时间序列数据库(TSDB)初识与选择
公众号JavaStorm 人气:5时间序列数据库(TSDB)初识与选择
本文作者由 MageByte 团队的 「借来方向」编写,关注公众号 给你更多硬核技术
背景
这两年互联网行业掀着一股新风,总是听着各种高大上的新名词。大数据、人工智能、物联网、机器学习、商业智能、智能预警啊等等。
以前的系统,做数据可视化,信息管理,流程控制。现在业务已经不仅仅满足于这种简单的管理和控制了。数据可视化分析,大数据信息挖掘,统计预测,建模仿真,智能控制成了各种业务的追求。
“所有一切如泪水般消失在时间之中,时间正在死去“,以前我们利用互联网解决现实的问题。现在我们已经不满足于现实,数据将连接成时间序列,往前可以观其历史,揭示其规律性,往后可以把握其趋势性,预测其走势。
我们开始存储大量的数据,并总结出这些数据的结构特点和常见使用场景,不断改进和优化,创造了一种新型的数据库分类——时间序列数据库(time series database).
时间序列模型
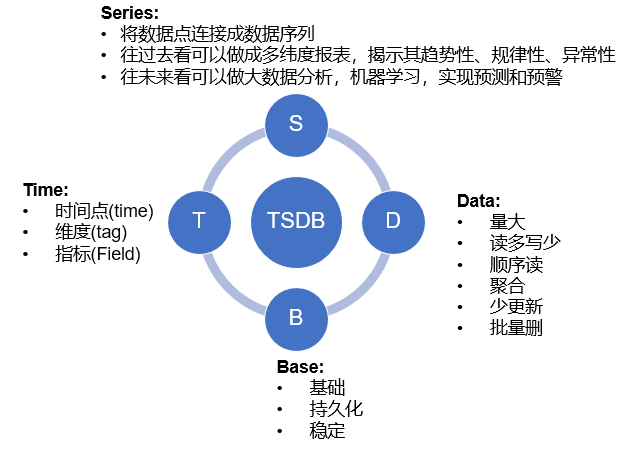
时间序列数据库主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
每个时序点结构如下:
timestamp: 数据点的时间,表示数据发生的时间。 metric: 指标名,当前数据的标识,有些系统中也称为 name。 value: 值,数据的数值,一般为 double 类型,如 cpu 使用率,访问量等数值,有些系统一个数据点只能有一个 value,多个 value 就是多条时间序列。有些系统可以有多个 value 值,用不同的 key 表示 tag: 附属属性。
实现
假如我想记录一系列传感器的时间序列数据。数据结构如下:
* 标识符:device_id,时间戳
* 元数据:location_id,dev_type,firmware_version,customer_id
* 设备指标:cpu_1m_avg,free_mem,used_mem,net_rssi,net_loss,电池
* 传感器指标:温度,湿度,压力,CO,NO2,PM10
如果使用传统 RDBMS 存储,建一张如下结构的表即可:
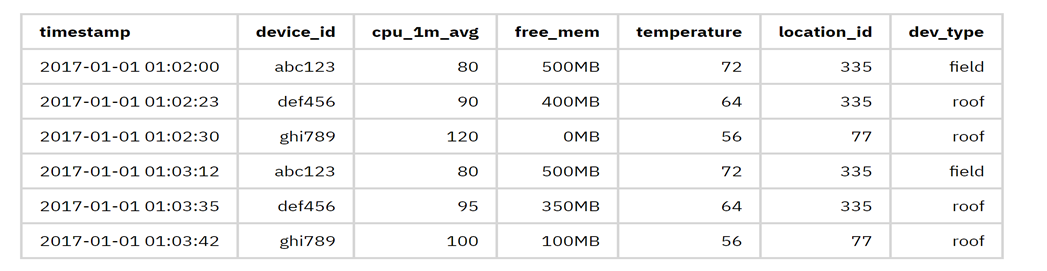 如此便是一个最简单的时间序列库了。但这只是满足了时间序列数据模型的需要。我们还需要在性能,高效存储,高可用,分布式和易用性上做更多的事情。
如此便是一个最简单的时间序列库了。但这只是满足了时间序列数据模型的需要。我们还需要在性能,高效存储,高可用,分布式和易用性上做更多的事情。
大家可以思考思考,如果让我们自己来实现一个时间序列数据库,你会怎么设计,你会考虑哪些性能上的优化,又如何做到高可用,怎样做到简单易用。
Timescale
这个数据库其实就是一个基于传统关系型数据库 postgresql 改造的时间序列数据库。了解 postgresql 的同学都知道,postgresql 是一个强大的,开源的,可扩展性特别强的一个数据库系统。
于是 timescale.inc 在 postgresql 架构上开发了 Timescale,一款兼容 sql 的时序数据库。 作为一个 postgresql 的扩展提供服务。其特点如下:
基础:
支持所有 PostgreSQL 原生 SQL,包含完整 SQL 接口(包括辅助索引,非时间聚合,子查询,JOIN,窗口函数)。 用 PostgreSQL 的客户端或工具,可以直接应用到该数据库,不需要更改。 时间为导向的特性,API 功能和相应的优化。 可靠的数据存储。
扩展:
透明时间/空间分区,用于放大(单个节点)和扩展。 高数据写入速率(包括批量提交,内存中索引,事务支持,数据备份支持)。 单个节点上的大小合适的块(二维数据分区),以确保即使在大数据量时也可快速读取。 块之间和服务器之间的并行操作。
劣势:
因为 TimescaleDB 没有使用列存技术,它对时序数据的压缩效果不太好,压缩比最高在 4X 左右 目前暂时不完全支持分布式的扩展(正在开发相关功能),所以会对服务器单机性能要求较高
其实大家都可以去深入了解一下这个数据库。对 RDBMS 我们都很熟悉,了解这个可以让我们对 RDBMS 有更深入的见解,了解其实现机制,存储机制。在对时间序列的特殊化处理之中,我们又可以学到时间序列数据的特点,并学习到如何针对时间序列模型去优化 RDBMS。
之后我们也可以写一篇文章来深入的了解一下这个数据库的特点。
Influxdb
Influxdb 是业界比较流行的一个时间序列数据库,特别是在 IOT 和监控领域十分常见。其使用 go 语言开发,突出特点是性能。 特性:
高效的时间序列数据写入性能。自定义 TSM 引擎,快速数据写入和高效数据压缩。 无额外存储依赖。 简单,高性能的 HTTP 查询和写入 API。 以插件方式支持许多不同协议的数据摄入,如:graphite,collectd,和 openTSDB SQL-like 查询语言,简化查询和聚合操作。 索引 Tags,支持快速有效的查询时间序列。 保留策略有效去除过期数据。 连续查询自动计算聚合数据,使频繁查询更有效。
Influxdb 已经将分布式版本转为闭源。所以在分布式集群这块是一个弱点,需要自己实现。
OpenTSDB
The Scalable Time Series Database. 打开 OpenTSDB 官网,第一眼看到的就是这句话。可见其将 Scalable 作为自己重要的”卖点“。OpenTSDB 运行在 Hadoop 和 HBase 上,其充分利用 HBase 的特性。通过独立的 Time Series Demon(TSD)提供服务,所以它可以通过增减服务节点来轻松扩缩容。
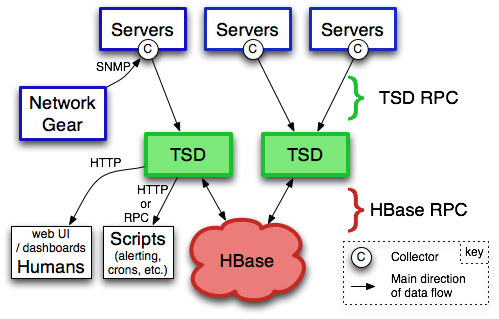
Opentsdb 是一个基于 Hbase 的时间序列数据库(新版也支持 Cassandra)。
其基于 Hbase 的分布式列存储特性实现了数据高可用,高性能写的特性。受限于 Hbase,存储空间较大,压缩不足。依赖整套 HBase, ZooKeeper
采用无模式的 tagset 数据结构(sys.cpu.user 1436333416 23 host=web01 user=10001)
结构简单,多 value 查询不友好
HTTP-DSL 查询
OpenTSDB 在 HBase 上针对 TSDB 的表设计和 RowKey 设计值得我们深入学习的一个特点。有兴趣的同学可以找一些详细的资料学习学习。
Druid
Druid 是一个实时在线分析系统(LOAP)。其架构融合了实时在线数据分析,全文检索系统和时间序列系统的特点,使其可以满足不同使用场景的数据存储。
采用列式存储:支持高效扫描和聚合,易于压缩数据。 可伸缩的分布式系统:Druid 自身实现可伸缩,可容错的分布式集群架构。部署简单。 强大的并行能力:Druid 各集群节点可以并行地提供查询服务。 实时和批量数据摄入:Druid 可以实时摄入数据,如通过 Kafka。也可以批量摄入数据,如通过 Hadoop 导入数据。 自恢复,自平衡,易于运维:Druid 自身架构即实现了容错和高可用。不同的服务节点可以根据负载需求添加或减少节点。 容错架构,保证数据不丢失:Druid 数据可以保留多副本。另外可以采用 HDFS 作为深度存储,来保证数据不丢失。 索引:Druid 对 String 列实现反向编码和 Bitmap 索引,所以支持高效的 filter 和 groupby。 基于时间分区:Druid 对原始数据基于时间做分区存储,所以 Druid 对基于时间的范围查询将更高效。 自动预聚合:Druid 支持在数据摄入期就对数据进行预聚合处理。
Druid 架构蛮复杂的。其按功能将整个系统细分为多种服务,query、data、master 不同职责的系统独立部署,对外提供统一的存储和查询服务。其以分布式集群服务的方式提供了一个底层数据存储的服务。
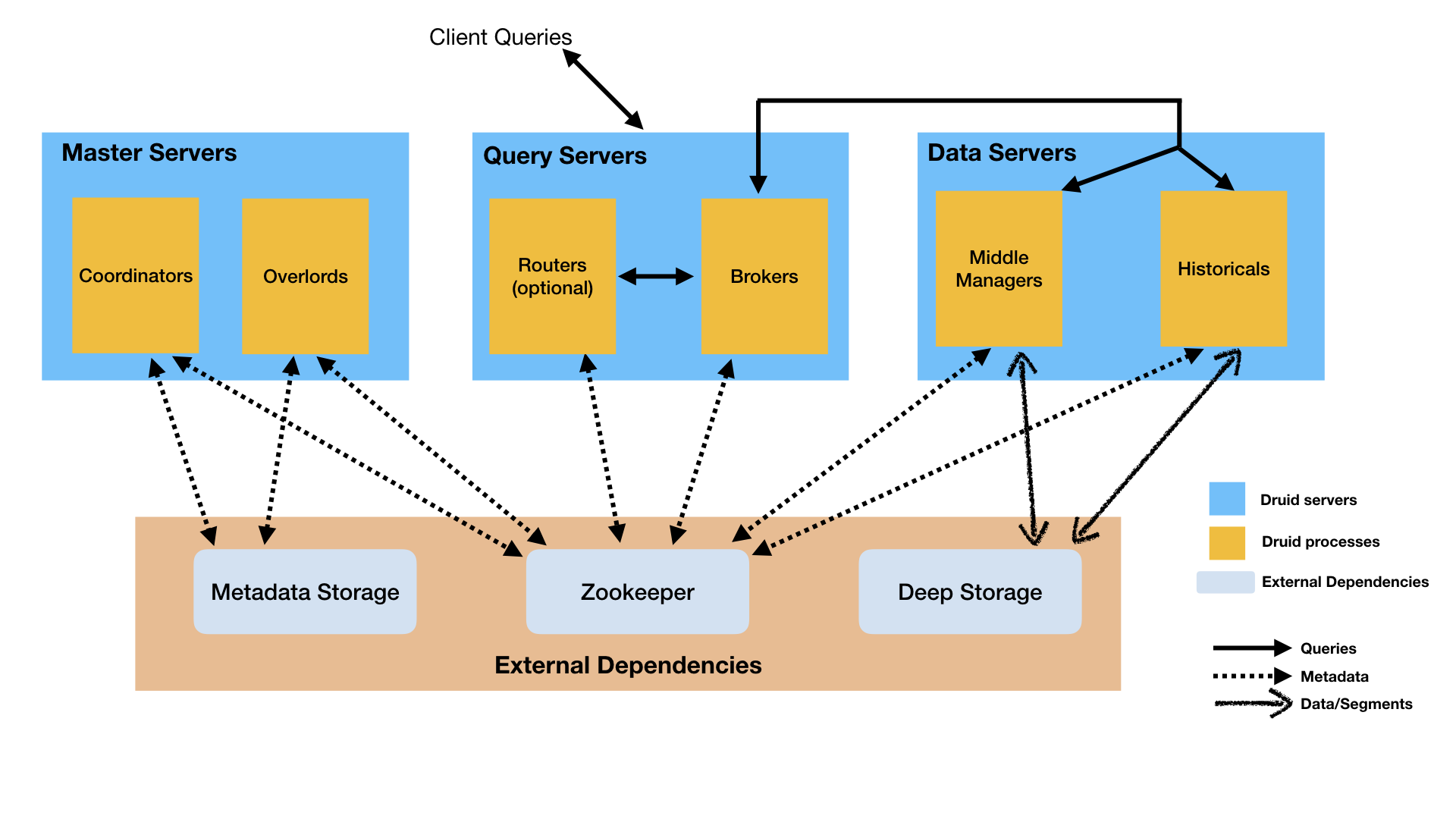
Druid 在架构上的设计很值得我们学习。如果你不仅仅对时间序列存储感兴趣,对分布式集群架构也有兴趣,不妨看看 Druid 的架构。另外 Druid 在 segment(Druid 的数据存储结构)的设计上也是一大亮点,即实现了列式存储,又实现了反向索引。
Elasticsearch
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名。
Elasticsearch 以 ELK stack 被人所熟知。许多公司基于 ELK 搭建日志分析系统和实时搜索系统。之前我所在团队在 ELK 的基础上开始开发 metric 监控系统。即想到了使用 Elasticsearch 来存储时间序列数据库。对 Elasticserach 的 mapping 做相应的优化,使其更适合存储时间序列数据模型,收获了不错的效果,完全满足了业务的需求。后期发现 Elasticsearch 新版本竟然也开始发布 Metrics 组件和 APM 组件,并大量的推广其全文检索外,对时间序列的存储能力。真是和我们当时的想法不谋而合。
Elasticsearch 的时序优化可以参考一下这篇文章:《elasticsearch-as-a-time-series-data-store》
也可以去了解一下 Elasticsearch 的 Metric 组件Elastic Metrics
Beringei
Beringei 是 Facebook 在 2017 年最新开源的一个高性能内存时序数据存储引擎。其具有快速读写和高压缩比等特性。
2015 年 Facebook 发表了一篇论文《Gorilla: A Fast, Scalable, In-Memory Time Series Database 》,Beringei 正是基于此想法实现的一个时间序列数据库。
Beringei 使用 Delta-of-Delta 算法存储数据,使用 XOR 编码压缩数值。使其可以用很少的内存即可存储下大量的数据。
如何选择一个适合自己的时间序列数据库
Data model
时间序列数据模型一般有两种,一种无 schema,具有多 tag 的模型,还有一种 name、timestamp、value 型。前者适合多值模式,对复杂业务模型更适合。后者更适合单维数据模型。
Query language
目前大部分 TSDB 都支持基于 HTTP 的 SQL-like 查询。
Reliability
可用性主要体现在系统的稳定高可用上,以及数据的高可用存储上。一个优秀的系统,应该有一个优雅而高可用的架构设计。简约而稳定。
Performance
性能是我们必须考虑的因素。当我们开始考虑更细分领域的数据存储时,除了数据模型的需求之外,很大的原因都是通用的数据库系统在性能上无法满足我们的需求。大部分时间序列库倾向写多读少场景,用户需要平衡自身的需求。下面会有一份各库的性能对比,大家可以做一个参考。
Ecosystem
我一直认为生态是我们选择一个开源组件必须认真考虑的一个问题。一个生态优秀的系统,使用的人多了,未被发现的坑也将少了。另外在使用中遇到问题,求助于社区,往往可以得到一些比较好的解决方案。另外好的生态,其周边边界系统将十分成熟,这让我们在对接其他系统时会有更多成熟的方案。
Operational management
易于运维,易于操作。
Company and support
一个系统其背后的支持公司也是比较重要的。背后有一个强大的公司或组织,这在项目可用性保证和后期维护更新上都会有较大的体验。
性能对比
| Timescale | InfluxDB | OpenTSDB | Druid | Elasticsearch | Beringei | |
|---|---|---|---|---|---|---|
| write(single node) | 15K/sec | 470k/sec | 32k/sec | 25k/sec | 30k/sec | 10m/sec |
| write(5 node) | 128k/sec | 100k/sec | 120k/sec |
总结
最后总结一下:
如果你想要一个极限性能的系统可以考虑 Beringei 和 InfluxDB,在数据高可用方面,可以采用客户端双写模式来对数据做一个副本,保证数据的可用性。 如果你数据量不大,性能要求也不是特别高,却又点查询,删除和关联查询等需求,不妨考虑一下 Timescale。 如果你间距索引和时间序列的需求。那么 Druid 和 Elasticsearch 是最好的选择。其性能都不差,并且都是高可用容错架构。
最后
之后我们可以来深入了解一两个 TSDB,比如 Influxdb,Druid,Elasticsearch 等。并可以学习一下行存储与列存储的不同,LSM 的实现原理,数值数据的压缩,MMap 提升读写性能的知识等。
关注公众号,掌握更多硬核技术

加载全部内容