String[] afterSplitStrings = line.split(" "); //afterSplitStrings[0]:"福建" [1]:"新增" [2]:"感染患者" [3]:"1人"分类后数组长度的三种情况:3、4、5
分类后可以得到需要修改的省份名称,两种情况:1.仅需修改一个省份;2.需修改两个省份
得到需要修改的省份后判断需要执行的操作类型,分析日志中出现的几种情况思考要如何修改相应省份的数据,并将操作赋予一个类型ID
日志出现的情况 数据修改 操作类型ID <省> 死亡 n人 死亡数+n && 感染者-n 1 <省> 治愈 n人 治愈+n && 感染者-n 2 <省> 新增 感染患者 n人 感染者+n 3 <省> 新增 疑似患者 n人 疑似者+n 4 <省> 排除 疑似患者 n人 疑似者-n 5 <省> 疑似患者 确诊感染 n人 疑似者-n && 感染者+n 6 <省1> 感染患者 流入 <省2> n人 省1 感染者-n && 省2 感染者+n 7 <省1> 疑似患者 流入 <省2> n人 省1 疑似者-n && 省2 疑似者+n 8 因此需要:1.Province对数据相应修改的方法
2.一个能够根据省份名称和操作类型ID执行相应操作的方法对需求文档详细分析
先不考虑命令以及参数的内容,先将日期、输入目录、输出文件作为常量使用,来完成需求里要求的功能:
- 读取log文件夹里的文件
能够筛选出指定日期前的文件
忽略注释行
- 数据的统计
- 省份的统计
从输入文件读取一行后进行分析,省份存在以下情况:
只有一个省 *哈希表中没有该省 *哈希表中存在该省 两个省 *存在省1,存在省2 *存在省1,不存在省2 *不存在省1,存在省2 *不存在省1,不存在省2 ----存在则从hashtable取出,不存在则新建Province类,然后put进hashtable
- 全国的统计
所有要求的log日志文件处理完后,遍历hashtable来统计全国的数据
- 输出到相应目录,全国总是排第一个,别的省按拼音先后排序,末尾填上一行文档数据说名和一行命令
输出示例: 全国 感染患者22人 疑似患者25人 治愈10人 死亡2人 福建 感染患者2人 疑似患者5人 治愈0人 死亡0人 浙江 感染患者3人 疑似患者5人 治愈2人 死亡1人 // 该文档并非真实数据,仅供测试使用 // 命令: ....命令行参数
一个命令list,五个参数名-log、 -out、 -date、 -type、 -province
示例命令行:
java InfectStatistic list -date 2020-01-22 -log D:/log/ -out D:/output.txt -type sp ip -province 福建
从list开始,其后的参数都存入了args数组,写个方法从其中提取出参数名,然后再取得相应的参数值
比较需要注意的几点:
-date 不设置为默认最新的一天,因此要有一个取得log里最新时间的方法;传入的时间超过最新时间给出“日期超出范围的提示”
-type 与 -province可能携带一到多个命令参数,-province指定输出的省份也要排序,两者的参数需要作为参数传入给写入文件的方法,对输出的格式进行规约,可能出现以下四种组合:
1.指定类型 && 指定省份 2.指定类型 && 无指定省份 3.无指定类型 && 指定省份 4.无指定类型 && 无指定省份
设计实现过程
大致流程
graph LR a[命令行处理]-->b[初始化相应变量] b-->c[获得log文件] c-->d[遍历log统计数据] d-->e[打印结果到txt文件]
代码组织
InfectStatistic的结构:
InfectStatistic{ public class Province{...} //省类,用来记录感染患者、疑似患者、治愈、死亡等信息 static class ×××Methods{...} //存储静态方法的静态类,编程过程中根据方法作用的类别归类 public static void main(String[] args){} }
- 省类Province:
public class Province{ String provinceName; // 省份名称 int ip; // 感染患者 int sp; // 疑似患者 int cure; // 治愈 int dead; // 死亡 //构造等其他方法 //属性的加减 //输出属性信息 ... }
根据大致流程将静态方法大致归类:
- 对传入的命令行的处理
- 取得log文件列表
- 统计信息
- 哈希表的相关操作
- 结果输出
graph LR a[InfectStatistic]-->b[Province类] a-->c[静态类-命令行处理相关方法] a-->d[静态类-取得log文件相关方法] a-->e[静态类-统计信息相关方法] a-->f[静态类-哈希表操作的相关方法] a-->g[静态类-打印结果相关方法]
关键函数流程图
读入信息,修改省份数据
graph LR A[一行信息]-->B[分割该字符串</br>得到省份&人数&操作类型] B-->C{哈希表中是否存在省} C-->|存在| D[取出该省] D-->E[修改数据] C-->|不存在| F[新建并初始化Province实例] F-->G[存入哈希表]获取文件夹下指定日期前的所有文件名
graph TD a[格式化日期格式]-->b[用目录下的文件名列表初始化字符串数组] b-->c[将字符串日期转为Date格式] c-->d{指定的日期与列表中最大日期比较} d-->|指定日期大于最大日期|e[日期超出范围提示] d-->|指定日期小于最大日期|f[遍历日期字符串数组] f-->g{与指定日期比较} g-->|小于等于指定日期|h[加入结果数组] g-->|大于指定日期|i[无操作] j[编写getMaxDate函数</br>获得最大日期]-->d输出文件
graph TD a[开始]-->b{判断有无省份参数} b-->|没有| e[排序传入的哈希表] e-->f[遍历该哈希表] f-->g{判断有无类型参数} g-->|没有|h[打印全部信息] g-->|有|i[打印指定信息] b-->|有|j[新建哈希表] j-->k[遍历指定的省份] k-->L{判断传入的哈希表是否有该省} L-->|没有| m[新建并初始化Province实例</br>传入新的哈希表] L-->|有| o[从传入的哈希表取出并传入新的哈希表] m-->p[排序新的哈希表] o-->p p-->f
关键代码说明
判断操作类型
/** * description:判断操作类型 * @param strings 分割后的字符串数组 * @return 返回值操作类型ID(1~8) */ public static int getOperateType(String[] strings) { int len = strings.length; int res = 0; if (len == 3) { //分割后的数组长度为3 if (strings[1].equals("死亡")) { res = 1; } else if (strings[1].equals("治愈")) { res = 2; } } else if (len == 4) { //分割后的数组长度为4 if (strings[1].equals("新增")) { if (strings[2].equals("感染患者")) { res = 3; } else if (strings[2].equals("疑似患者")) { res = 4; } } else if (strings[1].equals("排除")) { res = 5; } else { res = 6; } } else { //分割后的数组长度为5 if (strings[1].equals("感染患者")) { res = 7; } else { res = 8; } } return res; }解释思路:
根据读取的每行信息分割后的数组,其长度只有三种:
- 3:
<省> 死亡 n人或<省> 治愈 n人,通过判断第二个字符串区分操作类型;- 4:
<省> 新增 感染患者 n人或<省> 新增 疑似患者 n人或<省> 疑似患者 确诊感染 n人或<省> 排除 疑似患者 n人,先判断第二个字符串是“新增”还是“排除”,“新增”里再判断第三个字符串是“感染患者”还是“疑似患者”,便可区分四者;- 5:
<省1> 感染患者 流入 <省2> n人或<省1> 疑似患者 流入 <省2> n人,判断第二个字符即可
统计数据
/** * description:统计省份数据 * @param lineString 一行字符串 * @param hashtable 保存参与统计的省份 */ public static void calcProvince(String lineString, Hashtable<String, Province> hashtable) { InfectStatistic infectStatistic = new InfectStatistic(); String[] afterSplitStrings = lineString.split(" "); int numAfterSplit = afterSplitStrings.length; // 切割后数量 int number = ToolMethods.getNumber(afterSplitStrings[numAfterSplit - 1]); // 一行信息中涉及的人数 String[] provinceNameStrings = ToolMethods.getNeedModifyProvinceNames(afterSplitStrings); int operateType = ToolMethods.getOperateType(afterSplitStrings); if (provinceNameStrings[1].equals("")) { // 只有一个省 if (!hashtable.containsKey(provinceNameStrings[0])) { // 哈希表中没有该省 Province province = infectStatistic.new Province(provinceNameStrings[0], 0, 0, 0, 0); ToolMethods.executeOperate(province, province, operateType, number); hashtable.put(province.getProvinceName(), province); } else { Province province = hashtable.get(provinceNameStrings[0]); ToolMethods.executeOperate(province, province, operateType, number); } } else if (!provinceNameStrings[1].equals("")) { // 有两个省 Province province1 = null; Province province2 = null; if (hashtable.containsKey(provinceNameStrings[0]) && hashtable.containsKey(provinceNameStrings[1])) { province1 = hashtable.get(provinceNameStrings[0]); province2 = hashtable.get(provinceNameStrings[1]); } else if (hashtable.containsKey(provinceNameStrings[0]) && !hashtable.containsKey(provinceNameStrings[1])) { province1 = hashtable.get(provinceNameStrings[0]); province2 = infectStatistic.new Province(provinceNameStrings[1], 0, 0, 0, 0); hashtable.put(provinceNameStrings[1], province2); } else if (!hashtable.containsKey(provinceNameStrings[0]) && hashtable.containsKey(provinceNameStrings[1])) { province1 = infectStatistic.new Province(provinceNameStrings[0], 0, 0, 0, 0); hashtable.put(provinceNameStrings[0], province1); province2 = hashtable.get(provinceNameStrings[1]); } else if (!hashtable.containsKey(provinceNameStrings[0]) && !hashtable.containsKey(provinceNameStrings[1])) { province1 = infectStatistic.new Province(provinceNameStrings[0], 0, 0, 0, 0); province2 = infectStatistic.new Province(provinceNameStrings[1], 0, 0, 0, 0); hashtable.put(provinceNameStrings[0], province1); hashtable.put(provinceNameStrings[1], province2); } ToolMethods.executeOperate(province1, province2, operateType, number); } } /** * description:统计全国的数据 * @param hashtable 保存着所有参与统计的省份 */ public static void calcWholeNation(Hashtable<String, Province> hashtable) { InfectStatistic infectStatistic = new InfectStatistic(); Province wholeNation = infectStatistic.new Province("全国", 0, 0, 0, 0); Set set = hashtable.keySet(); Iterator iterator = set.iterator(); while(iterator.hasNext()) { Object keyObject = iterator.next(); wholeNation.ip += hashtable.get(keyObject).getIp(); wholeNation.sp += hashtable.get(keyObject).getSp(); wholeNation.cure += hashtable.get(keyObject).getCure(); wholeNation.dead += hashtable.get(keyObject).getDead(); } hashtable.put("全国", wholeNation); }解释思路:
统计省份数据函数:传入从log文件读取的一行,切割取得数组,获得需要修改数据的省份、人数数量以及操作类型,然后判别省份个数(1个|2个),进而判别哈希表中是否存在该省份,如果存在,说明该省前面已经统计过部分数据,所以从哈希表中取出;如果不存在,则创建一个Province类;接着将省份、人数数量、操作类型传入执行操作的静态方法executeOperate(),执行相应的操作;操作完成后,之前新建的Province类要put进哈希表。
统计全国数据:统计完所有日志文档后,新建一个全国的Province实例wholeNation,遍历哈希表,累计各项属性的值,赋给wholeNation的相应属性,再将wholeNation存入哈希表
写入文件
/** * description:写入文件 * @param hashtable 保存着所有参与统计的省份 * @param fileOutputStream 输出文件流 * @param paramenterOfType -type的参数值 * @param paramenterOfProvice -province的参数值 * @param commandLineStrings 命令行数组 argv */ public static void writeFile(Hashtable<String, Province> hashtable, FileOutputStream fileOutputStream, String[] paramentersOfType, String[] paramentersOfProvince,String[] commandLineStrings) { String endLineString = "// 该文档并非真实数据,仅供测试使用"; String commandLineString = "// 命令:"; for(int i=0; i<commandLineStrings.length; i++) { commandLineString = commandLineString + commandLineStrings[i] + " "; } InfectStatistic infectStatistic = new InfectStatistic(); Province wholeNation = hashtable.get("全国"); try { OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream,"UTF8"); if(paramentersOfProvince[0].equals("null")) { //没有指定省份 Set set = hashtable.keySet(); Iterator iterator = set.iterator(); List<Map.Entry<String,Province>> list = sortByHeadAlphabet(hashtable); //排序 for (Map.Entry entry : list){ Province province = (Province) entry.getValue(); if(paramentersOfType[0].equals("null")) { //没有指定输出类型 outputStreamWriter.write(province.getAllResult() + "\r\n"); outputStreamWriter.flush(); }else { outputStreamWriter.write(province.getResultByRequest(paramentersOfType) + "\r\n"); outputStreamWriter.flush(); } } outputStreamWriter.write(endLineString + "\r\n" + commandLineString); outputStreamWriter.flush(); }else { //指定省份 Hashtable<String, Province> requestProvinceHashtable = new Hashtable<String, InfectStatistic.Province>(); // for(int i=0; i<paramentersOfProvince.length; i++) { for(int i=0; paramentersOfProvince[i] != null; i++) { if(!hashtable.containsKey(paramentersOfProvince[i])) { //哈希表中不存在 Province province = infectStatistic.new Province(paramentersOfProvince[i], 0, 0, 0, 0); requestProvinceHashtable.put(paramentersOfProvince[i], province); }else { //哈希表中存在 Province province = hashtable.get(paramentersOfProvince[i]); requestProvinceHashtable.put(paramentersOfProvince[i], province); } } List<Map.Entry<String,Province>> list = sortByHeadAlphabet(requestProvinceHashtable); //排序 for (Map.Entry entry : list){ Province province = (Province) entry.getValue(); if(paramentersOfType[0].equals("null")) { //没有指定输出类型 outputStreamWriter.write(province.getAllResult() + "\r\n"); outputStreamWriter.flush(); }else { outputStreamWriter.write(province.getResultByRequest(paramentersOfType) + "\r\n"); outputStreamWriter.flush(); } } outputStreamWriter.write(endLineString + "\r\n" + commandLineString); outputStreamWriter.flush(); } } catch (Exception e) { // TODO: handle exception e.printStackTrace(); } }解释思路:
主要是判断用户是否传入了-type和-province,有四种组合,不过该方法里主要判别province,有无type只要通过调用Province不同的方法来输出不同的结果即可,所以主要两大类:
- 没有指定省份
先对哈希表排序,然后遍历哈希表,再判别有无-type,调用Province的方法打印该省的相应数据
- 指定了省份
新建一个保存指定省份信息的哈希表requestProvinceHashtable,遍历指定的所有省份,判断传入的哈希表hashtable(即保存着在log中出现的所有省份的数据)中是否存在当前的省(指定输出的省份可能没在log文件中出现),如果不存在,新建该省份的Province实例,并加入requestProvinceHashtable,如果存在,从hashtable中取出该省,并加入requestProvinceHashtable,因此requestProvinceHashtable中保存了想要输出的省份的数据,然后排序requestProvinceHashtable,再遍历输出
Province的两个获得结果的方法:/** * description:打印全部统计的数据结果 * @return resString 返回值为字符串 */ public String getAllResult() { String resString = provinceName + " " + "感染患者" + ip + "人" + " " + "疑似患者" + sp + "人" + " " + "治愈" + cure + "人" + " " + "死亡" + dead + "人"; return resString; } /** * description:按指定参数值要求给出结果 * @param paramenterOf 一个保存着-type的参数值的数组 * @return resString 返回值为字符串 */ public String getResultByRequest(String[] paramentersOfType) { String resString = provinceName + " "; for(int i=0; paramentersOfType[i] != null; i++) { switch (paramentersOfType[i]) { case "ip": resString += "感染患者" + ip + "人" + " "; break; case "sp": resString += "疑似患者" + sp + "人" + " "; break; case "cure": resString += "治愈" + cure + "人" + " "; break; case "dead": resString += "死亡" + dead + "人" + " "; break; default: break; } } return resString; }
命令行的处理
HashMap<Integer, String> paramenterHashMap = new HashMap<Integer, String>(5); paramenterHashMap.put(1, "-log"); paramenterHashMap.put(2, "-out"); paramenterHashMap.put(3, "-date"); paramenterHashMap.put(4, "-type"); paramenterHashMap.put(5, "-province"); String[] paramenterStrings = new String[args.length - 1]; //存储传入的参数名、参数值 for(int i=1; i<args.length; i++) { paramenterStrings[i-1] = args[i]; } int[] indexOfParamenterStrings = {-1, -1, -1, -1, -1, -1}; //找到参数名,并记录位置 for(int i=0; i<paramenterStrings.length; i++) { int key = ToolMethods.getKey(paramenterHashMap, paramenterStrings[i]); if( key != -1) { //是参数名 indexOfParamenterStrings[key] = i; //key对应的参数名在patamenterStrings的i下标位置,值为-1则代表无此参数名 } } String directoryString = "./log"; // log 日志文件目录 String outputFileNameString = "./result/testOutput.txt"; //输出路径/文件名 String toDateString = ToolMethods.getToday(); //统计到哪一天 String[] paramentersOfType = new String[10];; //type的参数值 String[] paramentersOfProvince = new String[25]; //province的参数值 paramentersOfType[0] = "null"; paramentersOfProvince[0] = "null"; //接着处理每个参数名对应的参数值 for(int i=1; i<=5; i++) { if(indexOfParamenterStrings[i] != -1) { //传入了该参数名 if(i == 1) { // -log directoryString = paramenterStrings[indexOfParamenterStrings[i] + 1]; //配置log路径 }else if(i == 2) { //-out outputFileNameString = paramenterStrings[indexOfParamenterStrings[i] + 1]; //配置输出文件路径 }else if(i == 3) { //-date toDateString = paramenterStrings[indexOfParamenterStrings[i] + 1]; //统计到哪一天 }else if(i == 4) { //-type 可能会有多个参数 String[] paramenterValues = new String[20]; //记录所有参数值 int cnt = 0; //取得参数值,直到找到下一个参数名时停止, 当前参数名 参数值1 参数值2 ... 下一个参数名 for(int j=indexOfParamenterStrings[i]+1; j<paramenterStrings.length && ToolMethods.getKey(paramenterHashMap, paramenterStrings[j])==-1; j++) { paramenterValues[cnt++] = paramenterStrings[j]; paramentersOfType = paramenterValues; } }else if(i == 5) { //-province String[] paramenterValues = new String[20]; int cnt = 0; //取得参数值,直到找到下一个参数名时停止, 当前参数名 参数值1 参数值2 ... 下一个参数名 for(int j=indexOfParamenterStrings[i]+1; j<paramenterStrings.length && ToolMethods.getKey(paramenterHashMap, paramenterStrings[j])==-1; j++) { paramenterValues[cnt++] = paramenterStrings[j]; paramentersOfProvince = paramenterValues; } } } }解释说明:
用五个参数名初始化一个hashMap,用传入的参数名、参数值初始化一个字符串数组paramenterStrings,用-1初始化一个大小为6的int数组indexOfParamenterStrings,遍历paramenterStrings,如果在hashMap中存在该值(该值为参数名),则将该值在hashMap中对应的键作为indexOfParamenterStrings的下标,将该值对应paramenterStrings的下标作为indexOfParamenterStrings的值
例:indexOfParamenterStrings[4] = 6 代表的是hashMap中键为4的参数名-type在paramenterStrings[6]中 indexOfParamenterStrings[4] = -1 则代表没有传入该参数然后从下标1开始遍历indexOfParamenterStrings(初始化hashMap时从1开始的),判断是否传入了该参数名,如果存在,从paramenterStrings中为当前参数名的下一个位置开始取得参数值,直到paramenterStrings的尽头或者遇到下一个参数名,然后用取得的参数值初始化相应的变量
单元测试截图和描述
获取字符串前的数字
测试用例
测试结果:


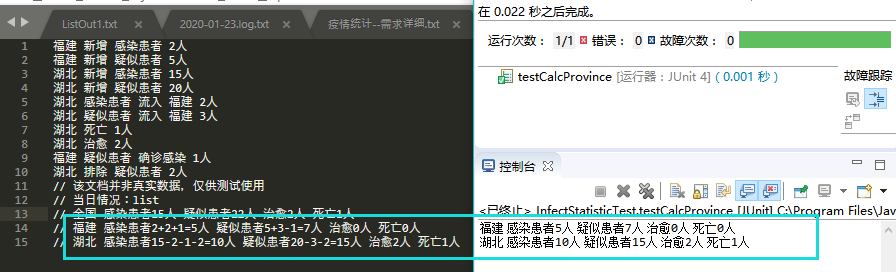
获得需要修改数据的省份
测试数据:
public String[] testStrings = { "福建 新增 感染患者 2人" , "福建 新增 疑似患者 5人" , "湖北 新增 感染患者 15人" , "湖北 新增 疑似患者 20人" , "湖北 感染患者 流入 福建 2人" , "湖北 疑似患者 流入 福建 3人" , "湖北 死亡 1人" , "湖北 治愈 2人" , "福建 疑似患者 确诊感染 1人" , "湖北 排除 疑似患者 2人" };测试用例:
测试结果:

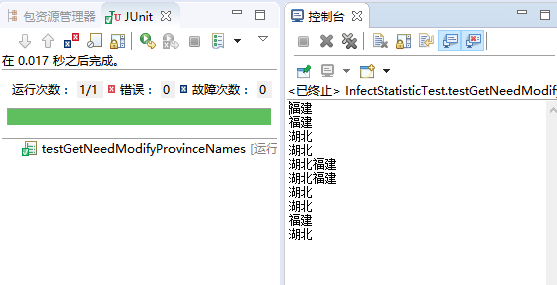
获得最大日期
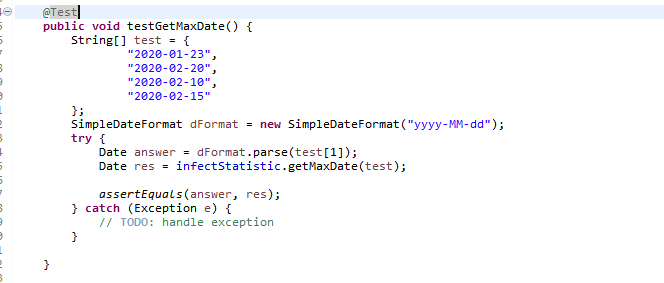
测试用例:
测试结果:
获得指定日期前的所有文件
测试用例:
测试结果:


按城市首字母排序,“全国”置顶
测试用例:
测试结果:

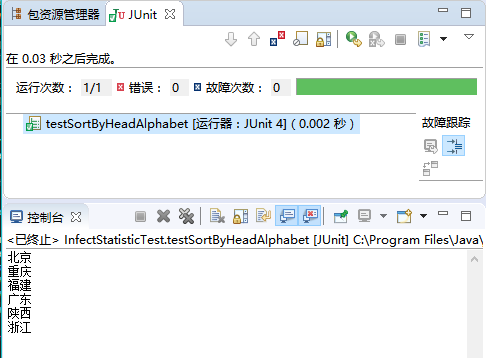
统计省份数据
测试数据:
public String[] testStrings = { "福建 新增 感染患者 2人" , "福建 新增 疑似患者 5人" , "湖北 新增 感染患者 15人" , "湖北 新增 疑似患者 20人" , "湖北 感染患者 流入 福建 2人" , "湖北 疑似患者 流入 福建 3人" , "湖北 死亡 1人" , "湖北 治愈 2人" , "福建 疑似患者 确诊感染 1人" , "湖北 排除 疑似患者 2人" };测试用例:
测试结果:

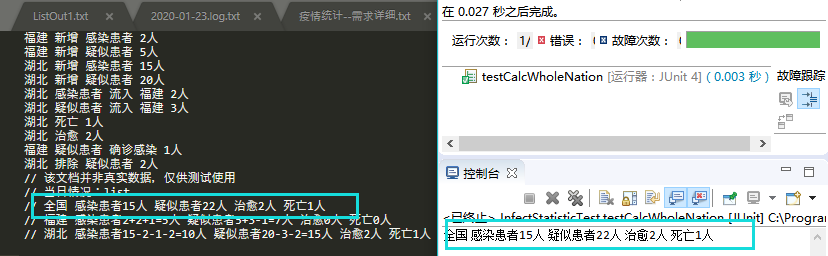
统计全国的数据
测试用例:
测试结果:

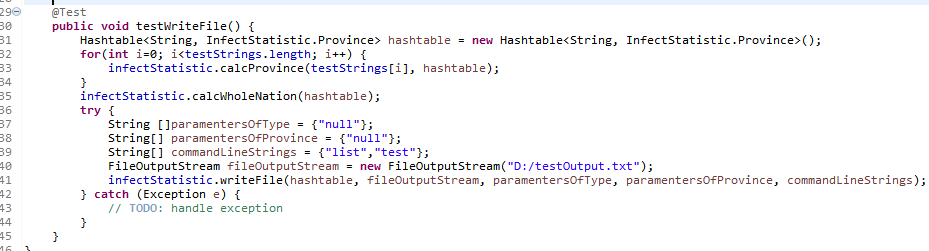
写入文件
测试用例:
测试结果:

HashMap根据value获取key
测试用例:
测试结果:


单元测试覆盖率优化和性能测试
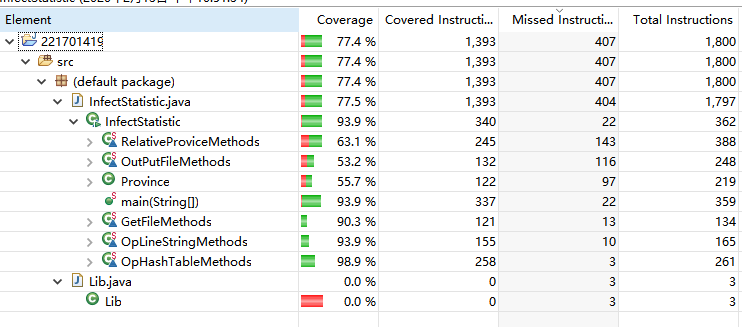
覆盖率测试
application覆盖测试
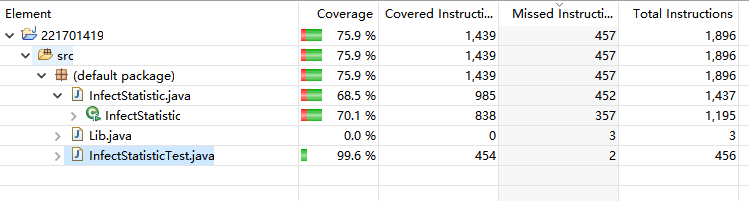
JUnit Test覆盖测试
性能测试
代码规范
https://github.com/904566722/InfectStatistic-main/blob/master/221701419/codestyle.md
心路历程&收获
这次的作业相较于第一次,量还是比较多的,看完第一遍之后的感受就是有许多不知道的东西,PSP、单元测试等等,触及到了我的知识盲区...然后就决定先不管,先看看《编程之法》前三章,里面提到了许多问题都是自己目前存在的,粗略列几点来提醒自己:
- 技止此耳? 看书的时候多思考此项技术及延伸,及时实践发现同书上的不同,技术更新总是很快
- 唯手熟尔。 不断练习,把低层次常遇到的问题变成大脑的“自动操作”,才能做更高层次的随机应变
- 多测试结果。多对写完的程序进行测试,多找Bug,写更好的软件、程序。写完程序我总是很懒得去测试...
- ...
写到这里了,这次任务就快要结束了,通过这次的学习还是收获到不少,包括旧知识的复习、新知识的学习,这次的任务涉及到了很多的知识跟技术,Java、GitHub、PSP、单元测试等等,有一部分都是之前了解过、但不怎么使用的,通过这次的学习,回顾了Java代码的编写,进一步了解了GitHub、markdown的一些使用技巧,学习到了PSP、单元测试、覆盖率等等新的知识,以及很重要的对自我的反省,还是很充实的,收获很多。
Android学习相关的5个仓库
1.AndroidAllGuide
链接:https://github.com/904566722/AndroidAllGuide
简介: 这是一份关于 Java、Kotlin、Dart、Android 、Flutter 的学习指南 , 本指南以 Java & Kotlin & Dart 的基础语法知识作为开始,涵盖了大部分的语言知识点,帮助初学者入门
2.Android
链接:https://github.com/itheima1/Android
简介: 收集Android方方面面的经典知识, 最新技术. 涵盖Android方方面面的技术, 目前保持更新. 时刻与Android开发流行前沿同步.
3.BGAPhotoPicker-Android
链接:https://github.com/bingoogolapple/BGAPhotoPicker-Android
简介: Android 图片选择、预览、九宫格图片控件、拖拽排序九宫格图片控件
4.DDComponentForAndroid
链接:https://github.com/luojilab/DDComponentForAndroid
简介: 一套完整有效的android组件化方案,支持组件的组件完全隔离、单独调试、集成调试、组件交互、UI跳转、动态加载卸载等功能
5.Coder
链接:https://github.com/CoderGuoy/Coder
简介: 项目使用MVVM模式进行开发, Tablayout | 横向布局标签,TextInputLayout | 文字输入布局 ,FloatingActionButton | 悬浮按钮 等
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说