Java8 Lambda嵌套循环 java lambda循环_使用Java 8 Lambda简化嵌套循环操作
dnc8371 人气:0java lambda循环
对于每个经常需要在Java 8(或更高版本)中使用多维数组的人来说,这只是一个快速技巧。
在这种情况下,您可能经常会以类似于以下代码的结尾:
float[][] values = ...
for (int i = 0; i < values.length; i++) {
for (int k = 0; k < values[i].length; k++) {
float value = values[i][k];
// do something with i, k and value
}
}
如果幸运的话,可以用for-each循环替换循环。 但是,循环内的计算通常需要索引。
在这种情况下,您可以提出一个简单的实用程序方法,如下所示:
private void loop(float[][] values, BiConsumer<Integer, Integer> consumer) {
for (int i = 0; i < values.length; i++) {
for (int k = 0; k < values[i].length; k++) {
consumer.accept(i, k);
}
}
}
现在,我们可以像这样循环遍历数组索引:
float[][] values = ...
loop(values, (i, k) -> {
float value = values[i][k];
// do something with i, k and value
});
这样,您可以使循环代码脱离主要逻辑。
当然,您应该更改所示的loop()方法,使其适合您的个人需求。
翻译自: https://www.javacodegeeks.com/2016/04/simplifying-nested-loops-java-8-lambdas.html
补充知识:JAVA8-lambda表达式-并行流,提升效率的利器?
写在前面的话
在前面我们已经看过了一些流的处理,那么Lambda除了在写法上的不同,还有其它什么作用呢?当然有,就是数据并行化处理!
它在某些场景下可以提高程序的性能。我们先看一个前面的例子,查找所有的男同学
// 流方式
List<Person> newBoys = personList.stream().filter(p -> 1 == p.getSex()).collect(Collectors.toList());
现在用并行流改写一下
// 流方式:找出所有男同学
List<Person> newBoys = personList.parallelStream().filter(p -> 1 == p.getSex()).collect(Collectors.toList());
细心的同学已经发现区别了,stream与parallelStream,是的,要用并行流parallelStream,就是这么简单!
什么是并行
有必要尝试解释一下,什么是数据并行化
Java支持多线程,可以同时开启多个任务。引入多线程的原因在于,线程可能会阻塞,CPU会主动切分时间片,只有分配到时间片的线程才会运行。而现代的处理器,几乎都是多核的,即多个CPU,如何才能更高效的利用硬件呢,多线程。
并行和多线程是有区别的,比如运送一堆货物,如果只有一辆车(单线程),肯定慢,平时如果货少,那还能应付过来 ,如果比如某宝的"双十一",那就肯定快递像垃圾一样如山,怎么办呢?我们可以增加车辆(多线程),那么肯定能加快运送速度。但是有一个前提,必须是多条道(多核CPU)。而在有些只有单个出口的地方,还必须排队(并发,线程安全)
而并行的针对同一个任务的。比如还是一辆车的货,10000件,全部放在A车上,要跑N个小时。现在取出一半放到B车上,理论上A,B2车同时跑,是不是会理快呢?嘿嘿嘿,这就是说的数据并行化,这里不会涉及并发。而这一切,Java8的并行流都在底层帮我们实现了
一定会更快?
纸上得来终觉浅,绝知此事要躬行!我们来看下,前面2个代码的分别执行时间
@Test
public void test() {
// 数据并行化处理
// 学生集合
Person kobe = new Person("kobe", 40, 1);
Person jordan = new Person("jordan", 50, 1);
Person mess = new Person("mess", 20, 2);
List<Person> personList = Arrays.asList(kobe, jordan, mess);
long beginTime = System.currentTimeMillis();
// 原来的方式
List<Person> oldBoys = new ArrayList<>(personList.size());
for (Person p : personList) {
// 性别男
if (p.getSex() == 1) {
oldBoys.add(p);
}
}
long endTime = System.currentTimeMillis();
log.info("原来的方式 take time:" + (endTime - beginTime));
beginTime = System.currentTimeMillis();
// 流方式:找出所有男同学
List<Person> newBoys = personList.stream()
.filter(p -> 1 == p.getSex())
.collect(Collectors.toList());
endTime = System.currentTimeMillis();
log.info("流方式 take time:" + (endTime - beginTime));
beginTime = System.currentTimeMillis();
// 流方式:找出所有男同学
List<Person> parallelBoys = personList.parallelStream()
.filter(p -> 1 == p.getSex())
.collect(Collectors.toList());
endTime = System.currentTimeMillis();
log.info("并行流方式 take time:" + (endTime - beginTime));
}

咦,是不是很奇怪,原来的for循环方式最快?多执行几次,发现结果也是这样的,那真是这样吗,我们把数据量扩大试试

还是更慢,换个方法试试
@Test
public void test() {
// 学生集合
List<Person> personList = new ArrayList<>(1000000);
for (int i = 0, j = 1000000; i < j; i++) {
int sex = i % 2;
Person p = new Person(String.valueOf(i), i, sex);
personList.add(p);
}
long beginTime2 = System.currentTimeMillis();
// 流方式:年龄之和
int parallelAges = personList.parallelStream().mapToInt(p -> p.getAge()).sum();
long endTime2 = System.currentTimeMillis();
log.info("并行流方式 take time:" + (endTime2 - beginTime2));
log.info("parallelAges:" + parallelAges);
long beginTime = System.currentTimeMillis();
// 原来的方式
int totalAge = 0;
for (Person p : personList) {
// 年龄之和
totalAge = totalAge + p.getAge();
}
long endTime = System.currentTimeMillis();
log.info("原来的方式 take time:" + (endTime - beginTime));
log.info("totalAge:" + totalAge);
}
看看结果,还是更慢。。。这倒很出我意外,崩溃了,

可能跟我机器有关吧。所以还是需要找地方验证,如果哪位同学能解答一下,欢迎指教
这里引用一下《java8函数式编程》的结论

一些条件
输入数据的大小。
理论上输入的数据越大,操作越复杂,并行流的效果越好。因为拆分数据处理,最后合并结果都会带来额外的开销。我们可以通过修改前面的例子,personList的大小来观察
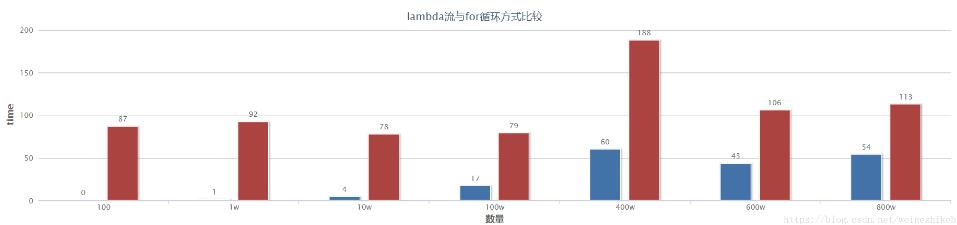
可以看到,数据越大,并行效果越好。当然,真实项目中的处理远比上面复杂,而超过1000w的数据,我本地机器就OOM了尴尬
数据结构
我们通常是操作集合。一般来说,越好分割的并行速度越快。比如ArrayList,数组等支持随机读取的,效果较好。
HashSet,TreeSet,这类不容易公平的分解。而LinkedList,Stream.iterator等分解就比较困难的,效果是比较差的
装箱
处理包装类比基本类型花的时间多,肉眼可见
核的数量
当然,如果核的数量越多,获得潜在并行提升速度的赶快。比如4核一般比双核快,对吧
以上这篇java lambda循环_使用Java 8 Lambda简化嵌套循环操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容