MVCC多版本并发控制器
酸萝卜别吃 人气:0在多个事务并发执行的时候,MVCC机制可以协调数据的可见性,事务的隔离级别就是建立在MVCC之上的;
MVCC机制通过undo log链和ReadView机制来实现;
undo log版本链:
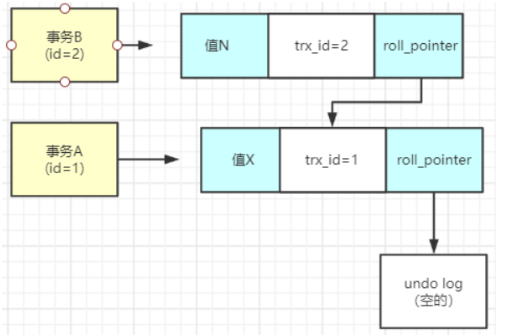
在数据库的每行记录中,都有两个隐藏字段,trx_id和roll_pointer,trx_id就是最近一次更新这个记录的事务id,roll_pointer就是指向这个事务生成之前的那个事务的undo_log回滚日志;
比如,当前事务A插入了一条新记录,这个记录的trx_id就是事务A的id,roll_pointer指向的就是一个空的undo log;
然后,来了一个事务B,事务B更新了这条记录,那么这个记录的trx_id就是事务B的id,roll_pointer指向的就是之前那个事务的undo log;
这样,多个事务更新这个记录的时候,每次都会更新trx_id的值,并形成一个undo_log版本链;
ReadView机制:
当执行一个事务的时候,就会生成一个ReadView,里面存放了四条数据:
m_ids:记录的是此时正在执行的事务id
min_trx_id:记录的是m_ids中的最小的事务id
max_trx_id:记录的是m_ids中的最大的事务id+1,就是下一个会生成的事务id
creator_trx_id:记录的是本事务的id
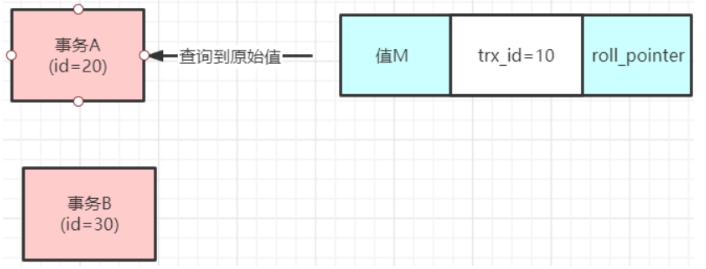
比如,此时有一条记录,trx_id是10;这时候生成了事务A(id=20)想要读数据,事务B(id=30)想要写数据,那么事务A生成的ReadView中,m_ids就是[20,30],min_trx_id=20,max_trx_id=31,creator_trx_id=20;
此时,事务A去查询这条记录,发现trx_id=10,小于自己的min_trx_id,这就说明这个数据在事务A生成之前就被更新过了,可以放心读;
然后,事务B去更新了这个记录,这个记录的trx_id就会变为30,然后事务A再去查询,发现trx_id=30,在自己的min_trx_id和max_trx_id之间,这就说明这个记录被一个和自己在差不多时间执行的事务修改过,然后再去查看这个trx_id=30在不在自己的m_ids中,发现在里面,说明修改这个数据的事务是和自己并发执行的,所以,这个数据就是不能读的,只能读到roll_pointer链上的上一次trx_id=10的数据;
通过ReadView和undo_log日志链,就可以保证事务A不会读到并发执行的事务B修改的数据;
假设,然后事务A又自己去更新了这条数据,那么再查询,记录的trx_id就会是20,和自己的creator_trx_id一样,也就是说是自己改的,当然是可以读的;
假设,又来了一个事务C(id=40),去更新这个记录,那么事务A再次查询,发现trx_id=40,比自己的max_trx_id大,那就说明数据被一个新的事务修改了,当然也不能读,只能顺着undo log链往前读数据;
通过ReadView机制和undo_log日志链,就可以判断当前记录的哪个版本是我们可以读的。
RC隔离级别如何基于ReadView机制实现:
读提交隔离级别,在每次查询的时候,都会生成一个新的ReadView;
当事务A查询一个记录的时候,产生一个新的ReadView,如果这个记录的trx_id在自己的min_trx_id和max_trx_id之间,并且在自己的m_ids里,那说明这个记录被一个还没提交的事务修改了,当然不可读;
如果事务B提交了修改,那么事务B就不会出现在事务A的ReadView,当然就可以读了;
RR隔离级别如何基于ReadView机制实现:
在可重复读级别下,会在事务中的第一次查询的时候,生成一个ReadView,之后事务里的查询都用这个ReadView,但是可以自己更新;
当事务A查询一个记录的时候,产生一个ReadView,此时读到第一次数据,如果这时候事务B修改了数据,那么记录的trx_id就会更新,这时候事务A再查询数据,用的还是第一次的ReadView,所以即使事务B已经提交了,事务A读到trx_id的时候,这个trx_id肯定是要么大于max_trx_id,要么还在m_ids里,所以不会读这个数据,会顺着undo_log链去找之前的数据,因此读到的还是第一次数据,实现可重复读;
当然,如果是事务A自己修改了数据,是可以读到的;
加载全部内容