tensorflow-cpu神经网络 用gpu训练好的神经网络,用tensorflow-cpu跑出错的原因及解决方案
wander_ing 人气:1训练的时候当然用gpu,速度快呀。
我想用cpu版的tensorflow跑一下,结果报错,这个错误不太容易看懂。

大概意思是没找到一些节点。
后来发现原因,用gpu和cpu保存的pb模型不太一样,但是checkpoints文件是通用的。
使用tensorflow-cpu再把checkpoints文件重新转换一下pb文件就可以了。
完美解决!
补充:tensflow-gpu版的无数坑坑坑!(tf坑大总结)
自己的小本本,之前预装有的pycharm+win10+anaconda3+python3的环境
2019/3/24重新安装发现:目前CUDA10.1安装不了tensorflow1.13,把CUDA改为10.0即可(记得对应的cudann呀)
如果刚入坑,建议先用tensorflw学会先跑几个demo,等什么时候接受不了cpu这乌龟般的速度之时,就要开始尝试让gpu来跑了。
cpu跑tensorflow只需要在anaconda3下载。
安装cpu跑的tensorflow:
我的小本本目前已经是gpu版本,cpu版本下红圈里那个版本就好了!

安装好了后直接在python命令中输入
import tensorflow as tf
如果不报错说明调用成功。
查看目前tensorflow调用的是cpu还是gpu运行:
import tensorflow as tf import numpy as np a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') c = tf.matmul(a, b) sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) print(sess.run(c))
然后把这段代码粘贴到编译器中运行,
看一下运行的结果中,调用运行的是什么

看给出的是gpu还是cpu就能判断目前运行的是哪一个了
安装gpu版本的tensorflow:
首先第一步要确定你的显卡是否为N卡,
然后上https://developer.nvidia.com/cuda-gpus去看看你的显卡是否被NVDIA允许跑机器学习

对于CUDA与cudann的安装:
需要到nvdia下载CUDA与cudann,这里最重要的是注意CUDA与cudann与tensorflow三者的搭配,
注意版本的搭配!!!
注意版本的搭配!!!
注意版本的搭配!!!
tensorflow在1.5版本以后才支持9.0以上的CUDA,所以如果CUDA版本过高,会造成找不到文件的错误。
在官网也可以看到CUDA搭配的cudann

在安装完了cudann时,需要把其三个文件复制到CUDA的目录下,并且添加3个新的path:
3个path,

当使用gpu版的tf时,就不再需要安装原来版本的tf,卸载了就好,安装tf-gpu版,
判断自己是否有安装tf包,对于pycharm用户,可以在setting那看看是否安装了tf-gpu
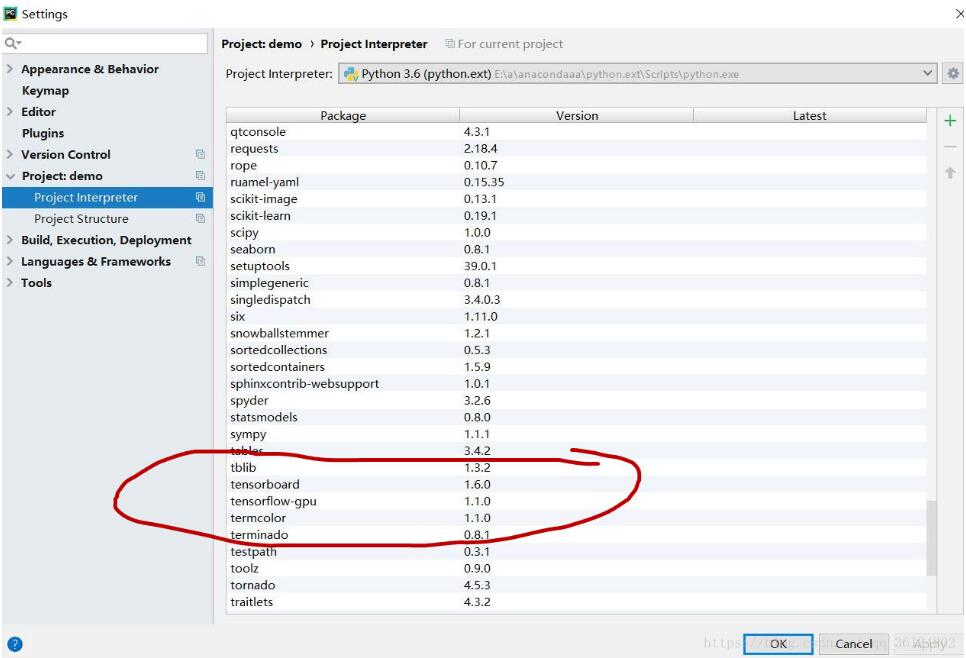
我使用的环境为:tf1.2+CUDA8.0+cudann5.1
当全部正确安装时
import tensorflow as tf 仍然出错
cudnn64_6.dll问题
关于导入TensorFlow找不到cudnn64_6.dll,其实下载的的是cudnn64_7.dll(版本不符合),把其修改过来就行了。
目录是在:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin下
对于不断尝试扔失败运行GPU版本,可以把tf先删除了重新下
import tensorflow as tf print(tf.__version__)
查询tensorflow安装路径为:
print(tf.__path__)
成功用GPU运行但运行自己的代码仍然报错:
如果报错原因是这个
ResourceExhaustedError (see above for traceback): OOM when allocating tensor with shape[10000,28,28,32]
最后关于这个报错是因为GPU的显存不够,此时你可以看看你的代码,是训练集加载过多还是测试集加载过多,将它一次只加载一部分即可。
对于训练集banch_xs,banch_ys = mnist.train.next_batch(1000) 改为
banch_xs,banch_ys = mnist.train.next_batch(100)即可,
而测试集呢print(compute_accuracy(mnist.test.images[:5000], mnist.test.labels[:5000])) 改为
print(compute_accuracy(mnist.test.images, mnist.test.labels))即可
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
加载全部内容