Java WebMagic爬取 Java基于WebMagic爬取某豆瓣电影评论的实现
Victor.Chang 人气:0想了解Java基于WebMagic爬取某豆瓣电影评论的实现的相关内容吗,Victor.Chang在本文为您仔细讲解Java WebMagic爬取的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Java,WebMagic爬取,WebMagic爬取豆瓣,下面大家一起来学习吧。
目的
搭建爬虫平台,爬取某豆瓣电影的评论信息。
准备
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。
下载WebMagic源码,或Maven导入,或Jar包方式导入。 码云地址:https://gitee.com/flashsword20/webmagic
试运行
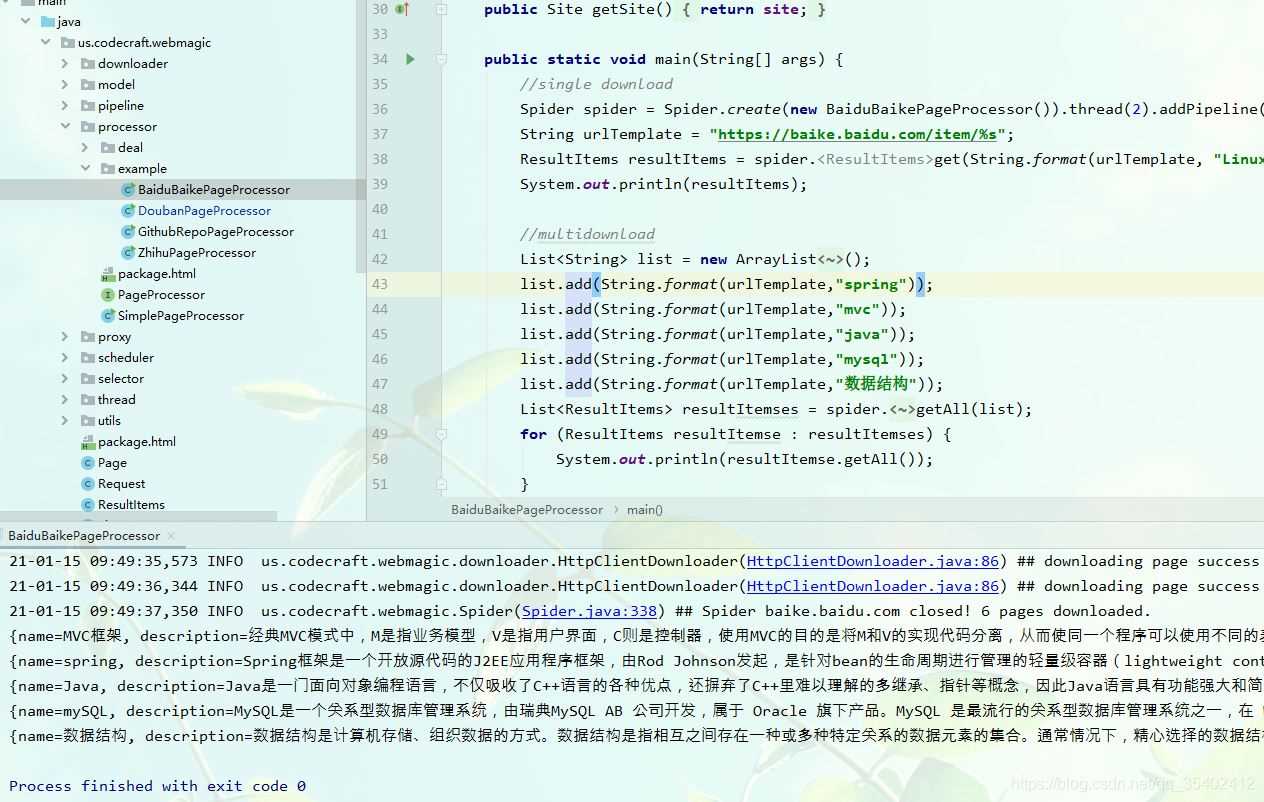
搭建好后打开项目, 在 us.codecraft.webmagic.processor.example 包下有几个可运行的例子,我们可以直接运行体验(BaiduBaikePageProcessor 百度百科的这个比较稳定)。
爬到结果说明没问题。
自定义爬虫
接下来我们自己编写一个爬取豆瓣评论的爬虫。
爬取地址:https://movie.douban.com/subject/35096844/reviews?start=0
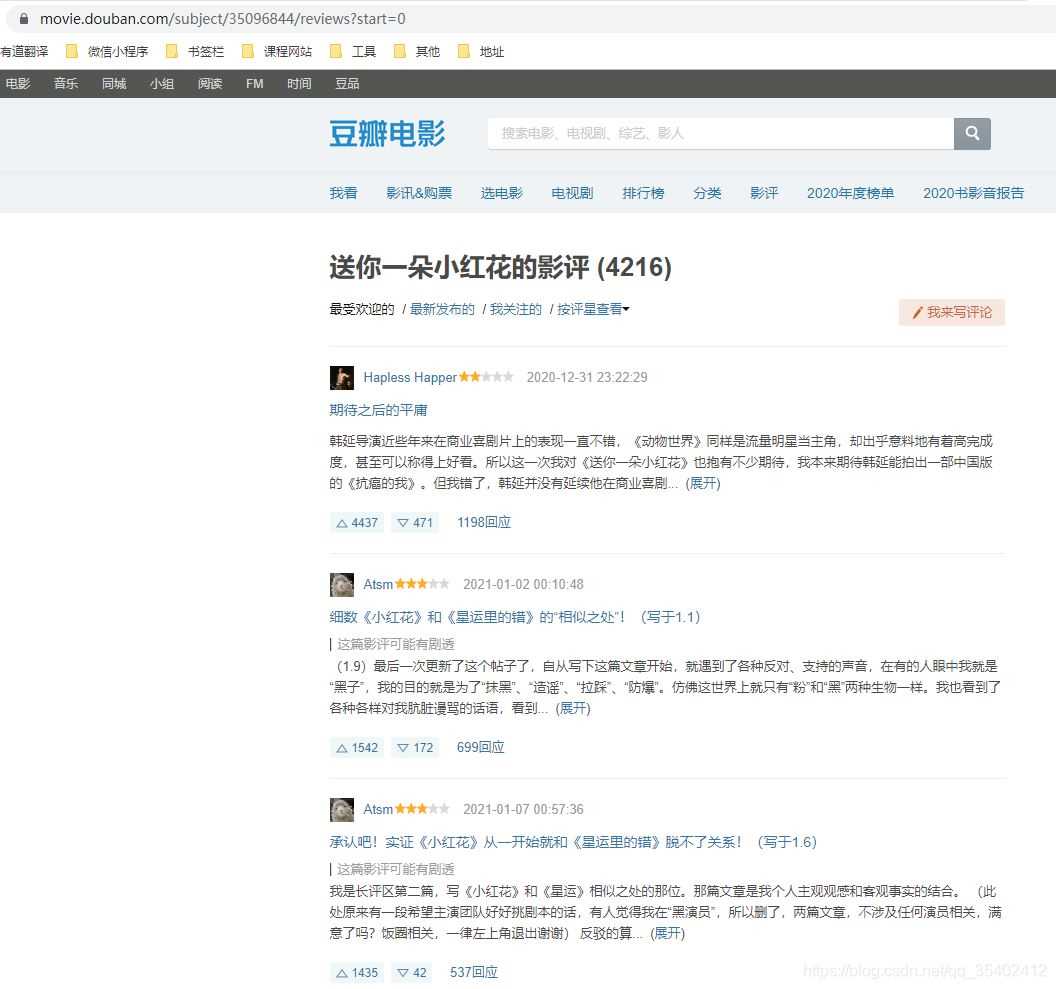
F12进入开发者模式 分析前端页面
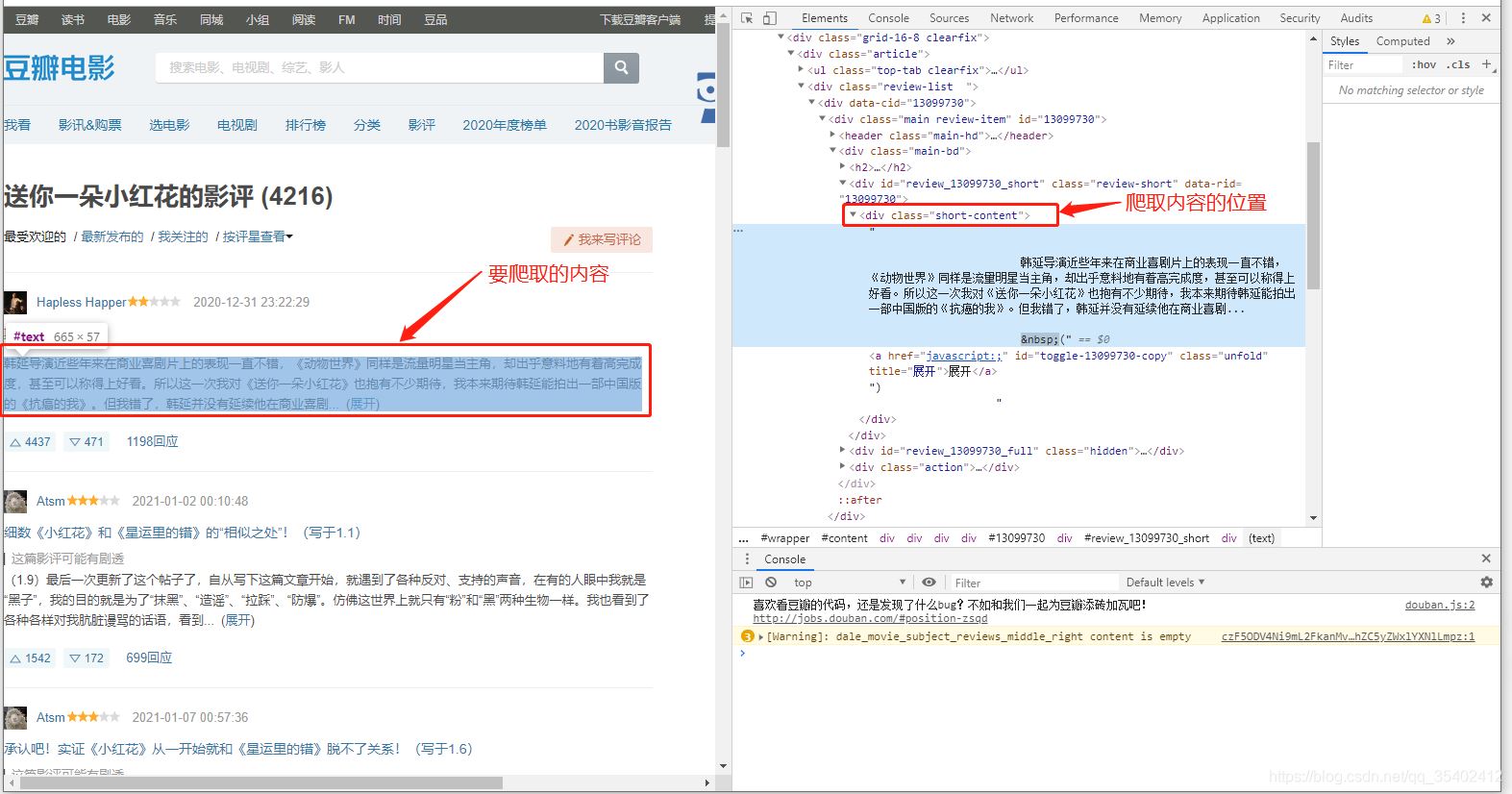
我们发现我们需要爬取的评论信息存放在 class=short-content的div 中。
创建一个豆瓣爬取的类DoubanPageProcessor如下:
package us.codecraft.webmagic.processor.example;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
import java.util.Map;
/**
* A simple PageProcessor.
* 爬取豆瓣某电影的评论 爬取地址:https://movie.douban.com/subject/35096844/reviews?start=0
*
* @author code4crafter@gmail.com <br>
* @since 0.1.0
*/
public class DoubanPageProcessor implements PageProcessor {
private Site site;
public DoubanPageProcessor(String urlPattern) {
this.site = Site.me().setRetryTimes(3).setSleepTime(300); // 设置站点重试次数3 间隔300ms
}
@Override
public void process(Page page) {
page.putField("title", page.getHtml().xpath("//title/text()")); //爬取网页标题
// page.putField("html", page.getHtml().toString()); //爬取整个页面的html
page.putField("titleList", page.getHtml().css("div.short-content", "text").all()); // 我们要爬取的核心信息内容,获取方式与css选择器用法一样
// page.putField("content", page.getHtml().smartContent());
}
@Override
public Site getSite() {
//settings
return site;
}
public static void main(String[] args) {
Spider spider = Spider.create(new DoubanPageProcessor("https://movie\\.douban\\.com\\d+"));
ResultItems resultItems = spider.<ResultItems>get("https://movie.douban.com/subject/35096844/reviews?start=0");// 爬取并获得爬取结果
Map<String, Object> map = resultItems.getAll();
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue()); //打印爬取的所有内容
}
List<String> shortList = (List<String>) map.get("titleList");
System.out.println("=====================分隔线===================\n短评如下:");
for (int i = 0; i < shortList.size(); i++) {
System.out.println(i + "、" + shortList.get(i).trim()); // 打印爬取的评论内容
}
spider.close();
}
}
运行结果如下:

爬取成功。
加载全部内容