Spring 的循环依赖,源码详细分析 → 真的非要三级缓存吗
青石路 人气:0开心一刻
吃完晚饭,坐在院子里和父亲聊天
父亲:你有什么人生追求?
我:金钱和美女
父亲对着我的头就是一丁弓,说道:小小年纪,怎么这么庸俗,重说一次
我:事业与爱情
父亲赞赏的摸了我的头,说道:嗯嗯,这就对咯

写作背景
做 Java 开发的,一般都绕不开 Spring,那么面试中肯定会被问到 Spring 的相关内容,而循环依赖又是 Spring 中的高频面试题
这不前段时间,我的一朋友去面试,就被问到了循环依赖,结果他还在上面还小磕了一下,他们聊天过程如下
面试官:说下什么是循环依赖
朋友: 两个或则两个以上的对象互相依赖对方,最终形成 闭环 。例如 A 对象依赖 B 对象,B 对象也依赖 A 对象

面试官:那会有什么问题呢
朋友:对象的创建过程会产生死循环,类似如下
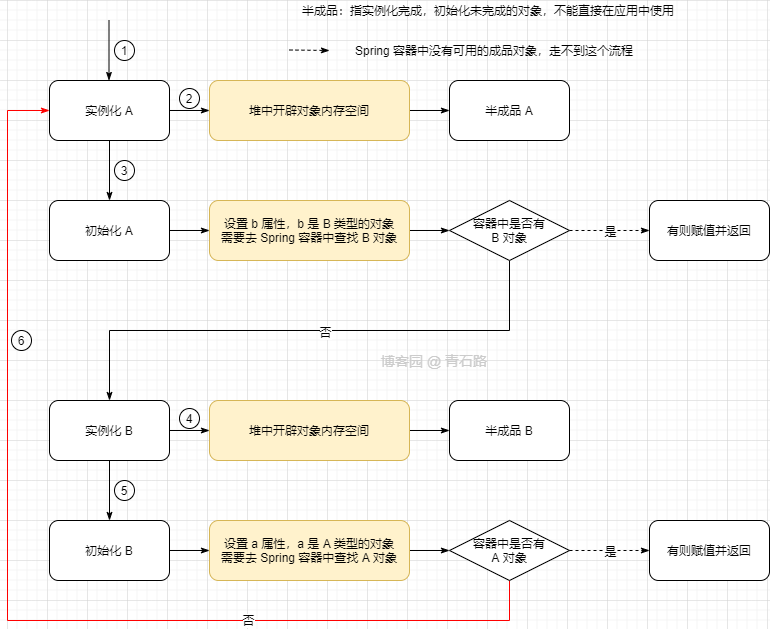
面试官:Spring 是如何解决的呢
朋友:通过三级缓存提前暴露对象来解决的
面试官:三级缓存里面分别存的什么
朋友:一级缓存里存的是成品对象,实例化和初始化都完成了,我们的应用中使用的对象就是一级缓存中的
二级缓存中存的是半成品,用来解决对象创建过程中的循环依赖问题
三级缓存中存的是 ObjectFactory<?> 类型的 lambda 表达式,用于处理存在 AOP 时的循环依赖问题

面试官:为什么要用三级缓存来解决循环依赖问题(只用一级缓存行不行,只用二级缓存行不行)
朋友:霸点蛮,只用一级缓存也是可以解决的,但是会复杂化整个逻辑
半成品对象是没法直接使用的(存在 NPE 问题),所以 Spring 需要保证在启动的过程中,所有中间产生的半成品对象最终都会变成成品对象
如果将半成品对象和成品对象都混在一级缓存中,那么为了区分他们,势必会增加一些而外的标记和逻辑处理,这就会导致对象的创建过程变得复杂化了
将半成品对象与成品对象分开存放,两级缓存各司其职,能够简化对象的创建过程,更简单、直观
如果 Spring 不引入 AOP,那么两级缓存就够了,但是作为 Spring 的核心之一,AOP 怎能少得了呢
所以为了处理 AOP 时的循环依赖,Spring 引入第三级缓存来处理循环依赖时的代理对象的创建
面试官:如果将代理对象的创建过程提前,紧随于实例化之后,而在初始化之前,那是不是就可以只用两级缓存了?
朋友心想:这到了我知识盲区了呀,我干哦! 却点头道:你说的有道理耶,我没有细想这一点,回头我去改改源码试试看
前面几问,感觉朋友答的还不错,但是最后一问中的第三级缓存的作用,回答的还差那么一丢丢,到底那一丢丢是什么,我们慢慢往下看
写在前面
正式开讲之前,我们先来回顾一些内容,不然可能后面的内容看起来有点蒙(其实主要是怕你们杠我)

对象的创建
一般而言,对象的创建分成两步:实例化、初始化,实例化指的是从堆中申请内存空间,完成 JVM 层面的对象创建,初始化指的是给属性值赋值
当然也可以直接通过构造方法一步完成实例化与初始化,实现对象的创建
当然还要其他的方式,比如工厂等
Spring 的的注入方式
有三种:构造方法注入、setter 方法注入、接口注入
接口注入的方式太灵活,易用性比较差,所以并未广泛应用起来,大家知道有这么一说就好,不要去细扣了
构造方法注入的方式,将实例化与初始化并在一起完成,能够快速创建一个可直接使用的对象,但它没法处理循环依赖的问题,了解就好
setter 方法注入的方式,是在对象实例化完成之后,再通过反射调用对象的 setter 方法完成属性的赋值,能够处理循环依赖的问题,是后文的基石,必须要熟悉
Spring 三级缓存的顺序
三级缓存的顺序是由查询循序而来,与在类中的定义顺序无关

所以第一级缓存: singletonObjects ,第二级缓存: earlySingletonObjects ,第三级缓存: singletonFactories
解决思路
抛开 Spring,让我们自己来实现,会如何处理循环依赖问题呢
半成品虽然不能直接在应用中使用,但是在对象的创建过程中还是可以使用的嘛,就像这样

有入栈,有出栈,而不是一直入栈,也就解决了循环依赖的死循环问题
Spring 是不是也是这样实现的了,基于 5.2.12.RELEASE ,我们一起来看看 Spring 是如何解决循环依赖的
Spring 源码分析
下面会从几种不同的情况来进行源码跟踪,如果中途有疑问,先用笔记下来,全部看完了之后还有疑问,那就请评论区留言
没有依赖,有 AOP
代码非常简单:spring-no-dependence
此时, SimpleBean 对象在 Spring 中是如何创建的呢,我们一起来跟下源码

接下来,我们从 DefaultListableBeanFactory 的 preInstantiateSingletons 方法开始 debug

没有跟进去的方法,或者快速跳过的,我们可以先略过,重点关注跟进去了的方法和停留了的代码,此时有几个属性值中的内容值得我们留意下

我们接着从 createBean 往下跟

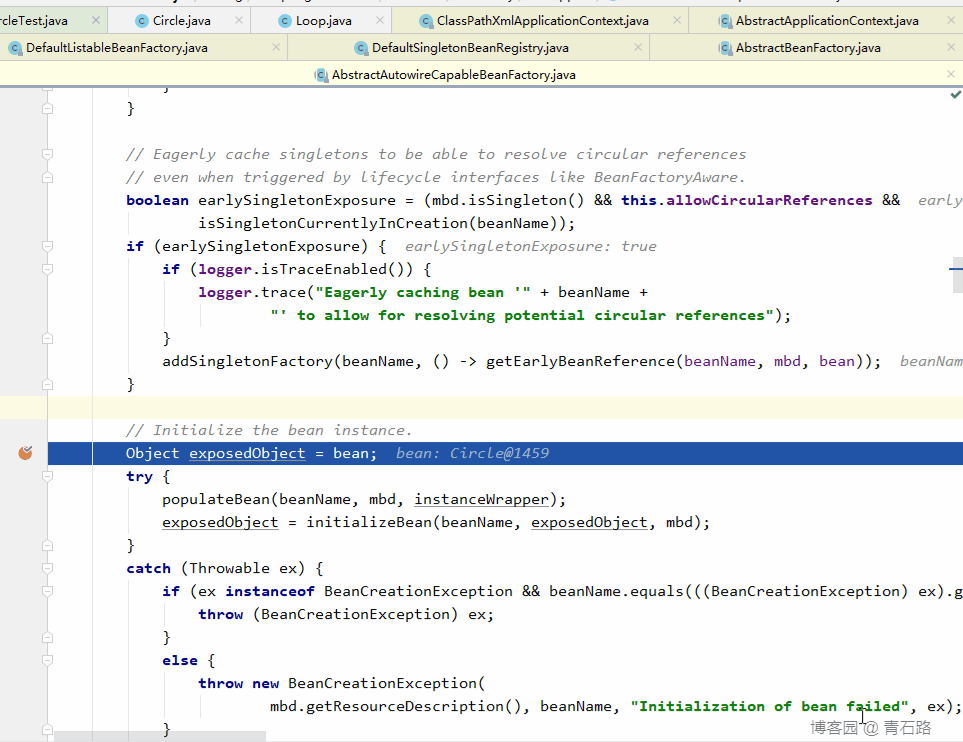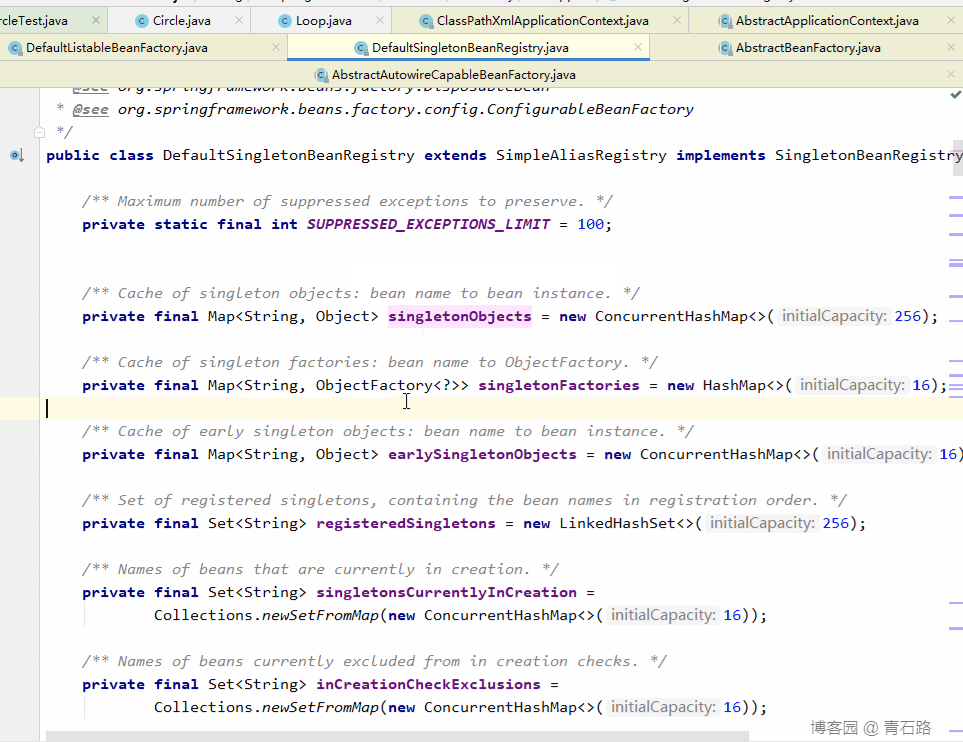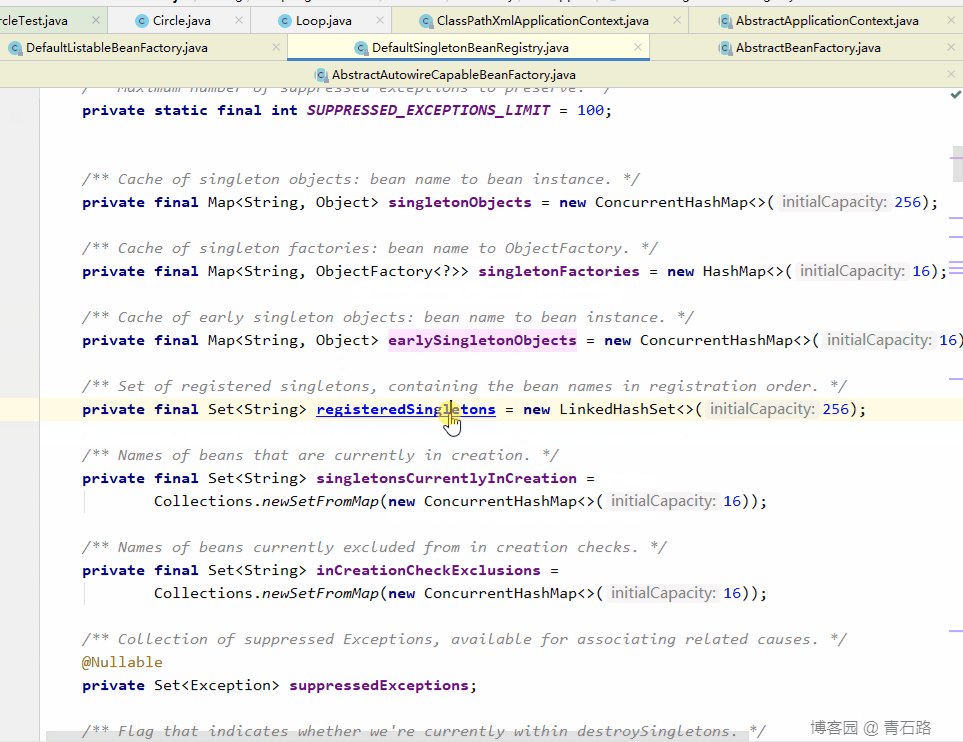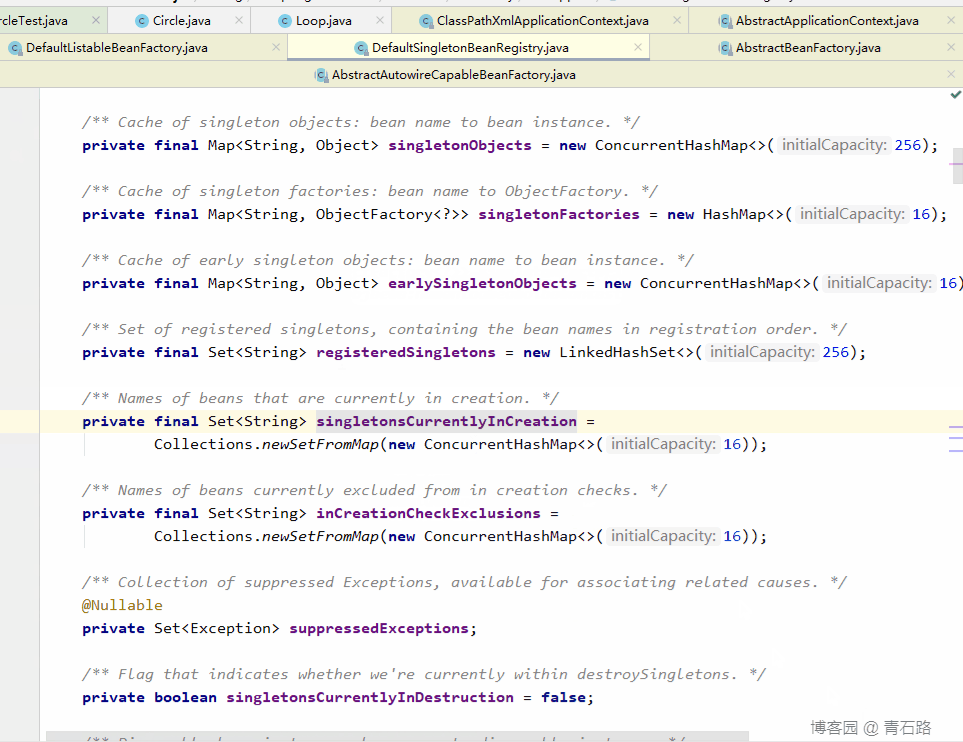
关键代码在 doCreateBean 中,其中有几个关键方法的调用值得大家去跟下

此时:代理对象的创建是在对象实例化完成,并且初始化也完成之后进行的,是对一个成品对象创建代理对象
所以此种情况下:只用一级缓存就够了,其他两个缓存可以不要
循环依赖,没有AOP
代码依旧非常简单:spring-circle-simple,此时循环依赖的两个类是: Circle 和 Loop
对象的创建过程与前面的基本一致,只是多了循环依赖,少了 AOP,所以我们重点关注: populateBean 和 initializeBean 方法
先创建的是 Circle 对象,那么我们就从创建它的 populateBean 开始,再开始之前,我们先看看三级缓存中的数据情况

我们开始跟 populateBean ,它完成属性的填充,与循环依赖有关,一定要仔细看,仔细跟

对 circle 对象的属性 loop 进行填充的时候,去 Spring 容器中找 loop 对象,发现没有则进行创建,又来到了熟悉的 createBean
此时三级缓存中的数据没有变化,但是 Set<String> singletonsCurrentlyInCreation 中多了个 loop
相信到这里大家都没有问题,我们继续往下看

loop 实例化完成之后,对其属性 circle 进行填充,去 Spring 中获取 circle 对象,又来到了熟悉的 doGetBean
此时一、二级缓存中都没有 circle、loop ,而三级缓存中有这两个,我们接着往下看,重点来了,仔细看哦

通过 getSingleton 获取 circle 时,三级缓存调用了 getEarlyBeanReference ,但由于没有 AOP,所以 getEarlyBeanReference 直接返回了普通的 半成品 circle
然后将 半成品 circle 放到了二级缓存,并将其返回,然后填充到了 loop 对象中
此时的 loop 对象就是一个成品对象了;接着将 loop 对象返回,填充到 circle 对象中,如下如所示

我们发现直接将 成品 loop 放到了一级缓存中,二级缓存自始至终都没有过 loop ,三级缓存虽说存了 loop ,但没用到就直接 remove 了
此时缓存中的数据,相信大家都能想到了

虽说 loop 对象已经填充到了 circle 对象中,但还有一丢丢流程没走完,我们接着往下看

将 成品 circle 放到了一级缓存中,二级缓存中的 circle 没有用到就直接 remove 了,最后各级缓存中的数据相信大家都清楚了,就不展示了
我们回顾下这种情况下各级缓存的存在感,一级缓存存在感十足,二级缓存可以说无存在感,三级缓存有存在感(向 loop 中填充 circle 的时候有用到)
所以此种情况下:可以减少某个缓存,只需要两级缓存就够了
循环依赖 + AOP
代码还是非常简单:spring-circle-aop,在循环依赖的基础上加了 AOP
比上一种情况多了 AOP,我们来看看对象的创建过程有什么不一样;同样是先创建 Circle ,在创建 Loop
创建过程与上一种情况大体一样,只是有小部分区别,跟源码的时候我会在这些区别上有所停顿,其他的会跳过,大家要仔细看
实例化 Circle ,然后填充 半成品 circle 的属性 loop ,去 Spring 容器中获取 loop 对象,发现没有
则实例化 Loop ,接着填充 半成品 loop 的属性 circle ,去 Spring 容器中获取 circle 对象

这个过程与前一种情况是一致的,就直接跳过了,我们从上图中的红色步骤开始跟源码,此时三级缓存中的数据如下

注意看啦,重要的地方来了

我们发现从第三级缓存获取 circle 的时候,调用了 getEarlyBeanReference 创建了 半成品 circle 的代理对象
将 半成品 circle 的代理对象放到了第二级缓存中,并将代理对象返回赋值给了 半成品 loop 的 circle 属性
注意:此时是在进行 loop 的初始化,但却把 半成品 circle 的代理对象提前创建出来了
loop 的初始化还未完成,我们接着往下看,又是一个重点,仔细看

在 initializeBean 方法中完成了 半成品 loop 的初始化,并在最后创建了 loop 成品 的代理对象
loop 代理对象创建完成之后会将其放入到第一级缓存中(移除第三级缓存中的 loop ,第二级缓存自始至终都没有 loop )
然后将 loop 代理对象返回并赋值给 半成品 circle 的属性 loop ,接着进行 半成品 circle 的 initializeBean

因为 circle 的代理对象已经生成过了(在第二级缓存中),所以不用再生成代理对象了;将第二级缓存中的 circle 代理对象移到第一级缓存中,并返回该代理对象
此时各级缓存中的数据情况如下(普通 circle 、 loop 对象在各自代理对象的 target 中)

我们回顾下这种情况下各级缓存的存在感,一级缓存仍是存在感十足,二级缓存有存在感,三级缓存挺有存在感
第三级缓存提前创建 circle 代理对象,不提前创建则只能给 loop 对象的属性 circle 赋值成 半成品 circle ,那么 loop 对象中的 circle 对象就无 AOP 增强功能了
第二级缓存用于存放 circle 代理,用于解决循环依赖;也许在这个示例体现的不够明显,因为依赖比较简单,依赖稍复杂一些,就能感受到了

第一级缓存存放的是对外暴露的对象,可能是代理对象,也可能是普通对象
所以此种情况下:三级缓存一个都不能少
循环依赖 + AOP + 删除第三级缓存
没有依赖,有AOP 这种情况中,我们知道 AOP 代理对象的生成是在成品对象创建完成之后创建的,这也是 Spring 的设计原则,代理对象尽量推迟创建
循环依赖 + AOP 这种情况中, circle 代理对象的生成提前了,因为必须要保证其 AOP 功能,但 loop 代理对象的生成还是遵循的 Spring 的原则
如果我们打破这个原则,将代理对象的创建逻辑提前,那是不是就可以不用三级缓存了,而只用两级缓存了呢?
代码依旧简单:spring-circle-custom,只是对 Spring 的源码做了非常小的改动,改动如下

去除了第三级缓存,并将代理对象的创建逻辑提前,置于实例化之后,初始化之前;我们来看下执行结果

并没有什么问题,有兴趣的可以去跟下源码,跟踪过程相信大家已经掌握,这里就不再演示了
循环依赖 + AOP + 注解
目前基于 xml 的配置越来越少,而基于注解的配置越来越多,所以了也提供了一个注解的版本供大家去跟源码
代码还是很简单:spring-circle-annotation
跟踪流程与 循环依赖 + AOP 那种情况基本一致,只是属性的填充有了一些区别,具体可查看:Spring 的自动装配 → 骚话 @Autowired 的底层工作原理
总结
1、三级缓存各自的作用
第一级缓存存的是对外暴露的对象,也就是我们应用需要用到的
第二级缓存的作用是为了处理循环依赖的对象创建问题,里面存的是半成品对象或半成品对象的代理对象
第三级缓存的作用处理存在 AOP + 循环依赖的对象创建问题,能将代理对象提前创建
2、Spring 为什么要引入第三级缓存
严格来讲,第三级缓存并非缺它不可,因为可以提前创建代理对象
提前创建代理对象只是会节省那么一丢丢内存空间,并不会带来性能上的提升,但是会破环 Spring 的设计原则
Spring 的设计原则是尽可能保证普通对象创建完成之后,再生成其 AOP 代理(尽可能延迟代理对象的生成)
所以 Spring 用了第三级缓存,既维持了设计原则,又处理了循环依赖;牺牲那么一丢丢内存空间是愿意接受的
加载全部内容