高通量计算框架HTCondor(五)——分布计算
charlee44 人气:2目录
- 1. 正文
- 1.1. 任务描述文件
- 1.2. 提交任务
- 1.3. 返回结果
- 2. 相关
1. 正文
1.1. 任务描述文件
前文提到过,HTCondor是通过condor_submit命令将提交任务的,这个命令需要提供一个任务描述文件。这个任务描述文件详细描述了任务运行的需求情况,如下所示:
universe = vanilla
requirements = (Arch == "INTEL" || Arch == "X86_64") && (OpSys == "WINDOWS") && (Machine == "charlee-PC" || Machine == "DESKTOP-OVHV440")
executable = D:\Work\HTC\Work\bin\TaskProgram.exe
should_transfer_files = YES
when_to_transfer_output = on_exit
notification = complete
skip_filechecks = true
arguments = 0
initialdir = D:\Work\HTC\Work\0
transfer_input_files = input.txt
transfer_output_files = output.dat
output = $(CLUSTER)_$(PROCESS).out
log = $(CLUSTER)_$(PROCESS).log
error = $(CLUSTER)_$(PROCESS).error
queue
arguments = 1
initialdir = D:\Work\HTC\Work\1
transfer_input_files = input.txt
transfer_output_files = output.dat
output = $(CLUSTER)_$(PROCESS).out
log = $(CLUSTER)_$(PROCESS).log
error = $(CLUSTER)_$(PROCESS).error
queue
...
arguments = 15
initialdir = D:\Work\HTC\Work\15
transfer_input_files = input.txt
transfer_output_files = output.dat
output = $(CLUSTER)_$(PROCESS).out
log = $(CLUSTER)_$(PROCESS).log
error = $(CLUSTER)_$(PROCESS).error
queueuniverse参数表示HTCondor的运行环境,默认为vanilla。vanilla提供的功能会少一些,但是使用也会较为方便。如果要使用一些高级的功能,可以使用standard环境,standard环境提供了断点和迁移的功能,不过需要一些额外的重链接操作生成特定的可执行程序。
requirements参数表示该一系列任务的需求。HTCondor采取了一种ClassAds匹配策略,每台计算机会一直在Pool中广播关于自己资源的Ad,通过这个参数,可以匹配该任务是否与该计算机适配。这里设置的意思是选择X86的Windows机器,且机器名称为"charlee-PC"或"DESKTOP-OVHV440"。使用"name == "slot1@USER-EHN3KRBP1V"的形式,甚至可以指定到某一核来运行。
executable也就是上一篇中实现的可执行程序。
should_transfer_files表示使用文件传输机制。文件传输机制也就是任务程序需要的数据,跟随任务程序一起发送到任务机中运行。如果不使用文件传输机制,就需要如NFS或AFS这样的共享文件系统。
when_to_transfer_output = on_exit表示当任务程序完成之后,会有输出的文件一起传送回本机。
接下来arguments开头queue结尾的代码描述了16组任务的详细描述。initialdir是初始化目录,也就是上一节中创建的每个分任务的目录。
transfer_input_files表示传送到任务机的文件。这个参数可以设置成具体的文件,目录,设置是可执行程序依赖的dll。注意发送到任务机后这些文件与执行任务文件在同一个目录中。
when_to_transfer_output表示发送回本机的文件。当任务程序运行完成后,会生成处理好的数据,可以通过这个参数将文件传送回本机。
output表示任务程序的输出文件,可以截获任务程序的stdout流。
log表示集群执行任务程序的状态,一般是HTCondor框架自动生成。
error表示任务程序的错误文件,可以截获任务程序的stderr流。
1.2. 提交任务
在命令提示符窗口中输入condor_submit指令:

可以看到成功提交后,返回了一个任务ID号。可以通过condor_q指令查看当前的任务队列状态:
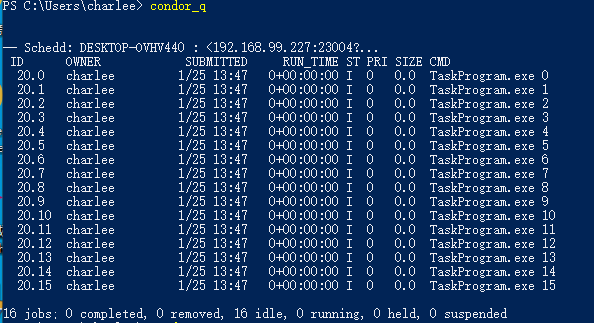
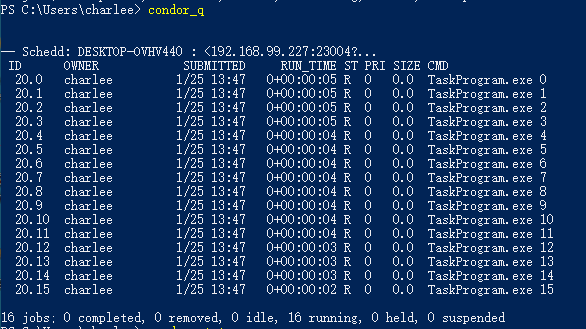
ST这一列的I代表idle,也就是闲置的。这时由于任务刚提交上去,还来不及匹配任务机器或者没有更新状态,多刷新几次,可以看到这一栏会编程R,也就是Run,表示运行状态:
继续输入condor_status,查看当前计算机资源的情况。这时的状态刷新会更慢些,也可以多输入几次:

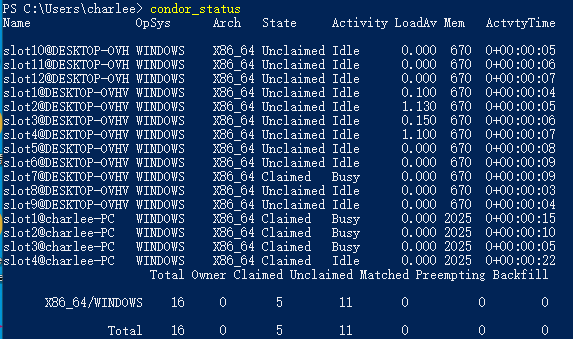
State表示资源占用情况,Claimed表示已占用,Claimed表示未占用。Activity表示当前的活动状态,Idle就是闲置,Busy表示繁忙。
通过以上指令,可以查看当前任务是否正常。等待直到condor_q中的任务队列为空,就说明当前所有的任务已经完成了。
1.3. 返回结果
根据任务描述文件,任务程序会返回一个输出数据output.dat已经相关的日志信息.log、.out、.error。任务完成后会回传到各自的初始化目录中:
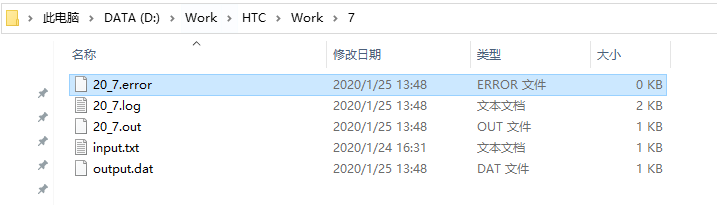
.out是任务程序的stdout流,可以用来输出信息;.error是任务程序的stderr流,可以用来输出错误信息。在任务程序中输出信息和日志是必要的,可以第一事件排查是哪一段代码出问题。如果连这两个文件都没有,可以考虑是否是HTCondor的环境配置问题,或者任务描述文件是否出错。
.log是HTCondor的输出日志,可以用来参考。output.dat就是任务程序的输出数据了,当然这个数据因任务程序而异,任务程序输出什么,任务描述文件就返回对应的数据,当然也可以什么都不用返回。
在HTCondor任务程序计算的过程中,会把任务程序传送到对应的任务机器,也就是任务机器HTCondor安装目录的execute目录中,运行时会看到任务程序,以及传送过来的数据等:

当然,在运行完成后,这个execute目录就会自动清空。
至此,一个简单的分布式计算流程就算完成了。实际的运用当然没这么简单,但是总体的思路都是这样的:
拆分任务——提交任务——监视任务——任务完成——合并结果。
2. 相关
代码和数据地址
上一篇
目录
下一篇
加载全部内容