Python js解密 Python实现JS解密并爬取某音漫客网站
松鼠爱吃饼干 人气:1首先打开网站
https://www.zymk.cn/1/37988.html
打开开发者工具
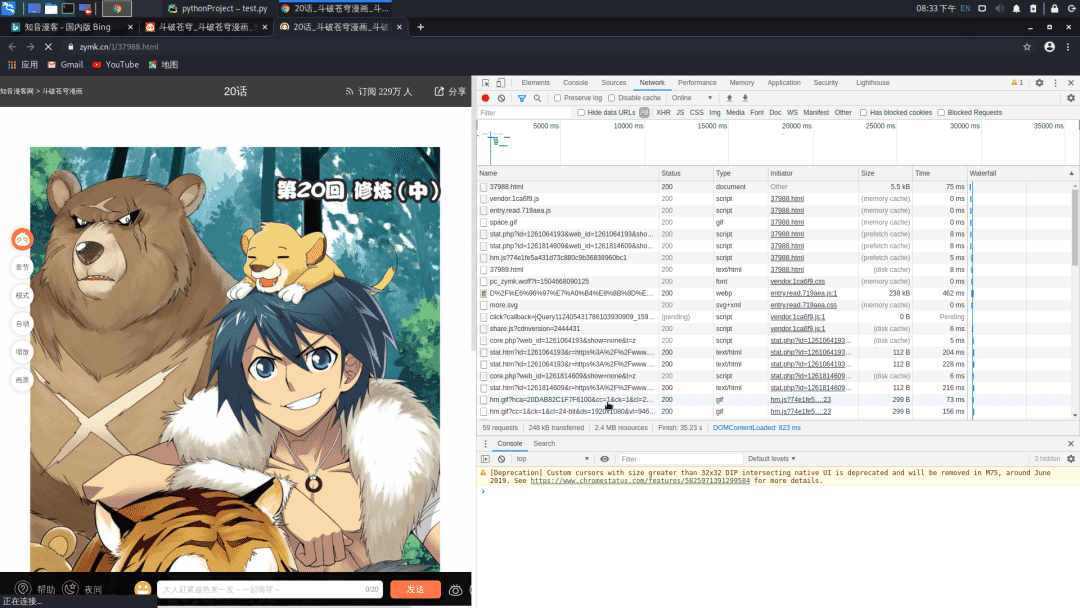
选择XHR标签页,没有找到什么
再查看一下这些图片的URL值
http://mhpic.xiaomingtaiji.net/comic/D%2F%E6%96%97%E7%A0%B4%E8%8B%8D%E7%A9%B9%E6%8B%86%E5%88%86%E7%89%88%2F20%E8%AF%9D%2F1.jpg-zymk.middle.webp
尝试搜索图片元素


发现有一个js文件,打开搜索
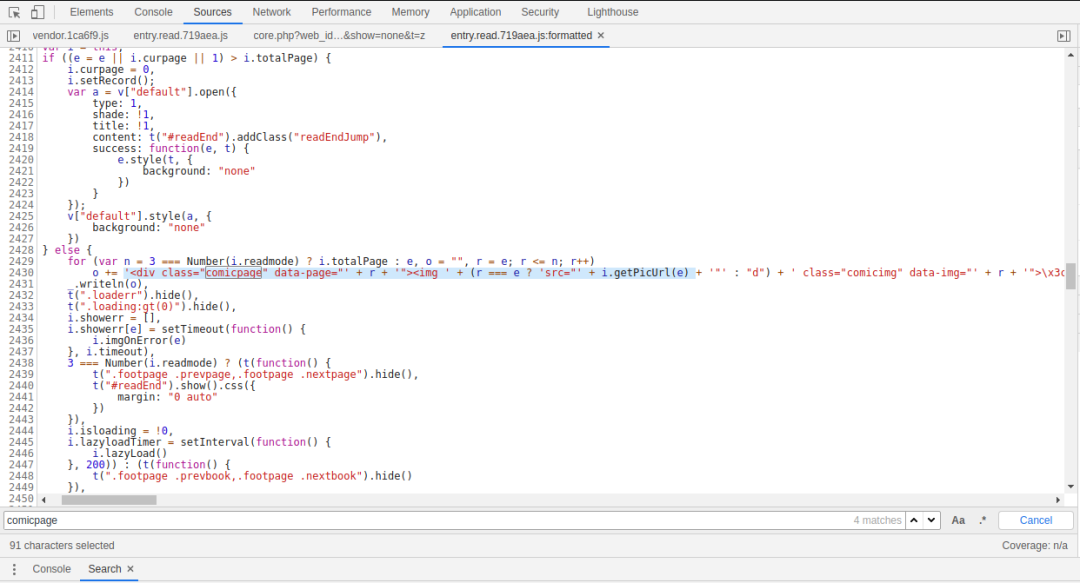
发现这里有一个疑点,这不是html里面的字段吗,那么 “i.getPicUrl(e)” 不就是那个图片的URL的值了吗
在这里下一个断点,走你
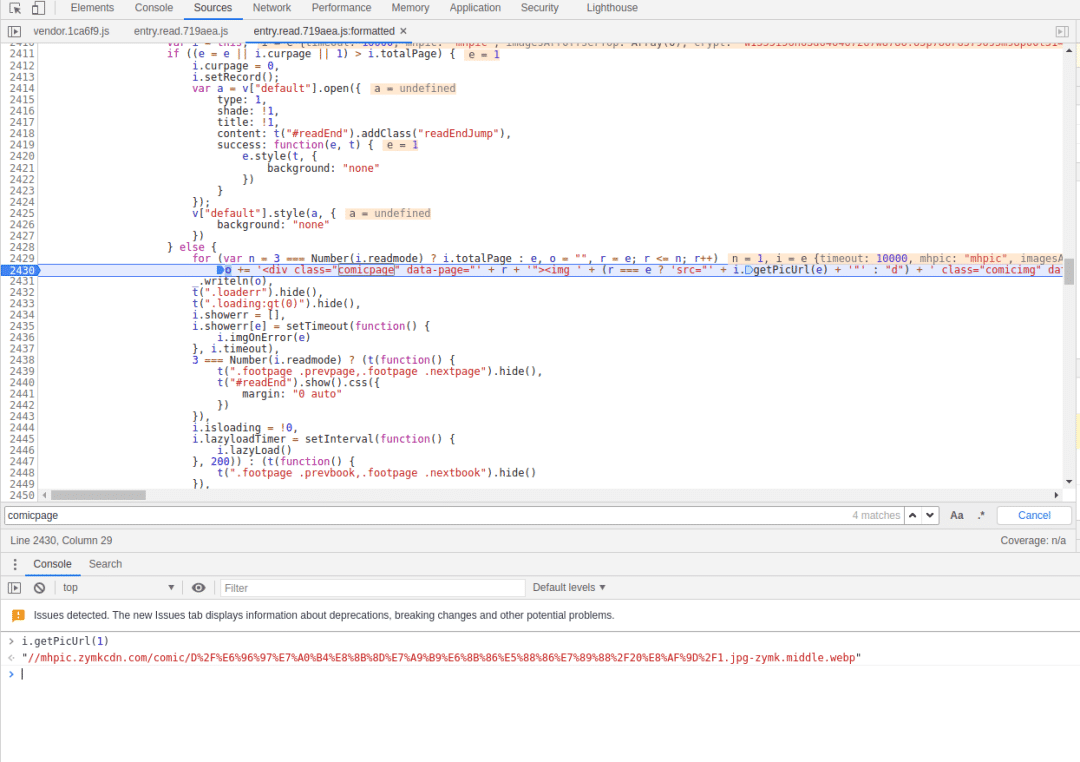
果然,这个就那个图片URL生成的切入点,现在就是看调用栈,找到这个函数的起点,点击右侧的 ”e.init“,这里有一个setInitData函数,从名字来看,应该就是设置初始数据的地方,在这里下一个断点,进去看看
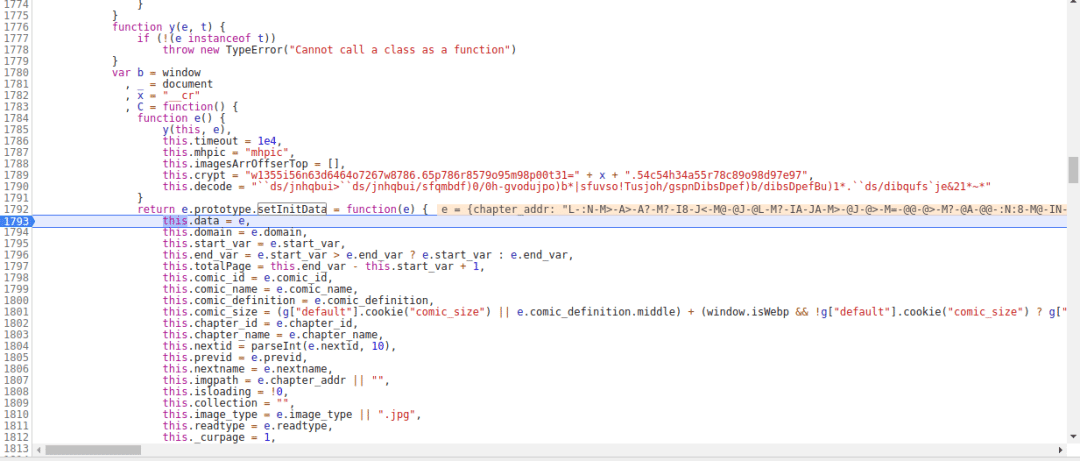
这里有一个this.imgpath,这个应该就是图片的URL值了,点击F10,再单步调式,来到了charcode函数

进去看看,这里应该就是加密函数了

这里一步步调式,不要着急,来到了这里

继续单步调式,在第二次打开这么VM文件的时候,”__cr.imgpath“这个看起来很熟悉呀
Plain Text
"L-:N-M>-A>-A?-M?-I8-J<-M@-@J-@L-M?-IA-JA-M>-@J-@>-M=-@@-@>-M?-@A-@@-:N:8-M@-IN-AL-:N"
打开页面源代码,就在这里啦,不仅仅有图片的URL加密值,还有其他数据,这些都是在后面图片URL拼接需要使用到的
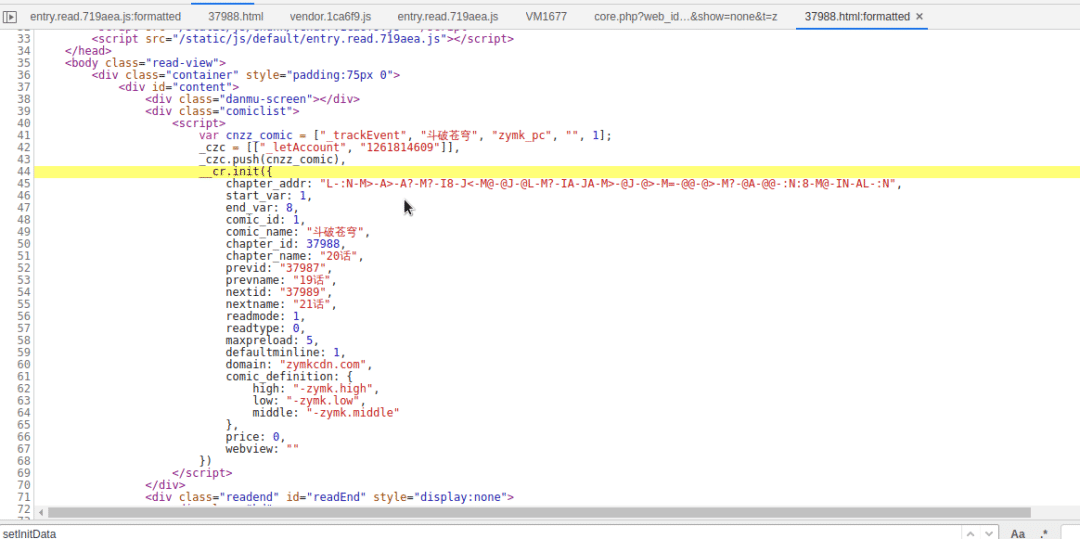
现在我们再重新看看那个加密函数,它无非就是遍历那个加密值的每个字符,获取其Unicode值,再与__cr.chapter_id进行相关运算,然后再得到的Unicode数值返回字符
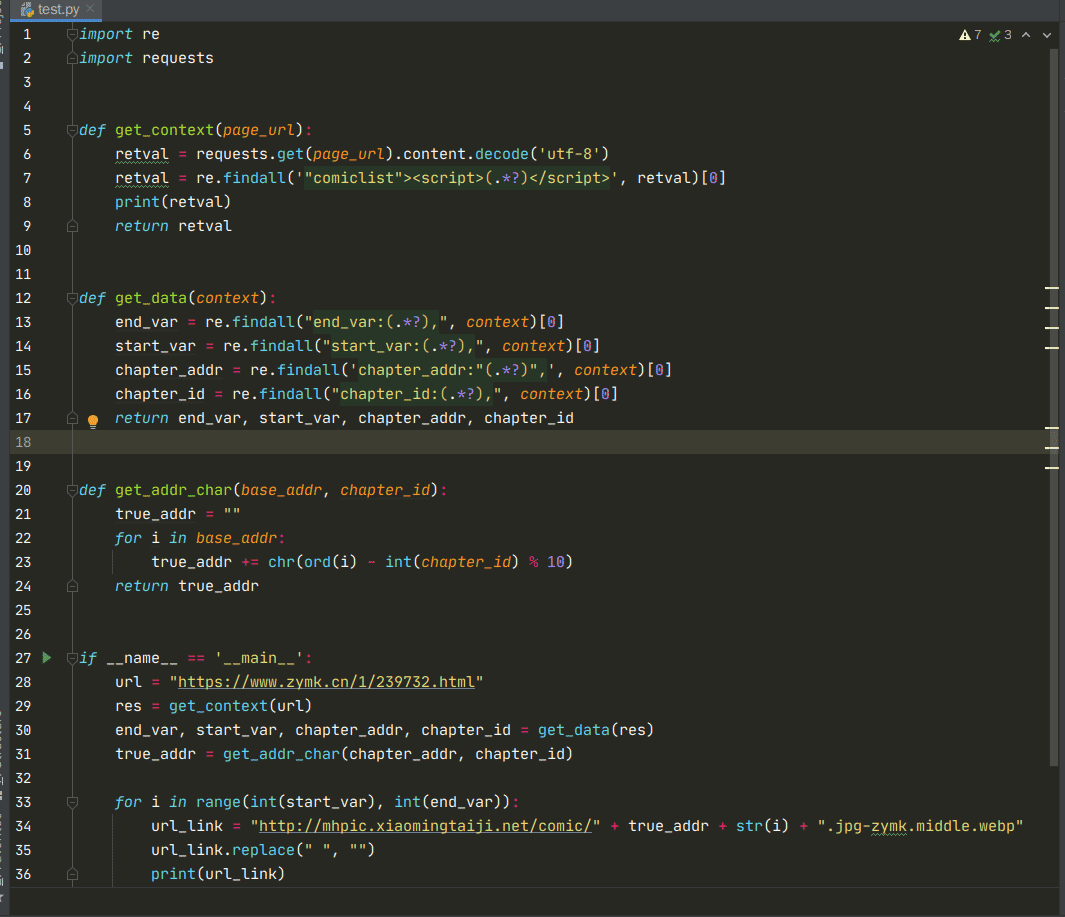
现在我们可以用python仿写这个算法

接下就是平常get请求获取必要的数据了,通过正则获取元素,拼接,以下是源码
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
加载全部内容