200 Dubbo-thread 线程 为什么程序中突然多了 200 个 Dubbo-thread 线程的说明
回归心灵 人气:0背景
在某次查看程序线程堆栈信息时,偶然发现有 200 个 Dubbo-thread 线程,而且大部分都处于 WAITING 状态,如下所示:
"Dubbo-thread-200" #160932 daemon prio=5 os_prio=0 tid=0x00007f5af9b54800 nid=0x79a6 waiting on condition [0x00007f5a9acd5000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000000c78f1240> (a java.util.concurrent.SynchronousQueue$TransferStack) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:458) at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:362) at java.util.concurrent.SynchronousQueue.take(SynchronousQueue.java:924) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Locked ownable synchronizers: - None
为什么会有这么多 Dubbo-thread 线程呢?这些线程有什么作用呢?带着疑问就去研究了下源码。
源码分析
Dubbo (2.7.5 版本)的线程池 ThreadPool 有四种具体的实现类型:
fixed=org.apache.dubbo.common.threadpool.support.fixed.FixedThreadPool cached=org.apache.dubbo.common.threadpool.support.cached.CachedThreadPool limited=org.apache.dubbo.common.threadpool.support.limited.LimitedThreadPool eager=org.apache.dubbo.common.threadpool.support.eager.EagerThreadPool
程序通过调用具体实现类的 getExecutor(URL url) 方法来创建线程池。而调用该方法的只有 DefaultExecutorRepository 类的 createExecutor 方法,该方法会根据 url 上的参数 threadpool=cached 来决定创建那种类型的线程池。createExecutor 是一个私有方法,调用它的有下面两个方法:
/**
* Get called when the server or client instance initiating.
*
* @param url
* @return
*/
public synchronized ExecutorService createExecutorIfAbsent(URL url) {
String componentKey = EXECUTOR_SERVICE_COMPONENT_KEY;
if (CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY))) {
componentKey = CONSUMER_SIDE;
}
Map<Integer, ExecutorService> executors = data.computeIfAbsent(componentKey, k -> new ConcurrentHashMap<>());
Integer portKey = url.getPort();
ExecutorService executor = executors.computeIfAbsent(portKey, k -> createExecutor(url));
// If executor has been shut down, create a new one
if (executor.isShutdown() || executor.isTerminated()) {
executors.remove(portKey);
executor = createExecutor(url);
executors.put(portKey, executor);
}
return executor;
}
public ExecutorService getExecutor(URL url) {
String componentKey = EXECUTOR_SERVICE_COMPONENT_KEY;
if (CONSUMER_SIDE.equalsIgnoreCase(url.getParameter(SIDE_KEY))) {
componentKey = CONSUMER_SIDE;
}
Map<Integer, ExecutorService> executors = data.get(componentKey);
/**
* It's guaranteed that this method is called after {@link #createExecutorIfAbsent(URL)}, so data should already
* have Executor instances generated and stored.
*/
if (executors == null) {
logger.warn("No available executors, this is not expected, framework should call createExecutorIfAbsent first " +
"before coming to here.");
return null;
}
Integer portKey = url.getPort();
ExecutorService executor = executors.get(portKey);
if (executor != null) {
if (executor.isShutdown() || executor.isTerminated()) {
executors.remove(portKey);
executor = createExecutor(url);
executors.put(portKey, executor);
}
}
return executor;
}
对于上面第一个方法,备注已经说明在服务提供者或者服务消费者初始化的时候会调用,通过debug 可以得出:服务提供者初始化会创建线程名为 DubboServerHandler-10.12.16.67:20880-thread 的线程池,服务消费者会创建线程名为 DubboClientHandler-10.12.16.67:20880-thread 的线程池。
这里需要说明下,Dubbo 创建的线程池会存储在 Map 中共享使用:
private ConcurrentMap<String, ConcurrentMap<Integer, ExecutorService>> data = new ConcurrentHashMap<>();
外面的 key 表示服务提供方还是消费方,里面的 key 表示服务暴露的端口号,也就是说消费方对于相同端口号的服务只会创建一个线程池,共享同一个线程池进行服务请求和消息接收后一系列处理。
显然和 Dubbo-thread 名不一样,那就很有可能是通过调用第二个方法创建的线程池。第二个方法的调用往上追溯就比较分散了,找不到什么有用的信息。
再看方法具体内容,当已经创建的线程池关闭或终止时会重新创建新的线程池。然后就推测什么情况下线程池会被关闭或终止,在服务重启后输出堆栈信息并没有 Dubbo-thread 线程,然后就猜测消费方和提供方连接断开会不会触发线程池关闭,于是重启了服务提供方,果然重现了Dubbo-thread 线程。
然后在 Dubbo 的具体线程池创建方法中添加日志,输出调用栈信息(通过产生一个异常输出调用信息)。
如下图:
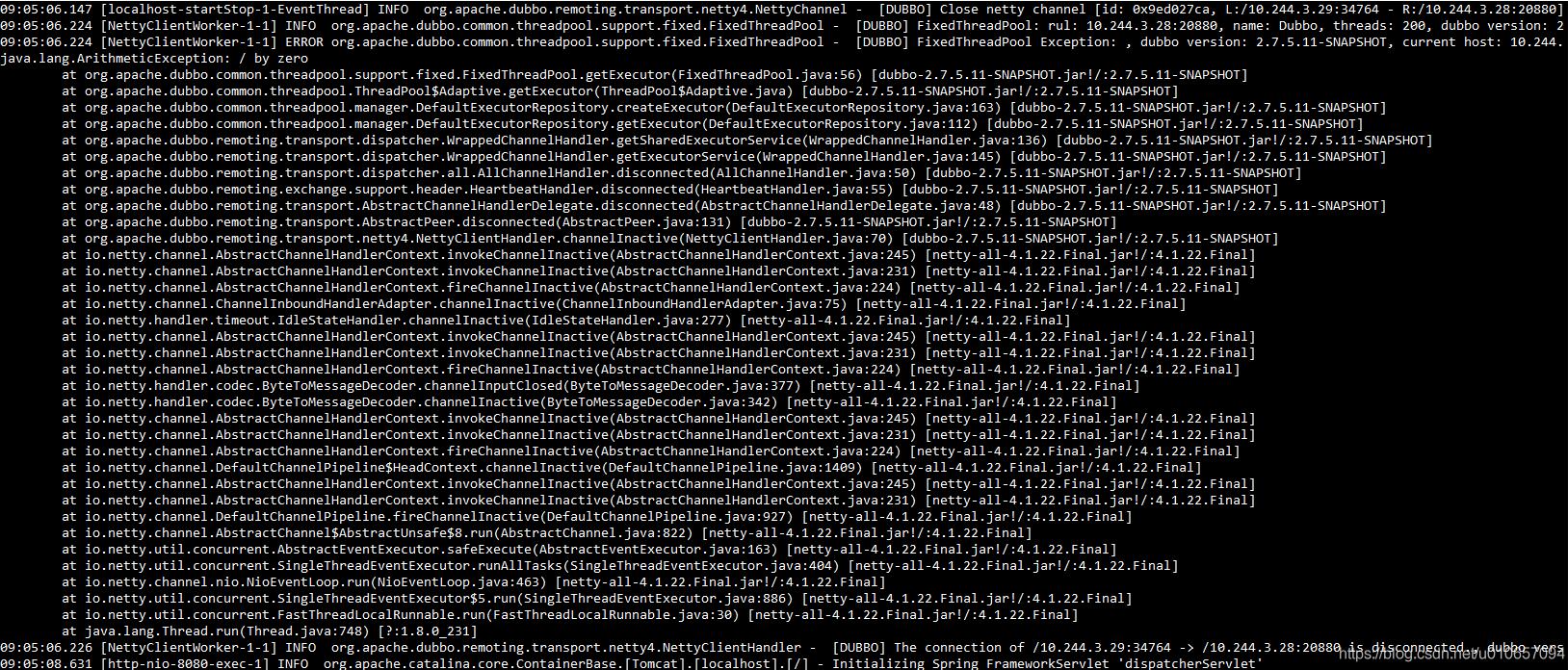
在这里插入图片描述可以看到当 channel 失效时会调用 disconnected 方法,最终会调用 DefaultExecutorRepository 类的 getExecutor 创建线程池,当服务提供者重启时,消费方相应的线程池会被shutdown。
重现创建线程池所用的 URL 是 WrappedChannelHandler 类的 URL,该值是在服务启动初始化时设置的,该值的设置要早于 AbstractClient 客户端 Executor 初始化。
因此由于 channel 断开而重新创建的线程池所用的 URL 和客户端初始创建线程池用的 URL 可能是不同的,特别是在没有配置 consumer 的线程池类型时,初始创建的 Cached 类型线程池,线程名称是 DubboClientHandler…。
而重新创建所用 URL 是没有经过下面方法设置的,因此就会创建默认类型为 fixed 的线程池,线程数为默认 200,线程名为 Dubbo…。
private void initExecutor(URL url) {
url = ExecutorUtil.setThreadName(url, CLIENT_THREAD_POOL_NAME);
url = url.addParameterIfAbsent(THREADPOOL_KEY, DEFAULT_CLIENT_THREADPOOL);
executor = executorRepository.createExecutorIfAbsent(url);
}
总结
那么,就可以知道 Dubbo-thread 线程池的创建是由于服务消费方和提供方之间连接断开而创建的线程池,代替程序启动初始化时创建的 DubboClientHandler 线程池。主要做一些 channel 断开后续一些处理,还有接收服务端消息后的反序列化等操作,具体的可以看类 ThreadlessExecutor(同步调用处理类) 、ChannelEventRunnable(channel 不同状态处理,包括:连接、接收到消息、断开链接等)。
还有一个要注意到点是,如果没有配置consumer.threadpool 类型、therads 等信息,那么断开连接后再创建的线程池将会是 fixed 类型的线程池,线程数为默认 200。
以上这篇为什么程序中突然多了 200 个 Dubbo-thread 线程的说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容