MySQL 索引
当年明月123 人气:1MySql 索引
MySql 索引
首先,MySql 支持多种存储引擎,最为常用的是 innodb,MyIsam 也需要了解,其他的存储引擎包括 Archive 等等都要又个印象。
各种存储引擎对于索引的支持也不相同,总结下来,MySql 的索引主要由三种类型,B 树索引,Hash 索引,全文索引。我们只关注 BTree 索引,因为这是我们平常使用 MySql 时主要的打交道的方式。
MySql 中的 B 树索引的物理文件大多是以 Balance Tree 的结构来存储的,也就是所有的实际的数据都存放于 Tree 的叶子节点中,到任何一个叶子节点的最短路径长度都是完全相同的。各个数据库或者存储引擎都会对 B 树索引的存储结构稍加改造,比如 innodb 的 B 树索引实际使用的 B+ 树,也就是在 B 树的结构上做了很小的改动。除了在每一个叶子节点上存放索引的相关信息之外,还存储了只想该叶子节点的后一个叶子节点的指针信息(增加了顺序访问),这也是为了加快检索多个相邻的叶子节点的效率考虑。
什么是索引
定义:索引是为了帮助 MySql 高效获得数据的数据结构。
目的:索引的目的当然是为了快速找到对应的数据了。就比如我们查字典,一定是按照首个字母或者拼音去找而不是翻遍整个字典。
索引原理
索引的原理就是通过不断的缩小范围从而筛选出想要的结果从而避免对整个文件的查找。同时把随机的事件变为顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据库的索引更为复杂,因为不仅面临着等值查询,还有范围查询(<,>,between),模糊查询(like),并集查询(or),多值匹配(in)等等。我们回想字典的例子,能不能把数据分成段,然后分段查询那?比如将 1000 条数据中的 1 到 100 分为第一段,101 到 200 分为第二段...... 这样查第 105 条数据只需要查第一段就可以了。如果是 10000 条那,怎么分段?稍微有算法基础的同学可能会想到搜索树,平均复杂度是 logN,性能不错,但是有时为了提高性能,会把部分数据读入内存中来计算,我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树并不能满足复杂的应用场景。
B+ 树索引结构
上面我们说过简单的搜索树并不能满足数据库的使用场景。我们需要索引做什么那?那就是每次查找数据时能把磁盘 IO 次数控制在一个很小的数量级,最好是常数数量级。因此,一个高度可控的多路搜索树 b+ 树产生了。
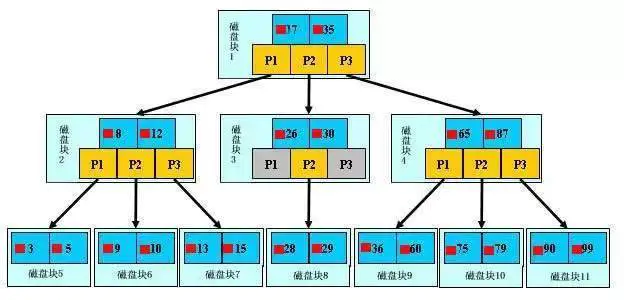
每个磁盘块中包含几个数据项(深蓝色)和指针(黄色),磁盘块1 包含数据项 17 和 35,包含指针 P1,P2,P3,P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块。
真实的数据存在于叶子节点即 3,5,9,10,13,15,28,29,36,60,75,79,90,99。非叶子节点不存储真实数据,只存储搜索方向的数据项。
B+ 树的查找过程
如果我们想要查找 29,那么首先会把磁盘1 家在到内存,此时发生一次 IO,内存中用二分查找确定 29 在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,加载磁盘块 3 到内存,发生第二次 IO。然后锁定磁盘块 8,发生第三次 IO,找到了 29。结束查询,总共发生三次 IO。3 层的 B + 树可以表示上百万的数据,所以上百万的数据的查询只需要三次 IO 就可以完成了,如果没有索引,每个数据项都要发生一次 IO,那么就需要百万次的 IO,成本非常高。
MySql 的索引实现
MySql 中,索引是存储引擎级别的概念,不同的存储引擎对索引的实现方式是不同的。我们主要针对 MyISAM 和 InnoDB 两个存储引擎的索引实现来讨论。
MyISAM 索引实现
MyISAM 引擎使用的是 B+ 树作为索引结构,叶子节点的 data 域存放的是数据记录的地址。

假设我们以 Col1 为主键,那么上图就是 MyISAM 表的主键索引。MyISAM 存储引擎中,主键索引和辅助索引在结构上是没有任何区别的,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。我们来看建立在 Col2 上的辅助索引。
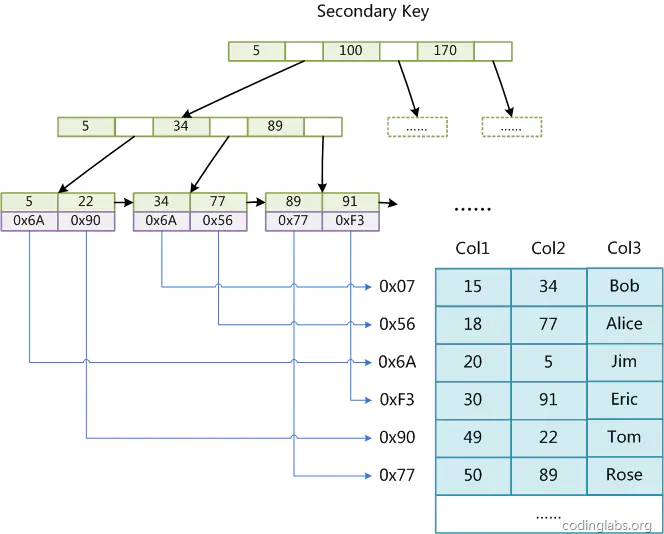
总结:同样也是一颗 B+ 树,data 域保存数据记录的地址。因此,MyISAM 的索引的算法首先按照 B+ 树搜索算法搜索索引,如果指定的 Key 存在,则取出其中 data 域的值,然后读取相关记录。
MyISAM 的索引方式也叫做 “非聚集” 的,之所以这么称呼是为了与 InnoDB 的聚集索引区分的。
InnoDB 索引实现
虽然 InnoDB 也使用 B+ 树作为索引结构,但是具体实现方式与 MyISAM 截然不同。
第一个区别是 InnoDB 的数据文件本身就是索引文件。从上文可以知道,MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录地址。而在 InnoDB 中,表数据文件本身就是 B+ 树组织的一个索引结构,这棵树的叶子节点 data 域保存了完整的数据结构。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
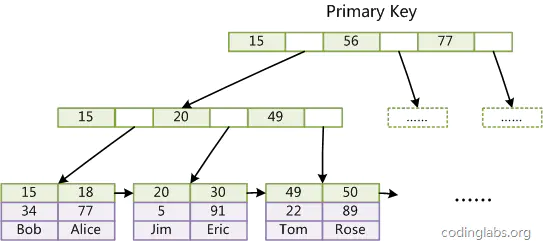
上图是 InnoDB 主索引的示意图,可以看到叶节点包含了完整的数据记录。这种索引也叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集,所以 InnoDB 要求必须有主键索引(MyISAM 可以没有)。如果没有显示指定,MySql 系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,MySQL 自动为 InnoDB 表生成一个隐含字段作为主键。
第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。InnoDB 的所有辅助索引都引用主键作为 data 域。

这里以英文字符的 ASCII 码作为比较标准。聚集索引这种实现方式使得按主键搜索十分搞笑,但是辅助索引搜索需要两遍索引:先检索辅助索引获得主键,然后用主键索引检索记录。
熟悉了 InnoDB 的索引实现后,就明白了为什么不建议使用过长的字段作为主键,因为所有辅助索引都使用主索引,过长的主索引会令辅助索引变的过大。再比如,用非单调的字段作为 InnoDB 的主键不是个好主意,非单调的主键造成插入新纪录时数据文件维持 B+ 树的特性而频繁的分裂调整,使用自增字段作为主键是一个很好的选择。
InnoDB索引和MyISAM索引的区别:
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
建立索引常用技巧
- 最左匹配原则,非常重要的原则,mysql 会一直向右匹配直到遇到范围查询(<,>,between,like)就停止匹配,比如 a=1 and b = 2 and c > 3 and b = 4 如果建立(a,b,c,d)顺序的索引,d 是用不到索引的,如果建立(a,b,d,c)的索引都可以用到。
- = 和 in 可以乱序,比如 a = 1 and b = 2 and c = 3 建立 (a,b,c)所以可以任意顺序。
- 尽量选择区分度高的列作为索引。字段不重复的比例不能太小,唯一键的区分度是 1,而一些状态,性别字段在大数据面前区分度就是 0。
- 索引不能参与计算。比如 from_unixtime(create_time) = ’2014-05-29’ 就不能使用到索引,原因很简单,b+ 树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大,应该把语句写成 create_time = unix_timestamp(’2014-05-29’)。
SQL 调优
一般要进行 SQL 调优,那么就是有慢查询的 SQL,系统或者 server 可以开启慢查询日志。
通过慢查询记录能够记录一些执行时间比较久的 SQL 语句,找出这些语句不意味着工作结束了,我们通常使用 explain 这个命令来查看这些 SQL 语句的执行计划,查看该 SQL 语句有没有使用索引,有没有做全表扫描。
mysql> explain select * from servers;
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | servers | ALL | NULL | NULL | NULL | NULL | 1 | NULL |
+----+-------------+---------+------+---------------+------+---------+------+------+-------+
1 row in set (0.03 sec)各个字段的含义:
- id:表示 SQL 执行的顺序的标识。
- select_type:表示产讯中每个 select 子句的类型。
- table:显示这一行的数据是关于哪张表的,有时不是真实的表名字。
- type:表示MySQL在表中找到所需行的方式,又称“访问类型”。常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)。
- possible_keys:指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
- Key:key列显示MySQL实际决定使用的键(索引),如果没有选择索引,键是NULL。
- key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)。
- ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。
- rows: 表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,理论上行数越少,查询性能越好。
- Extra:该列包含MySQL解决查询的详细信息。
EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划。
加载全部内容