java绿色像素点排序 java根据图片中绿色像素点的多少进行排序
mouguangjun 人气:0前言
一个朋友被绿了,看见绿色就会很伤感,作为好兄弟的我当然看不下去,感觉有我必要也必须做一点什么。正好我又在写java程序,那就写一个小程序帮他把电脑里的图片排一下顺序,根据绿色的程度进行排序,最后把排好序的图片偷偷的放到他的电脑里去。为了好兄弟做这么多的事情,正所谓:事了拂衣去,功藏身与名啊!(当然是倒序排的)
一、利用for循环读取图片
相信学过图像处理的小伙伴都知道,一张图片由很多像素组成(当然,矢量图片除外,大家下来可以了解为啥矢量图片不是由像素点组成的)。因此,不管是什么图片我们都看作是一个平面,因为就可以用坐标的方式去读取图片啦!那就废话不多说直接开始!
二、代码的逻辑
1.先给大家看看主方法里面都有一些什么内容
public static void main(String[] args) {
HashMap<File, Object> imageMap = new HashMap<File, Object>();//用hashMap将文件和对应的像素点数量装到一起
File fileDir = new File("D:\\Download\\TestFile");//将要进行排序的文件目录
File[] listFiles = fileDir.listFiles();
for (File readFile : listFiles) {
getImagePixel(readFile, imageMap);//获取图片的绿色像素点数量的多少
}
HashMapSortUtils hashMapSortUtils = new HashMapSortUtils(imageMap, 1, 3, "Mus");
LinkedHashMap<File,Object> sortFileMap = hashMapSortUtils.sortFileMap();//将图片按照像素点的数量进行排序
hashMapSortUtils.renameFiles(sortFileMap);//将排好序的文件重命名(不然离开控制台就看不到文件的排序了>o<)
System.out.println(imageMap);//这里只是用来看具体像素点有多少的,并没有实际的意义
}
是不是很简单呢?跟大象装冰箱一样,只有三个步骤:
1.将文件目录下的所有图片含有的绿色像素点全部读取出来,然后将对应的文件名和像素点个数暂存在HashMap里;
2.将图片根据绿色像素点的多少进行排序;
3.将排好序的图片重命名,然后进行排序输出(Tips:文件会进行重命名的,所有不要直接在源文件上直接玩喔,注意文件的备份);
好了,那我们就直接开始看每个方法具体是怎样实现的吧,按顺序进行讲解!(以下大家就注意看代码中的注释了,不再做重复的解释了)
2.读取图片像素点的方法
private static HashMap<File, Object> getImagePixel(File readFile, HashMap<File, Object> imageMap) {
int red = 0;//记录像素点的红色
int green = 0;//记录像素点的绿色
int blue = 0;//记录像素点的蓝色
int counter = 0;//程序计数器
BufferedImage bi = null;
try {
bi = ImageIO.read(readFile);//通过ImageIO来读取图片,以便获取图片的RGB信息
} catch (IOException e) {
e.printStackTrace();
}
int width = bi.getWidth();//获取图片的宽度
int height = bi.getHeight();//获取图片的高度
int minx = bi.getMinX();//获取图片的坐标起点x轴
int miny = bi.getMinY();//获取图片的坐标起点y轴
for(int i = minx; i < width; i++){
for(int j = miny; j < height; j++){
int pixel = bi.getRGB(i, j);
red = (pixel & 0xff0000) >> 16;//过滤掉图片的绿色和蓝色
green = (pixel & 0xff00) >> 8;//过滤掉图片的绿色
blue = (pixel & 0xff);//最后剩下的就是蓝色啦
if(green - red > 30 && green - blue > 30){//绿色的范围
counter++;
}
}
}
imageMap.put(readFile, counter);//将文件和像素点的个数记录到HashMap中
return imageMap;
}
3.将图片按照像素点的数量进行排序
由于排序不光在这里可以使用,在其他情况下也可能会使用到(比如说根据文件的创建时间进行排序,都可以用到排序的)。所以我将排序写成了一个抽象类,其他情况下只需要继承这个抽象类,然后具体实现自己想要实现的方法就行了!具体的现如下:
抽象类:
package readcolor;
import java.io.File;
import java.util.HashMap;
import java.util.LinkedHashMap;
public abstract class HashMapSortUtil {
private HashMap<File, Object> sortMap;//全局变量Map,就是主方法需要传过来进行排序的Map
private String prefix;//前缀,用来命名自己的文件 ==> Mus
public abstract LinkedHashMap<File, Object> sortFileMap();//进行排序的方法
public abstract void renameFiles(LinkedHashMap<File, Object> linkedTimeMap);//重命名的方法
public HashMap<File, Object> getSortMap() {
return sortMap;
}
public void setSortMap(HashMap<File, Object> sortMap) {
this.sortMap = sortMap;
}
public String getPrefix() {
return prefix;
}
public void setPrefix(String prefix) {
this.prefix = prefix;
}
}
子类:
package readcolor;
import java.io.File;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.LinkedList;
import java.util.Map.Entry;
import java.util.Set;
public class HashMapSortUtils extends HashMapSortUtil{
private int counter;//计数器,默认从多少开始进行命名 ==> 1
private int nameLength;//命名的长度,其实就是计数器之前需要添加几个0 ==> 3
private int nameExpansion = 0;//记录名字超长了需要进行扩容的次数
//prefix(在父类里面),counter,nameLength组成的结果就是对应的Mus001
private HashMap<File, File> tempFileMap = new HashMap<File, File>();//记录在进行重命名时,目标文件有重复时,将源文件拷贝出来与将要命名的名字记录到HashMap里面
public HashMapSortUtils() {//构造方法
super();
}
public HashMapSortUtils(HashMap<File, Object> sortMap, Integer counter, Integer nameLength, String prefix) {//构造方法
super();
super.setSortMap(sortMap);
super.setPrefix(prefix);
this.counter = counter;
this.nameLength = nameLength;
}
/**
* 将图片按照像素点个数进行排序的方法
* 参数:无
* 返回值:无
* */
@Override
public LinkedHashMap<File, Object> sortFileMap() {
LinkedHashMap<File,Object> linkedHashMap = new LinkedHashMap<File, Object>();
Set<Entry<File, Object>> mapEntries = super.getSortMap().entrySet();//将传进来需要进行排序的HashMap获取到每个节点
LinkedList<Entry<File, Object>> timeList = new LinkedList<Entry<File, Object>>(mapEntries);//将每个节点放到List集合中,方便利用Collections的方法进行排序
Collections.sort(timeList, new Comparator<Entry<File, Object>>() {//利用Comparator接口进行排序
@Override
public int compare(Entry<File, Object> o1, Entry<File, Object> o2) {
if(o1.getValue() == o2.getValue()){//如果两个文件的绿色像素点相同,就用文件的名字进行比较
return o2.getKey().compareTo(o1.getKey());
}
return ((Integer) o2.getValue()).compareTo((Integer)o1.getValue());//利用文件的绿色像素点进行比较
}
});
for (Entry<File, Object> entry : timeList) {//将排好序之后的文件放到LinkedHashMap中,因为如果方法HashMap中的话,你会发现它的顺序又是乱的了-o-
linkedHashMap.put(entry.getKey(), entry.getValue());
}
return linkedHashMap;
}
/**
* 重命名文件的方法
* 参数:linkedTimeMap:需要进行文件重命名的HashMap
* 返回值:无
* */
@Override
public void renameFiles(LinkedHashMap<File, Object> linkedTimeMap) {
Set<Entry<File,Object>> entrySet = linkedTimeMap.entrySet();
for (Entry<File, Object> entry : entrySet) {
renameFile(entry.getKey(), createFileName(entry.getKey())/*根据之前设置文件的名字(counter、nameLength、prefix)生成文件名*/);//重命名文件
}
//最后重命名剩下的源文件的备份文件
renameTempFiles();
}
/**
* 根据之前设置文件的名字(counter、nameLength、prefix)生成文件名
* 参数:oldFile:源文件
* 返回值:生成名字之后的文件
* */
private File createFileName(File oldFile) {
//通过父类获取到prefix
String prefix = super.getPrefix();
//获取结束
String newFileName = "";
newFileName += prefix;//先将前缀拼接上
int nameLen = String.valueOf(counter).length();//获取计数器的长度
if(nameLen > nameLength){//如果计数器超长了,那么命名的长度(nameLength)就需要进行扩容,不然会出现文件名重复的情况
nameLength++;
nameExpansion++;//这里记录是因为,当后面的操作出现错误时,这里可能需要将原来的长度进行恢复
}
if(nameLen <= nameLength){
int d_Value = String.valueOf(Math.pow(10, nameLength) - 1).length() - String.valueOf(counter).length() - 2;//计算需要填补的0的个数,这里减2是因为去除double数据后面的.0
for (int i = 0; i < d_Value; i++) {
newFileName += "0";
}
}
newFileName += counter;//将计数器添加到名字上
String oldFileName = oldFile.getName();//获取源文件的名字
String dirName = oldFile.getParentFile().getAbsolutePath();//获取源文件的上级文件夹的路径
File newFile = new File(dirName + File.separator + newFileName + oldFileName.substring(oldFileName.lastIndexOf(".")));//利用新的文件名生成文件
counter++;//计数器需要进行+1
return newFile;
}
/**
* 将源文件重命名为新文件的名字
* 参数:oldFile:源文件, newFile:新文件
* 返回值:无
* */
private void renameFile(File oldFile, File newFile) {
//=================如果源文件和新文件都存在,并且源文件和新文件的名字不相同,那么就需要将源文件备份处理,等其他文件重命名完之后再执行这类文件的重命名操作=================
if(oldFile.exists() && oldFile.isFile() && newFile.exists() && newFile.isFile()){
if(!newFile.getName().equals(oldFile.getName())){
//===============================将源文件做备份处理===============================
File oldFileTemp = null;
int fileTempCounter = 0;
//使用do...while...循环确保暂存文件中没有重复的名字
do{
oldFileTemp = new File(oldFile.getAbsolutePath() + fileTempCounter + System.currentTimeMillis());
fileTempCounter++;
}while(oldFileTemp.exists() && oldFileTemp.isFile());
//将源文件的内容复制到备份文件中
try{
new FileServiceImpl().copyFile(oldFile, oldFileTemp);
}catch (Exception e){
e.printStackTrace();
}
//删除源文件
oldFile.delete();
//将源文件的备份文件和源文件需要重命名的名字记录到HashMap里面,最后进行这部分文件的命名操作
tempFileMap.put(oldFileTemp, newFile);
return;
}
}
//如果目标文件不存在或者目标文件名与源文件名相同,就直接进行重命名的操作
if(oldFile.exists() && oldFile.isFile()){
if(oldFile.renameTo(newFile)){
System.out.println("重命名成功:" + oldFile.getAbsolutePath() + "==>" + newFile.getAbsolutePath());
return;
}
}
//重命名失败就将计数器减一,并且将命名的长度还原到原来的长度
System.out.println("====================================重命名失败:" + oldFile.getAbsolutePath() + "====================================");
counter--;
nameLength -= nameExpansion;
}
/**
* 重命名剩下的源文件的备份文件
* 参数:无
* 返回值:无
* */
private void renameTempFiles() {
Set<Entry<File, File>> entrySet = tempFileMap.entrySet();
for (Entry<File, File> entry : entrySet) {
//调用重命名的方法进行重命名
renameFile(entry.getKey(), entry.getValue());
}
}
public int getCounter() {
return counter;
}
public void setCounter(int counter) {
this.counter = counter;
}
public int getNameLength() {
return nameLength;
}
public void setNameLength(int nameLength) {
this.nameLength = nameLength;
}
}
由于counter(计数器)和nameLength(命名的长度)在进行排序和文件重命名的时候会频繁的使用到,因此我把他们放到了子类里面,避免多次调用父类的getter和setter方法。虽然我代码里面注释写得很清楚,但是还是有一些小伙伴不习惯看注释,那我稍微做一下解释,但是代码的逻辑还是要大家下来看一下!如果在博客上不太方便的话,可以直接copy到eclipse里面或者idea里面进行逻辑的分析!
(1)在主方法或其他方法需要调用到这个类型,可以直接利用该类的构造方法来调用到这个类:
public HashMapSortUtils(HashMap<File, Object> sortMap, Integer counter, Integer nameLength, String prefix){
......
}
这个构造方法会将需要进行排序和重命名的HashMap加载到该类的成员变量中,该类所有方法都可以调用该HashMap,并且计数器开始的位置(counter)、命名的长度(nameLength)、命名前缀(prefix)都加载到成员变量中,其中HashMap和前缀属于父类的变量。(相信大多数人都知道,我就乱解释一番了。。。)
(2)将传进来的HashMap进行排序的方法:
public LinkedHashMap<File, Object> sortFileMap() {
......
}
该方法就是利用java工具类Collections下面的sort方法进行排序,需要注意的是,最后之所以返回的是一个LinkedHashMap是因为HashMap是无序的,如果排完序还是用HashMap装排序的结果,那么就有可能没有达到排序预期的效果
(3)将排好序的HashMap中的文件重命名的方法:
public void renameFiles(LinkedHashMap<File, Object> linkedTimeMap) {
......
}
该方法主要分为两个步骤:a.利用createFileName方法将之前设置好的prefix(前缀)、nameLength(命名的长度)、counter(计数器)组成新的名字;b.将HashMap中所有的entry节点利用renameFile方法进行判断是否可以直接重命名,如果可以直接重命名就直接重命名,如果需要重新命名的文件已经存在就将源文件copy一份出来,然后将拷贝文件和新的名字方法一个HashMap中,等到程序的第c步才执行这部分文件的重命名!c.将之前未进行重命名的源文件进利用renameTempFiles方法行统一的重命名!
4.文件操作的工具类
文件操作是一个公共的类,进行文件的复制、删除、获取所有文件、创建文件夹等等,都可以写做一个公共的方法,大家可以自行去了解这个类的作用,这里不再过多的赘述(嘻嘻,又可以偷波懒了),不过我这里是错误的示范,我用接口的方式来实现的,真正的生产中是不会这样做的,因为文件操作是基本上不会变的,这里我只是想单纯的联系一下接口的操做,那么废话不多说,直接上代码,都是文件操作的基础代码:
文件操作的接口:
package readcolor;
import java.io.File;
import java.util.List;
public interface FileService {
void copyFile(String sourcePath, String targetPath) throws Exception;
void copyFile(File sourceFile, File targetFile) throws Exception;
void mkDirs(String path) throws Exception;
List<File> getAllFiles(String sourcePath);
void removeFiles(String path);
void removeFiles(File sourceFile);
}
文件操作的实现类:
package readcolor;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
public class FileServiceImpl implements FileService{
@Override
public void copyFile(String sourcePath, String targetPath) throws Exception {
copyFile(new File(sourcePath), new File(targetPath));
}
@Override
public void copyFile(File sourceFile, File targetFile) throws Exception {
FileInputStream fis = new FileInputStream(sourceFile);
FileOutputStream fos = new FileOutputStream(targetFile);
byte[] buffer = new byte[1024];
int len = 0;
while((len = fis.read(buffer)) != -1){
fos.write(buffer, 0, len);
fos.flush();
}
fos.close();
fis.close();
}
@Override
public void mkDirs(String path) throws Exception {
File destFile = new File(path);
if(!destFile.exists()){
destFile.mkdirs();
}
}
@Override
public List<File> getAllFiles(String sourcePath) {
ArrayList<File> files = new ArrayList<File>();
File file = new File(sourcePath);
if(file.exists() && !file.isHidden()){
if(file.isFile()){
files.add(file);
}
if(file.isDirectory()){
File[] fs = file.listFiles();
for (File f : fs) {
if(!f.isHidden()){
if(f.isFile()){
files.add(file);
}
if(f.isDirectory()){
files.addAll(getAllFiles(sourcePath + File.separator + f.getName()));
}
}
}
}
}
return files;
}
@Override
public void removeFiles(String path) {
removeFiles(new File(path));
}
@Override
public void removeFiles(File sourceFile) {
if (!sourceFile.isDirectory()){
if(sourceFile.delete()) System.out.println("删除文件:" + sourceFile.getAbsolutePath() + "成功");
}else{
File[] files = sourceFile.listFiles();
for (File file : files) {
if(file.isDirectory()){
removeFiles(file);
if(file.delete()) System.out.println("删除文件夹:" + file.getAbsolutePath() + "成功");
}else{
if(file.delete()) System.out.println("删除文件:" + file.getAbsolutePath() + "成功");
}
}
}
}
}
好的,一切准备就绪,那我们直接开始运行代码,看看效果如何:
先准备好图片:

然后设置好文件的路径:
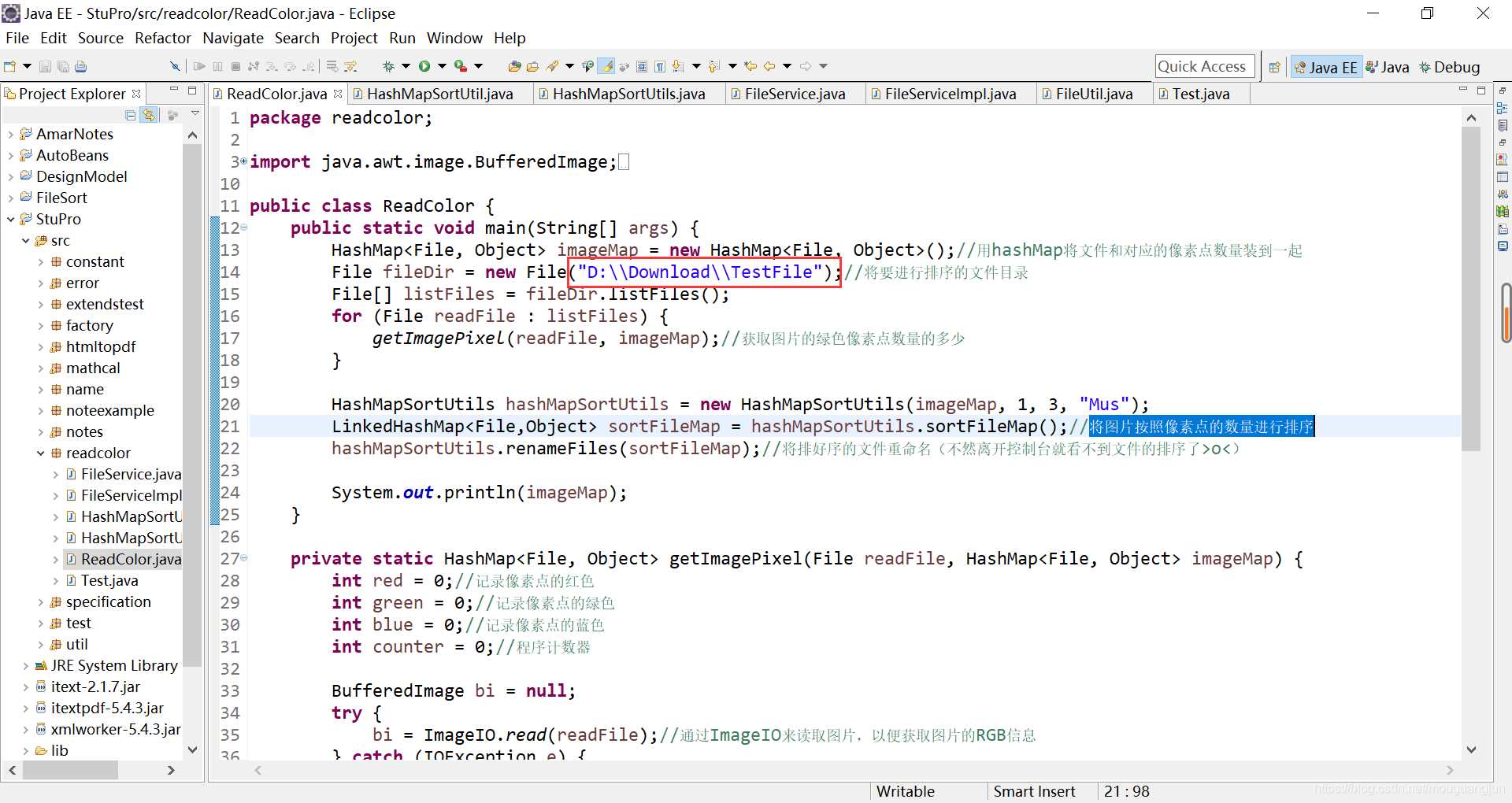
运行java程序:
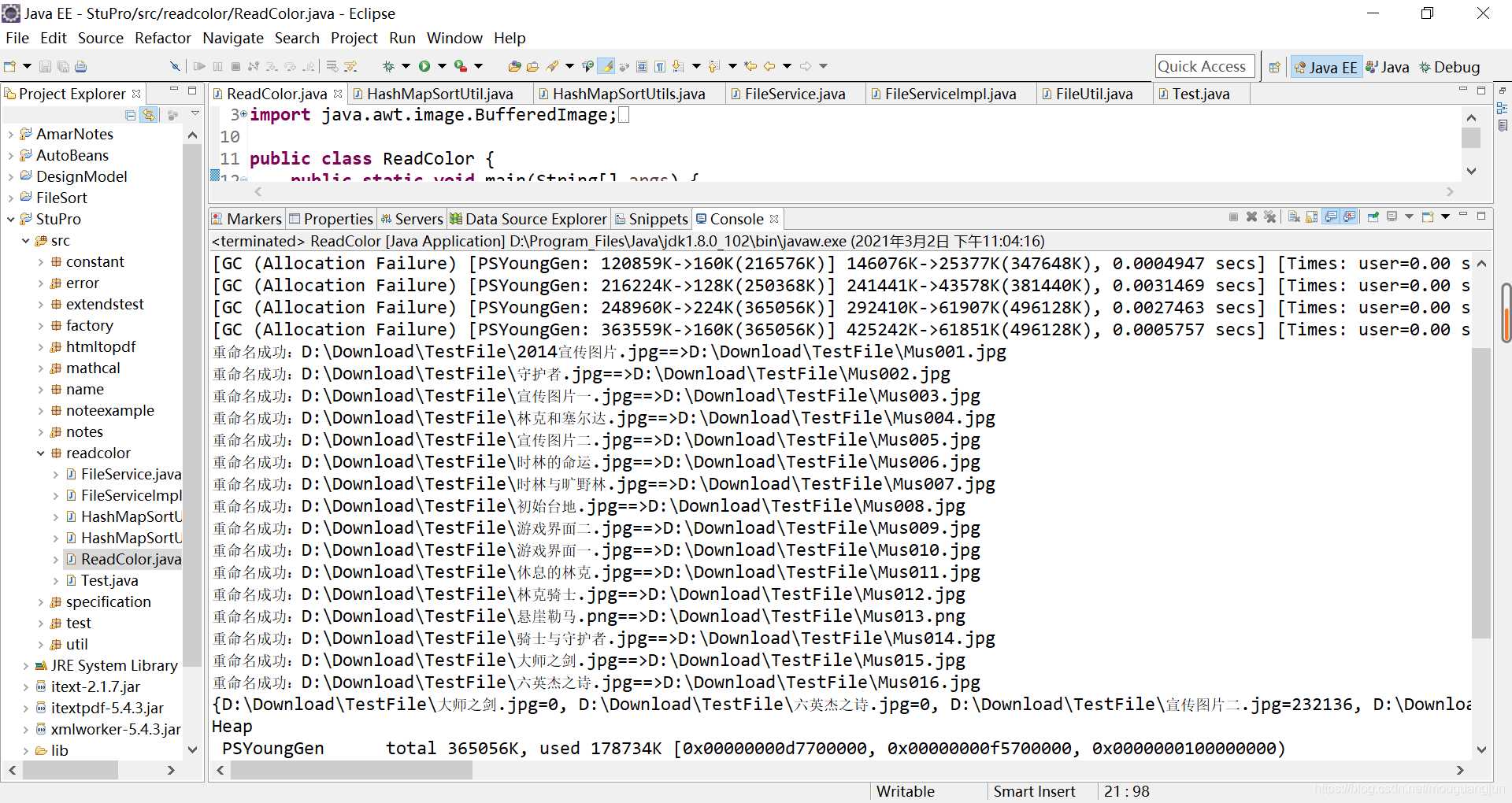
可以看到所有的文件都已经重新排序,并且已经进行重命名了,看看实际的效果:
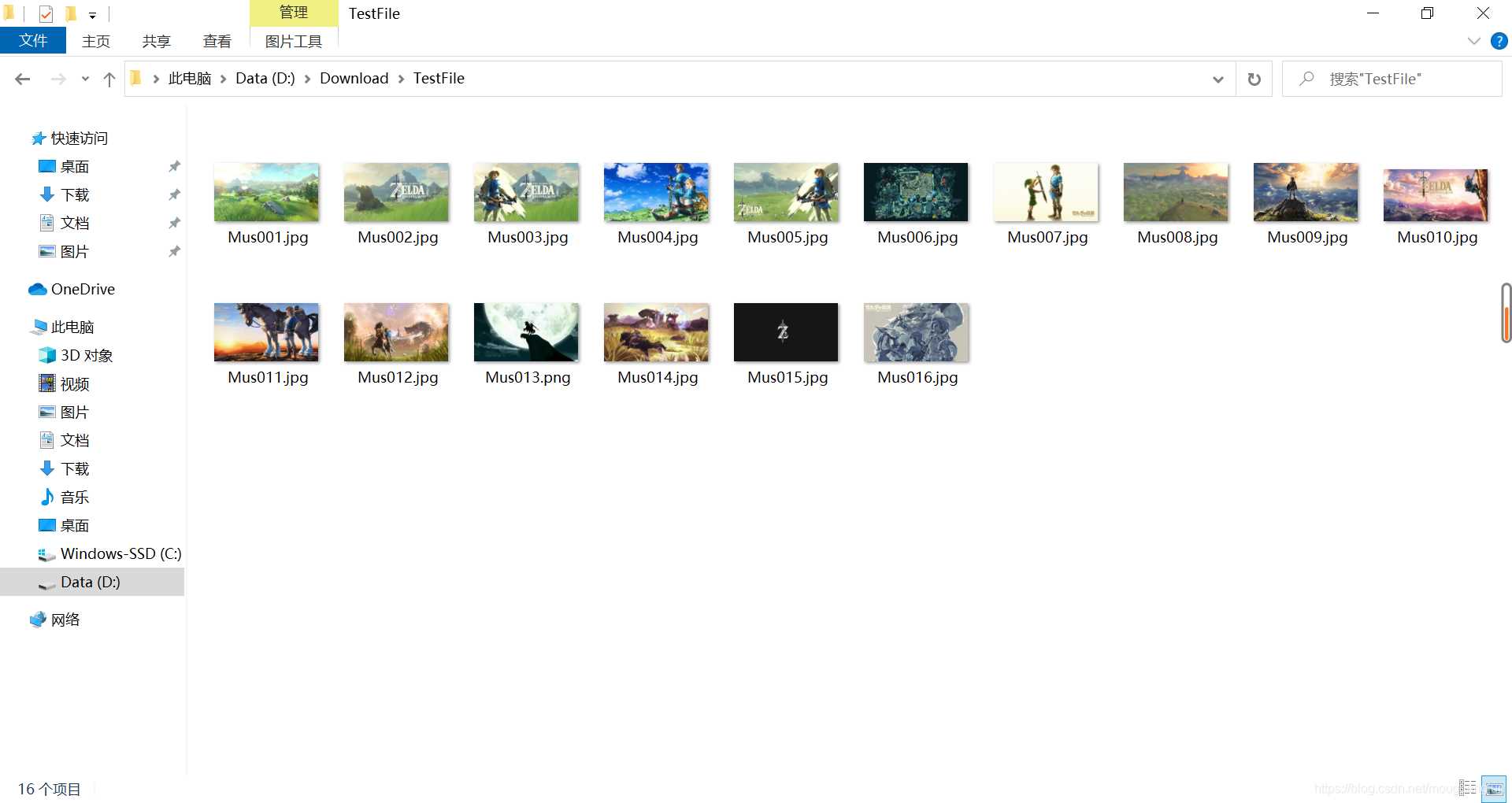
是不是感觉前面的图片要稍微绿一点呢?该程序可以进行重复执行的,暂时没有出现命名失败的情况,如果有小伙伴试了然后报错了,记得留言喔,我看看是啥问题,然后看看能不能再优化一下。。。(闻到了头发掉落的气息)
总结
最后,我们可以稍微改动几行代码,然后将所有的图片只输出绿色像素点来做一个直观的感受:
package readcolor;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.HashMap;
import java.util.LinkedHashMap;
import javax.imageio.ImageIO;
public class ReadColor {
private static int count = 0;
public static void main(String[] args) {
HashMap<File, Object> imageMap = new HashMap<File, Object>();//用hashMap将文件和对应的像素点数量装到一起
File fileDir = new File("D:\\Download\\TestFile");//将要进行排序的文件目录
File[] listFiles = fileDir.listFiles();
for (File readFile : listFiles) {
getImagePixel(readFile, imageMap);//获取图片的绿色像素点数量的多少
}
HashMapSortUtils hashMapSortUtils = new HashMapSortUtils(imageMap, 1, 3, "Mus");
LinkedHashMap<File,Object> sortFileMap = hashMapSortUtils.sortFileMap();//将图片按照像素点的数量进行排序
hashMapSortUtils.renameFiles(sortFileMap);//将排好序的文件重命名(不然离开控制台就看不到文件的排序了>o<)
System.out.println(imageMap);
}
private static HashMap<File, Object> getImagePixel(File readFile, HashMap<File, Object> imageMap) {
int red = 0;//记录像素点的红色
int green = 0;//记录像素点的绿色
int blue = 0;//记录像素点的蓝色
int counter = 0;//程序计数器
BufferedImage bi = null;
try {
bi = ImageIO.read(readFile);//通过ImageIO来读取图片,以便获取图片的RGB信息
} catch (IOException e) {
e.printStackTrace();
}
int width = bi.getWidth();//获取图片的宽度
int height = bi.getHeight();//获取图片的高度
int minx = bi.getMinX();//获取图片的坐标起点x轴
int miny = bi.getMinY();//获取图片的坐标起点y轴
for(int i = minx; i < width; i++){
for(int j = miny; j < height; j++){
int pixel = bi.getRGB(i, j);
red = (pixel & 0xff0000) >> 16;//过滤掉图片的绿色和蓝色
green = (pixel & 0xff00) >> 8;//过滤掉图片的绿色
blue = (pixel & 0xff);//最后剩下的就是蓝色啦
if(green - red > 30 && green - blue > 30){//绿色的范围
counter++;
}else{
bi.setRGB(i, j, 0xffffff);
}
}
}
imageMap.put(readFile, counter);//将文件和像素点的个数记录到HashMap中
try {
ImageIO.write(bi, "jpg", new File("D:\\Download\\TestFile1\\" + count +".jpg"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
count++;
return imageMap;
}
}
将图片的非绿色像素点修改为白色,然后存到一个新的文件夹里,看看是什么效果:

是不是只提取出了绿色像素点呢,大家在这个的基础上就可以选择自己喜欢的颜色进行排序了。反正我把这个程序送给我朋友的时候,遭到了他半个小时的感谢(问候),大家只是自己可以玩一玩,千万别去乱动别人的硬盘喔!(最后的最后,程序并没有什么实际的使用价值,只是学习了一些新的方法或者技巧,实际上我进行图像处理的时候都是直接选用photoshop进行操作的,哈哈啊哈哈!)
加载全部内容