如何实现延迟队列
rickiyang 人气:2延迟队列的需求各位应该在日常开发的场景中经常碰到。比如:
用户登录之后5分钟给用户做分类推送;
用户多少天未登录给用户做召回推送;
定期检查用户当前退款账单是否被商家处理等等场景。
一般这种场景和定时任务还是有很大的区别,定时任务是你知道任务多久该跑一次或者什么时候只跑一次,这个时间是确定的。延迟队列是当某个事件发生的时候需要延迟多久触发配套事件,引子事件发生的时间不是固定的。
业界目前也有很多实现方案,单机版的方案就不说了,现在也没有哪个公司还是单机版的服务,今天我们一一探讨各种方案的大致实现。
1. Redis zset
这个方案比较常用,简单有效。利用 Redis 的 sorted set 结构,使用 timeStamp 作为 score,比如你的任务是要延迟5分钟,那么就在当前时间上加5分钟作为 score ,轮询任务每秒只轮询 score 大于当前时间的 key即可,如果任务支持有误差,那么当没有扫描到有效数据的时候可以休眠对应时间再继续轮询。
方案优劣:
优点:
简单实用,一针见血。
缺点:
- 单个 zset 肯定支持不了太大的数据量,如果你有几百万的延迟任务需求,大哥我还是劝你换一个方案;
- 定时器轮询方案可能会有异常终止的情况需要自己处理,同时消息处理失败的回滚方案,您也要自己处理。
所以,sorted set 的方案并不是一个成熟的方案,他只是一个快速可供落地的方案。
2. RabbitMQ队列
下面说一个可以落地的方案,这个方案也被大多数目前在架构中使用了 RabbitMQ 的项目组使用。不好的一点就是,捆绑 RabbitMQ,当你的架构方案是要用别的 MQ 替换 RabbitMQ 的时候,你就蛋疼了(我现在正在经历)。
RabbitMQ 有两个特性,一个是 Time-To-Live Extensions,另一个是 Dead Letter Exchanges。
Time-To-Live Extensions
RabbitMQ允许我们为消息或者队列设置TTL(time to live),也就是过期时间。TTL表明了一条消息可在队列中存活的最大时间,单位为毫秒。也就是说,当某条消息被设置了TTL或者当某条消息进入了设置了TTL的队列时,这条消息会在经过TTL秒后 “死亡”,成为Dead Letter。如果既配置了消息的TTL,又配置了队列的TTL,那么较小的那个值会被取用。
Dead Letter Exchanges
在 RabbitMQ 中,一共有三种消息的 “死亡” 形式:
- 消息被拒绝。通过调用
basic.reject或者basic.nack并且设置的requeue参数为 false; - 消息因为设置了TTL而过期;
- 队列达到最大长度。
- 消息被拒绝。通过调用
DLX同一般的 Exchange 没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。当队列中有 DLX 消息时,RabbitMQ就会自动的将 DLX 消息重新发布到设置的 Exchange 中去,进而被路由到另一个队列,publish 可以监听这个队列中消息做相应的处理。
由上简介大家可以看出,RabbitMQ本身是不支持延迟队列的,只是他的特性让勤劳的 中国脱发群体 急中生智(为了完成任务)弄出了这么一套可用的方案。
可用的方案就是:
- 如果有事件需要延迟那么将该事件发送到MQ 队列中,为需要延迟的消息设置一个TTL;
- TTL到期后就会自动进入设置好的DLX,然后由DLX转发到配置好的实际消费队列;
- 消费该队列的延迟消息,处理事件。
方案优劣:
优点:
大品牌组件,用的放心。如果面临大数据量需求可以很容易的横向扩展,同时消息支持持久化,有问题可回滚。
缺点:
- 配置麻烦,额外增加一个死信交换机和一个死信队列的配置;
- RabbitMQ 是一个消息中间件,TTL 和 DLX 只是他的一个特性,将延迟队列绑定在一个功能软件的某一个特性上,可能会有风险。不要杠,当你们组不用 RabbitMQ 的时候迁移很痛苦;
- 消息队列具有先进先出的特点,如果第一个进入队列的消息 A 的延迟是10分钟,第二个进入队列的消息B 的延迟是5分钟,期望的是谁先到 TTL谁先出,但是事实是B已经到期了,而还要等到 A 的延迟10分钟结束A先出之后,B 才能出。所以在设计的时候需要考虑不同延迟的消息要放到不同的队列。另外该问题官方已经给出了插件来支持:插件地址。
3. 基于 Netty#HashedWheelTimer类方法的实现
HashedWheelTimer 是 Netty 中 的一个基础工具类,主要用来高效处理大量定时任务,且任务对时间精度要求相对不高, 在Netty 中的应用场景就是连接超时或者任务处理超时,一般都是操作比较快速的任务,缺点是内存占用相对较高。
算法思想
HashedWheelTimer 主要还是一个 DelayQueue 和一个时间轮算法组合。
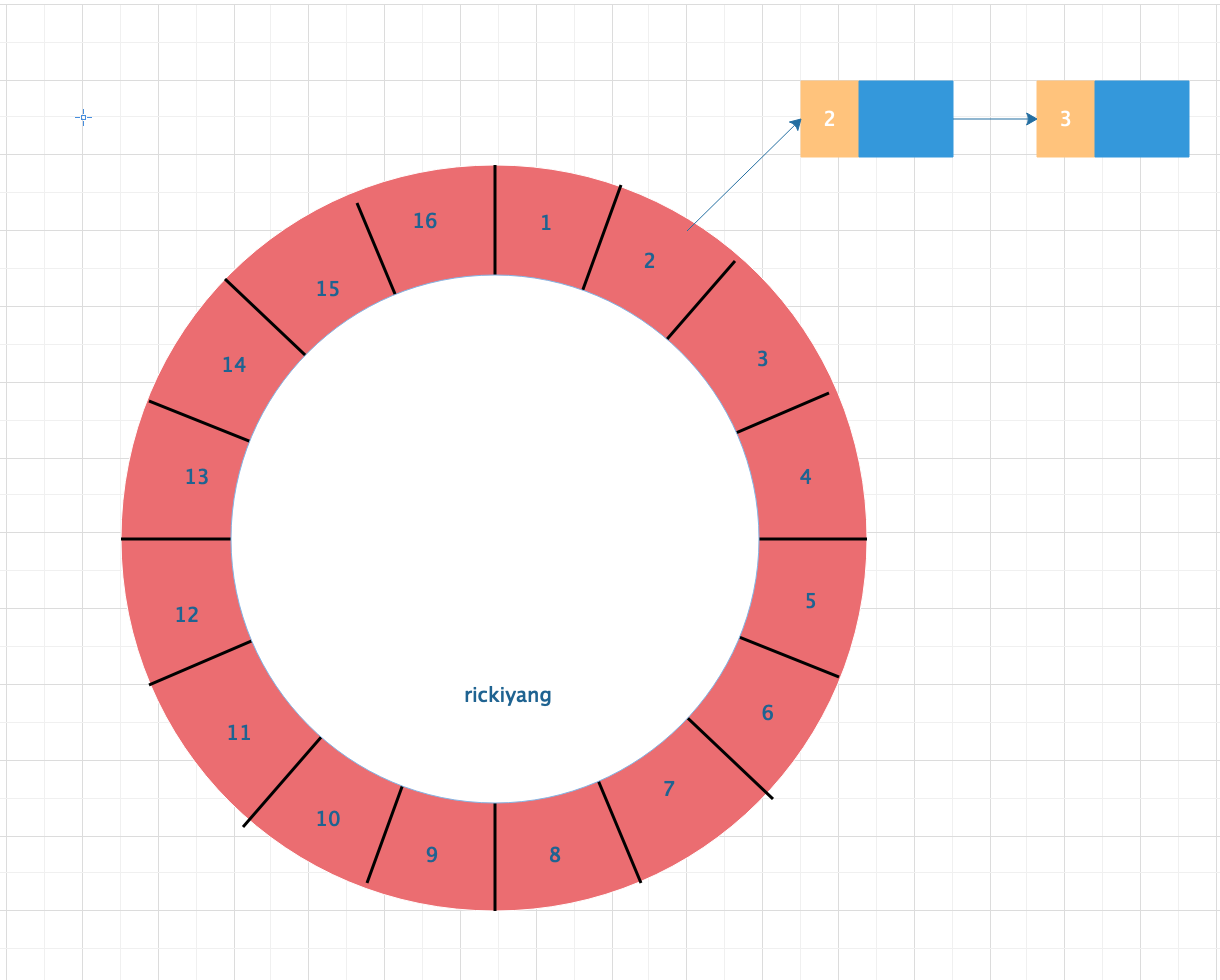
Hash Wheel Timer是一个环形结构,可以想象成时钟,分为很多格子,一个格子代表一段时间(越短Timer精度越高),并用一个List保存在该格子上到期的所有任务。同时一个指针随着时间流逝一格一格转动,并执行对应List中所有到期的任务。
以上图为例,假设一个格子是1s,则整个时间轮能表示的时间段16s。当前任务指向格子2,表明在第2s的时候有任务需要执行。任务列表中有两个任务,每个任务前面的数字表示圈数。2表示当走到第2圈的时候才会执行,那么整个任务的真正执行时间其实是在12s之后执行,即第二圈走到2的时候。每推进一格,对应的每一个 slot 中的round数都要减一。整体算法就是这么个逻辑。
时间轮设计要点:
- tick,一次时间推进,每次推进会检查/执行超时任务;
- tickDuration,时间轮推进的最小单元,每隔 tickDuration 会有一次 tick,它决定了时间轮的精确程度;
- ucket(ticksPerWheel),上图中的每一隔就是一个bucket,表示一个时间轮可以有多少个tick,它是存储任务的最小单元;
- 上层时间轮的 tickDuration 是下层时间轮的表示时间的最大范围,即:父 tickDuration = 子 tickDuration * 子 bucket 。
需要注意的是,这种方式任务是串行执行的。意味着你如果在时间轮中执行任务且任务耗时较长,将会出现调度超时或者任务堆积的情况。所以要将任务的执行异步化。
算法的要点:
- 任务并不是直接放在格子中的,而是维护了一个双向链表,这种数据结构非常便于插入和移除;
- 新添加的任务并不直接放入格子,而是先放入一个队列中,这是为了避免多线程插入任务的冲突。在每个tick运行任务之前由worker线程自动对任务进行归集和分类,插入到对应的槽位里面。
Netty 使用数组 + 双向链表的方式来组织时间轮,对于添加/取消操作仅做了记录,真正的操作实际发生在下一个tick。时间的推进是独立的线程在做,该线程同时也负责过期任务的执行等操作,可简单认为此步骤操作为O(n),因为推进线程需要完全遍历timeouts、cancelledTimeouts与bucket链表,在遍历timeouts时,Netty为了避免任务过多,所以限制每次最多遍历10万个,也就是说,一个tick只能规划10万个任务,当任务量过大时,会存在超时任务执行时间延迟的现象。
方案优劣:
优点:
实现比较优雅。效率高。
缺点:
- 无法实现HA和横向扩展,要么就使用多个时间轮。
- 最重要的是,实现也比较复杂,开发者需要考虑所有可能的情况。
目前我了解到的延迟队列在生产环境下有如上三种实现方式,每一种都有人在使用。当然没有最好的只有最适合的,你觉得 redis 能满足需求,就按照最简单的来,你要是有充足的开发周期,你也可以实现时间轮展现实力。
需求千万种,变化就一种:给时间都能做。
加载全部内容