Serverless 的资源评估与成本探索
Serverless 人气:3Serverless 布道师在讲解 Serverless 架构和云主机等区别的时候,总会有类似的描述:
传统业务开发完成想要上线,需要评估资源使用。根据评估结果,购买云主机,并且需要根据业务的发展不断对主机等资源进行升级维。而 Serverless 架构,则不需要这样复杂的流程,只需要将函数部署到线上,一切后端服务交给运营商来处理。即使是瞬时高并发,也有云厂商为您自动扩缩。
但是在实际生产中,Serverless 真的无需评估资源么?还是说在 Serverless 架构下,资源评估的内容、对象发生了变化,或者简化呢?
在 腾讯云云函数 中,我们创建一个云函数之后,有这么几个设置项:
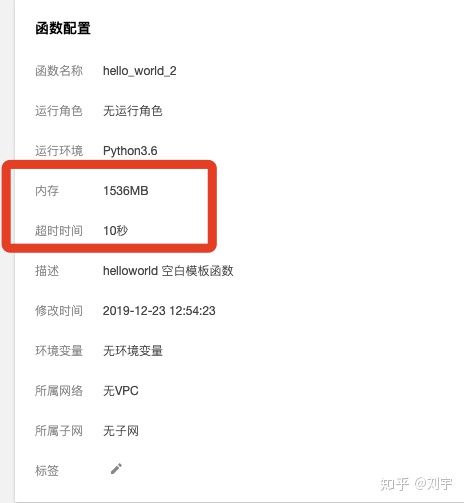
内存设置范围为 64~1536M,超时时间范围为 1~900s。这些设置项其实已经涉及到了资源评估。
超时时间
先说超时时间,一个项目或者一个函数,一个 Action 都是有执行时间的。如果超过某个时间没执行完,就可以评估其为发生了「意外」,可以被「干掉」了,这个就是超时时间。
例如一个获取用户信息的简单请求,假设 10s 内没有返回,证明已经不满足业务需求,此时就可以将超时设置为 10s。如果有另一个业务,运行速度比较慢,至少要 50s 才能执行完,那么这个值的设置就要大于 50,否则程序可能因为超时被强行停止。
内存
内存是一个有趣的东西,可能衍生两个关联点。
关联点 1:
程序本身需要一定的内存,这个内存要大于程序本身的内存。
以 Python 语言为例:
# encoding=utf-8
import jieba
def main_handler(event, context):
jieba.load_userdict("./jiebahttps://img.qb5200.com/download-x/dict.txt")
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list)) # 全模式
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list)) # 精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式
print(", ".join(seg_list))注:为了让结果更直观,差距更加大,这里每次都重新导入了自带了 dict,该操作本身就是相对浪费时间和内存的。在实际使用中 jieba 自带缓存,并且无需手动导入本身的 dict。
当导入一个自定义的 dict 到 jieba 中,如果此时用默认设置:128M 内存限制 + 3s 超时限制,就会这样:
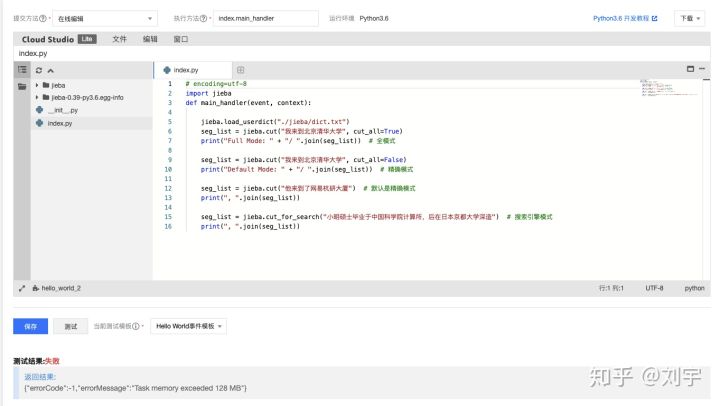
可以看到,在导入自定义 dict 的时候,内存消耗过大, 默认值 128M 不能满足需求,此时将其修改成最大:
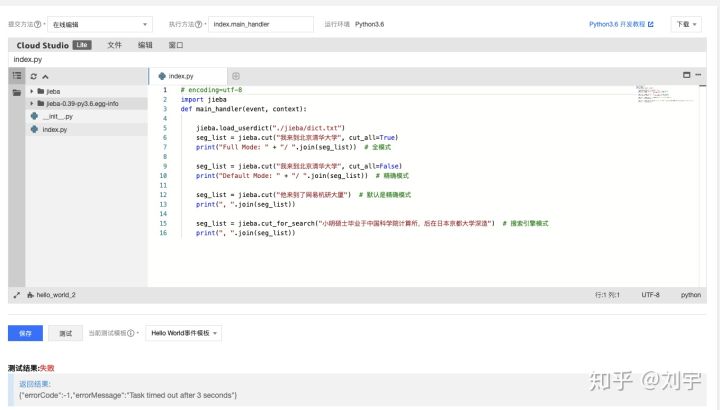
系统提醒时间超时,因此还需要再修改超时时间为适当的数值(此处设定为10s):
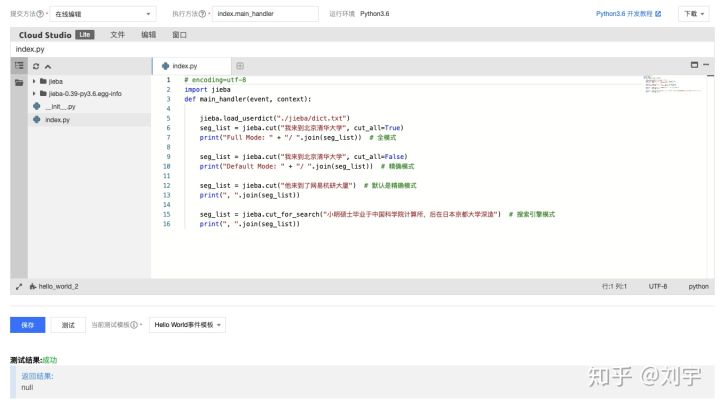
因此,在关注程序本身的前提下,内存需要设置到一个合理范围内。这个范围是 >= 程序本身需要的内存数值。
关联点 2:计费相关。
在云函数的 计费文档 中,有如下描述:
云函数 SCF 按照实际使用付费,采用后付费小时结,以元为单位进行结算。
SCF 账单由以下三部分组成,每部分根据自身统计结果和计算方式进行费用计算,结果以元为单位,并保留小数点后两位。
- 资源使用费用
- 调用次数费用
- 外网出流量费用
调用次数和出网流量这部分,都是程序或者使用相关了,而资源使用费用则有一些注意点:
资源使用量 = 函数配置内存 × 运行时长
用户资源使用量,由函数配置内存,乘以函数运行时的计费时长得出。其中配置内存转换为 GB 单位,计费时长由毫秒 (ms) 转换为秒 (s) 单位,因此,资源使用量的计算单位为 GBs(GB-秒)。
例如,配置为 256MB 的函数,单次运行了 1760 ms,计费时长为 1760 ms,则单次运行的资源使用量为(256/1024)×(1760/1000) = 0.44 GBs。
针对函数的每次运行,均会计算资源使用量,并按小时汇总求和,作为该小时的资源使用量。
这里有一个非常重要的公式,那就是函数配置内存运行时长。
函数配置内存就是刚才所讲:我们为程序选择的内存大小。运行时长,就是我们运行程序之后得到的结果:

以该程序为例,用的是1536MB,则使用量为 (1536/1024) * (3200/1000) = 4.8 GBs
当然,250MB 的情况下,程序也可以运行:

此时的资源使用量为 (256/1024) * (3400/1000) = 0.85GBs
相对比上一次,程序执行时间增加了 0.2s,但是资源使用量降低了将近 6 倍!
尽管 GBs 的单价很低,但是当业务量上来之后,也不能忽略。刚才的只是一个单次请求,如果每天有 1000 此次请求,那:
- 1536 MB: 4.810000.00011108 = 0.5 元
- 25 MB:0.8510000.00011108 = 0.09442 元
仅计算资源使用量费用,而不计算调用次数/外网流量)
如果是一万次调用,那就是 50 元和 9 元的区别。随着流量越大,差距越大。
当然很多时候函数执行时间不会这么久,以个人的某函数为例:

计费时间均是 100ms,每日调用量在 6000 次左右:
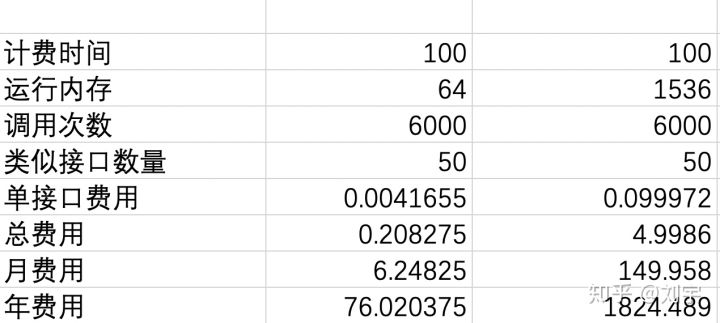
按照 64M 内存来看,单资源费用只要 76 元一年,如果内存都设置称为 1536,则一年要 1824 元!这个费用相当于:
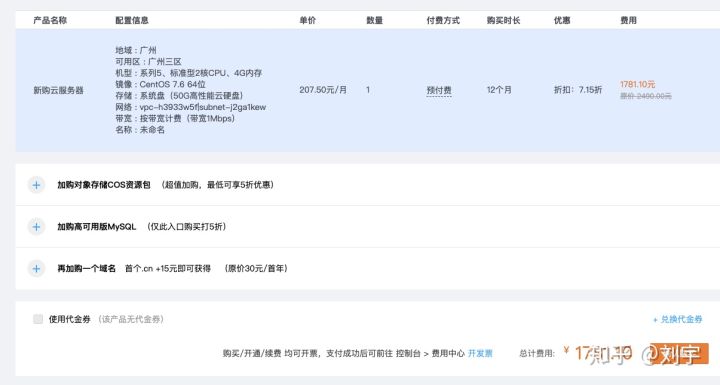
所以说,「超时时间」的设置需要评估代码和业务场景,它关系到程序运行的稳定性和功能完整性。同时,「内存」也不仅仅影响程序的使用层面,还关乎费用成本。那么,既然资源评估如此重要,如何评估呢?
还是以上述代码为例,在本地进行简单的脚本编写:
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.scf.v20180416 import scf_client, models
import json
import numpy
import matplotlib.pyplot as plt
try:
cred = credential.Credential("", "")
httpProfile = HttpProfile()
httpProfile.endpoint = "scf.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = scf_client.ScfClient(cred, "ap-shanghai", clientProfile)
req = models.InvokeRequest()
params = '{"FunctionName":"hello_world_2"}'
req.from_json_string(params)
billTimeList = []
timeList = []
for i in range(1,50):
print("times: ", i)
resp = json.loads(client.Invoke(req).to_json_string())
billTimeList.append(resp['Result']['BillDuration'])
timeList.append(resp['Result']['Duration'])
print("计费最大时间", int(max(billTimeList)))
print("计费最小时间", int(min(billTimeList)))
print("计费平均时间", int(numpy.mean(billTimeList)))
print("运行最大时间", int(max(timeList)))
print("运行最小时间", int(min(timeList)))
print("运行平均时间", int(numpy.mean(timeList)))
plt.figure()
plt.subplot(4, 1, 1)
x_data = range(0, len(billTimeList))
plt.plot(x_data, billTimeList)
plt.subplot(4, 1, 2)
plt.hist(billTimeList, bins=20)
plt.subplot(4, 1, 3)
x_data = range(0, len(timeList))
plt.plot(x_data, timeList)
plt.subplot(4, 1, 4)
plt.hist(timeList, bins=20)
plt.show()
except TencentCloudSDKException as err:
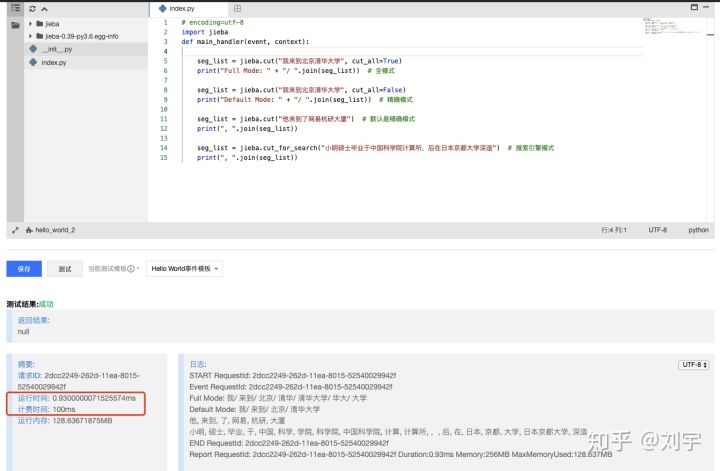
print(err)执行代码会得到这么一张图:

从上到下分别是不同次数计费时间图、计费时间分布图、不同次数运行时间图和运行时间分布图。通过对 256M 起步,1536M 终止,步长 128M,每个内存大小串行靠用 50 次,统计表:

注:为了让统计结果更加清晰,差异性更大,在程序代码中进行了部分无用操作用来增加程序执行时间。正常使用 jieba 基本都是毫秒级的。
通过表统计可以看到,在满足程序内存消耗的前提下,内存大小对程序执行时间的影响并不是很大,反而对计费影响很大。
函数并发量
除了超时时间和运行内存,用户还需要评估一个参数:函数并发量。在项目上线之后,需要对项目的并发量进行评估。当并发量超过默认值,要及时联系售后同学或者提交工单进行最大并发量的提升。
小结
综上,Serverless 架构也是需要资源评估的,而且资源评估同样和成本是直接挂钩。只不过这个资源评估的对象逐渐发生了变化,相对之前的评估维度、难度而言,都是大幅度缩小或者降低的。
传送门:
- GitHub: github.com/serverless
- 官网:serverless.com
欢迎访问:Serverless 中文网,您可以在 最佳实践 里体验更多关于 Serverless 应用的开发!
加载全部内容