Spring IOC原理 Spring IOC原理补充说明(循环依赖、Bean作用域等)
夜勿语 人气:0前言
通过之前的几篇文章将Spring基于XML配置的IOC原理分析完成,但其中还有一些比较重要的细节没有分析总结,比如循环依赖的解决、作用域的实现原理、BeanPostProcessor的执行时机以及SpringBoot零配置实现原理(@ComponentScan、@Import、@ImportSource、@Bean注解的使用和解析)等等。下面就先来看看循环依赖是怎么解决的,在此之前一定要熟悉整个Bean的实例化过程,本篇只会贴出关键性代码。
正文
循环依赖
首先来看几个问题:
什么是循环依赖?
在熟悉了Bean实例化原理后,你会怎么解决循环依赖的问题?
Spring怎么解决循环依赖?有哪些循环依赖可以被解决?哪些又不能?
什么是循环依赖?
这个概念很容易理解,简单说就是两个类相互依赖,类似线程死锁的问题,也就是当创建A对象时需要注入B的依赖对象,但B同时也依赖A,那到底该先创建A还是先创建B呢?
Spring是如何解决循环依赖的?
探究Spring的解决方法之前,我们首先得搞清楚Spring Bean有几种依赖注入的方式:
通过构造函数
通过属性
通过方法(不一定是setter方法,只要在方法上加上了@Autowired,都会进行依赖注入)
其次,Spring作用域有singleton、prototype、request、session等等,但在非单例模式下发生循环依赖是会直接抛出异常的,下面这个代码不知道你还有没有印象,在AbstractBeanFactory.doGetBean中有这个判断:
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
为什么这么设计呢?反过来想,如果不这么设计,你怎么知道循环依赖到底是依赖的哪个对象呢?搞清楚了这个再来看哪些依赖注入的方式发生循环依赖是可以解决,而那些又不能。结论是构造函数方式没办法解决循环依赖,其它两种都可以。
我们先来看看为什么通过属性注入和方法注入可以解决。回忆一下Bean的实例化过程:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
//创建实例
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
// Bean实例化完成后收集类中的注解(@PostConstruct,@PreDestroy,@Resource, @Autowired,@Value)
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
// 单例bean提前暴露
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//这里着重理解,对理解循环依赖帮助非常大,重要程度 5 添加三级缓存
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
//ioc di,依赖注入的核心方法,该方法必须看
populateBean(beanName, mbd, instanceWrapper);
//bean 实例化+ioc依赖注入完以后的调用,非常重要
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
try {
//注册bean销毁时的类DisposableBeanAdapter
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
仔细看这个过程其实不难理解,首先Spring会通过无参构造实例化一个空的A对象,实例化完成后会调用addSingletonFactory存入到三级缓存中(注意这里存入的是singletonFactory对象):
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
// 一级缓存
if (!this.singletonObjects.containsKey(beanName)) {
System.out.println("========set value to 3 level cache->beanName->" + beanName + "->value->" + singletonFactory);
// 三级缓存
this.singletonFactories.put(beanName, singletonFactory);
// 二级缓存
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
然后才会去依赖注入触发类B的实例化,所以这时缓存中已经存在了一个空的A对象;同样B也是通过无参构造实例化,B依赖注入又调用getBean获取A的实例,而在创建对象之前,先是从缓存中获取对象:
//从缓存中拿实例
Object sharedInstance = getSingleton(beanName);
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//根据beanName从缓存中拿实例
//先从一级缓存拿
Object singletonObject = this.singletonObjects.get(beanName);
//如果bean还正在创建,还没创建完成,其实就是堆内存有了,属性还没有DI依赖注入
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//从二级缓存中拿
singletonObject = this.earlySingletonObjects.get(beanName);
//如果还拿不到,并且允许bean提前暴露
if (singletonObject == null && allowEarlyReference) {
//从三级缓存中拿到对象工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//从工厂中拿到对象
singletonObject = singletonFactory.getObject();
//升级到二级缓存
System.out.println("======get instance from 3 level cache->beanName->" + beanName + "->value->" + singletonObject );
this.earlySingletonObjects.put(beanName, singletonObject);
//删除三级缓存
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
很明显,会从三级缓存中拿到singletonFactory对象并调用getObject方法,这是一个Lambda表达式,在表达式中又调用了getEarlyBeanReference方法:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
这里你点进去看会发现都是返回之前我们创建的空的A对象,因此B对象能够依赖注入完成并存入到一级缓存中,接着A对象继续未完成的依赖注入自然是可以成功的,也存入到一级缓存中。Spring就是这样通过缓存解决了循环依赖,但是不知道你注意到没有在上面的getSingleton方法中,从三级缓存中拿到对象后,会添加到二级缓存并删除三级缓存,这是为什么呢?这个二级缓存有什么用呢?
其实也很简单,就是为了提高效率的,因为在getEarlyBeanReference方法中是循环调用BeanPostProcessor类的方法的,当只有一对一的依赖时没有什么问题,但是当A和B相互依赖,A又和C相互依赖,A在注入完B触发C的依赖注入时,这个循环还有必要么?读者们可以自行推演一下整个过程。
至此,Spring是如何解决循环依赖的相信你也很清楚了,现在再来看通过构造函数依赖注入为什么不能解决循环依赖是不是也很清晰了?因为通过构造函数实例化并依赖注入是没办法缓存一个实例对象供依赖对象注入的。
作用域实现原理以及如何自定义作用域
作用域实现原理
在Spring中主要有reqest、session、singleton、prototype等等几种作用域,前面我们分析了singleton创建bean的原理,是通过缓存来实现的,那么其它的呢?还是回到AbstractBeanFactory.doGetBean方法中来:
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
// 该方法是FactoryBean接口的调用入口
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
else if (mbd.isPrototype()) {
// It's a prototype -> create a new instance.
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
// 该方法是FactoryBean接口的调用入口
bean = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}
else {
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
if (scope == null) {
throw new IllegalStateException("No Scope registered for scope name '" + scopeName + "'");
}
try {
Object scopedInstance = scope.get(beanName, () -> {
beforePrototypeCreation(beanName);
try {
return createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
});
// 该方法是FactoryBean接口的调用入口
bean = getObjectForBeanInstance(scopedInstance, name, beanName, mbd);
}
}
在singleton作用域下,会调用getSingleton方法,然后回调createBean创建对象,最终在getSingleton中完成缓存;而当scope为prototype时,可以看到是直接调用了createBean方法并返回,没有任何的缓存操作,因此每次调用getBean都会创建新的对象,即使是同一个线程;除此之外都会进入到else片段中。
这个代码也很简单,首先通过我们配置的scopeName从scopes中拿到对应的Scope对象,如SessionScope和RequestScope(但这两个只会在Web环境中被加载,在WebApplicationContextUtils.registerWebApplicationScopes可以看到注册操作),然后调用对应的get方法存到对应的request或session对象中去。代码很简单,这里就不分析了。
自定义Scope
通过以上分析,不难发现我们是很容易实现一个自己的Scope的,首先实现Scope接口,然后将我们类的实例添加到scopes缓存中来,关键是怎么添加呢?在AbstractBeanFactory类中有一个registerScope方法就是干这个事的,因此我们只要拿到一个BeanFactory对象就行了,那要怎么拿?还记得在refresh中调用的invokeBeanFactoryPostProcessors方法么?因此我们只需要实现BeanFactoryPostProcessor接口就可以了,是不是So Easy!
BeanPostProcessor的执行时机
BeanPostProcessor执行点很多,根据其接口类型在不同的位置进行调用,只有熟记其执行时机,才能更好的进行扩展,这里以一张时序图来总结:
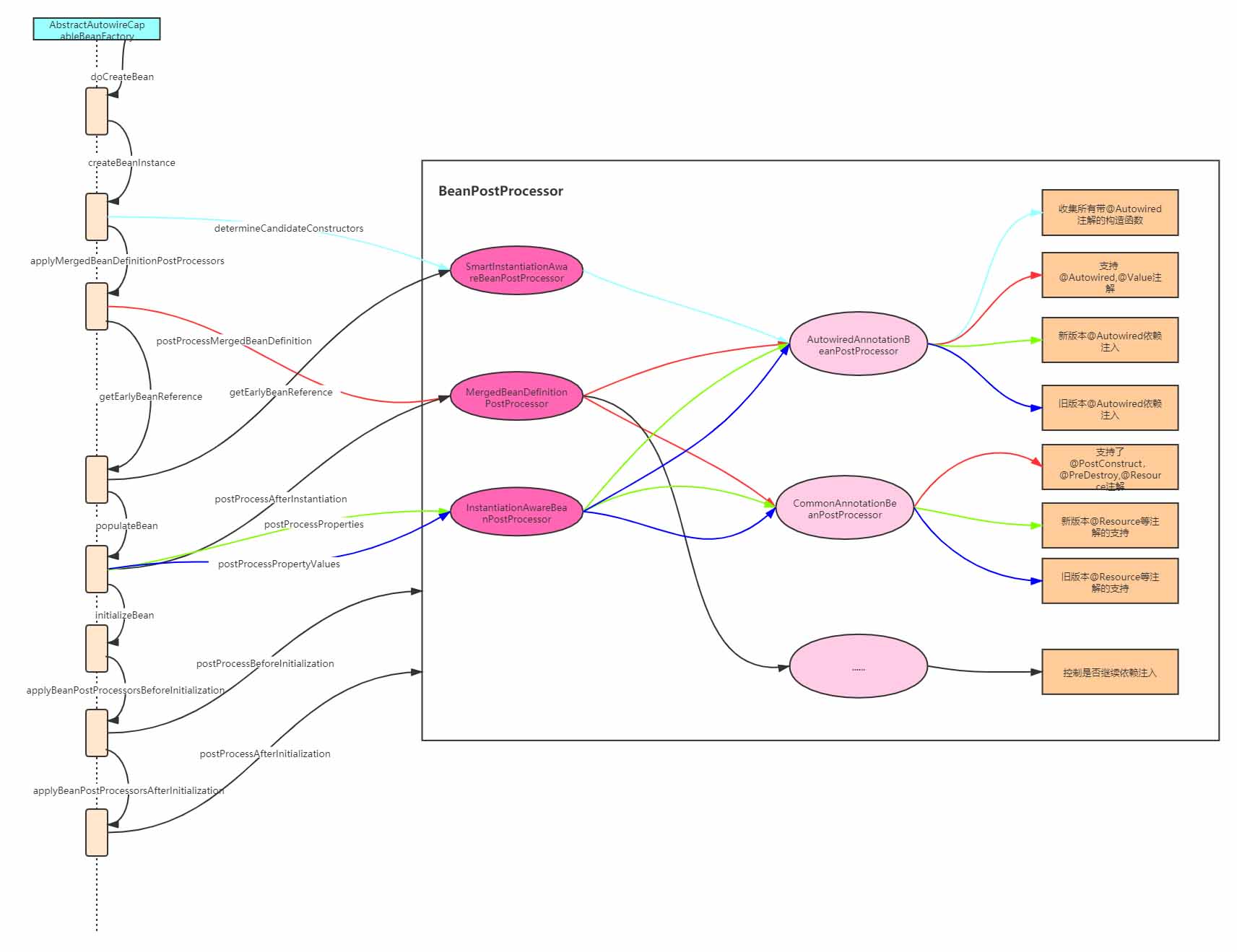
SpringBoot零配置实现原理浅析
在SpringBoot项目中,省去了大量繁杂的xml配置,只需要使用@ComponentScan、@Configuration以及@Bean注解就可以达到和使用xml配置的相同效果,大大简化了我们的开发,那这个实现原理是怎样的呢?熟悉了xml解析原理,相信对于这种注解的方式基本上也能猜个大概。
首先我们进入到AnnotationConfigApplicationContext类,这个就是注解方式的IOC容器:
public AnnotationConfigApplicationContext(String... basePackages) {
this();
scan(basePackages);
refresh();
}
public AnnotationConfigApplicationContext() {
this.reader = new AnnotatedBeanDefinitionReader(this);
this.scanner = new ClassPathBeanDefinitionScanner(this);
}
这里ClassPathBeanDefinitionScanner在解析xml时出现过,就是用来扫描包找到合格的资源的;同时还创建了一个AnnotatedBeanDefinitionReader对象对应XmlBeanDefinitionReader,用来解析注解:
public AnnotatedBeanDefinitionReader(BeanDefinitionRegistry registry, Environment environment) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
Assert.notNull(environment, "Environment must not be null");
this.registry = registry;
this.conditionEvaluator = new ConditionEvaluator(registry, environment, null);
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
public static Set<BeanDefinitionHolder> registerAnnotationConfigProcessors(
BeanDefinitionRegistry registry, @Nullable Object source) {
DefaultListableBeanFactory beanFactory = unwrapDefaultListableBeanFactory(registry);
if (beanFactory != null) {
if (!(beanFactory.getDependencyComparator() instanceof AnnotationAwareOrderComparator)) {
beanFactory.setDependencyComparator(AnnotationAwareOrderComparator.INSTANCE);
}
if (!(beanFactory.getAutowireCandidateResolver() instanceof ContextAnnotationAutowireCandidateResolver)) {
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver());
}
}
Set<BeanDefinitionHolder> beanDefs = new LinkedHashSet<>(8);
if (!registry.containsBeanDefinition(CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(ConfigurationClassPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, CONFIGURATION_ANNOTATION_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(AutowiredAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, AUTOWIRED_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// Check for JSR-250 support, and if present add the CommonAnnotationBeanPostProcessor.
if (jsr250Present && !registry.containsBeanDefinition(COMMON_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(CommonAnnotationBeanPostProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, COMMON_ANNOTATION_PROCESSOR_BEAN_NAME));
}
// Check for JPA support, and if present add the PersistenceAnnotationBeanPostProcessor.
if (jpaPresent && !registry.containsBeanDefinition(PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition();
try {
def.setBeanClass(ClassUtils.forName(PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME,
AnnotationConfigUtils.class.getClassLoader()));
}
catch (ClassNotFoundException ex) {
throw new IllegalStateException(
"Cannot load optional framework class: " + PERSISTENCE_ANNOTATION_PROCESSOR_CLASS_NAME, ex);
}
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, PERSISTENCE_ANNOTATION_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(EVENT_LISTENER_PROCESSOR_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(EventListenerMethodProcessor.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_PROCESSOR_BEAN_NAME));
}
if (!registry.containsBeanDefinition(EVENT_LISTENER_FACTORY_BEAN_NAME)) {
RootBeanDefinition def = new RootBeanDefinition(DefaultEventListenerFactory.class);
def.setSource(source);
beanDefs.add(registerPostProcessor(registry, def, EVENT_LISTENER_FACTORY_BEAN_NAME));
}
return beanDefs;
}
在AnnotatedBeanDefinitionReader构造方法中可以看到调用了registerAnnotationConfigProcessors注册一些列注解解析的Processor类,重点关注ConfigurationClassPostProcessor类,该类是BeanDefinitionRegistryPostProcessor的子类,所以会在refresh中调用,该类又会委托ConfigurationClassParser去解析@Configuration、@Bean、@ComponentScan等注解,所以这两个类就是SpringBoot实现零配置的关键类,实现和之前分析的注解解析流程差不多,所以具体的实现逻辑读者请自行分析。
回头看当解析器和扫描器创建好后,同样是调用scan方法扫描包,然后refresh启动容器,所以实现逻辑都是一样的,殊途同归,只不过通过父子容器的构造方式使得我们可以很方便的扩展Spring。
总结
本篇是关于IOC实现的一些补充,最重要的是要理解循环依赖的解决办法,其次SpringBoot零配置实现原理虽然这里只是简单起了个头,但需要好好阅读源码分析。另外还有很多细节,不可能全都讲到,需要我们自己反复琢磨,尤其是Bean实例化那一块,这将是后面我们理解AOP的基础。希望大家多多支持。
加载全部内容