B-Tree 和 B+Tree 结构及应用,InnoDB 引擎, MyISAM 引擎
永不停转 人气:11.什么是B-Tree 和 B+Tree,他们是做什么用的?
B-Tree是为了磁盘或其它存储设备而设计的一种多叉平衡查找树,B-Tree 和 B+Tree 广泛应用于文件存储系统以及数据库系统中。
1、每个节点最多拥有m个子树
2、根节点至少有2个子树
3、分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
4、所有叶子节点都在同一层
5、每个节点最多可以有m-1个key
6、每个节点中的key以升序排列
7、节点中key元素左节点的所有值都小于或等于该元素,元素右节点的所有值都大于或等于该元素
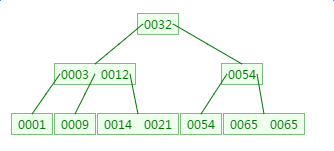
2.2.B-Tree的建立过程
下面我们以一个[0,1,2,3,4,5,6,7]的数组插入一棵 3 阶的 B-Tree 为例,将所有的条件都串起来!

那么,你是否对 B-Tree 的几点特性都清晰了呢?在二叉树中,每个结点只有一个元素。

但是在 B-Tree 中,每个结点都可能包含多个元素,并且非叶子结点在元素的左右都有指向子结点的指针。
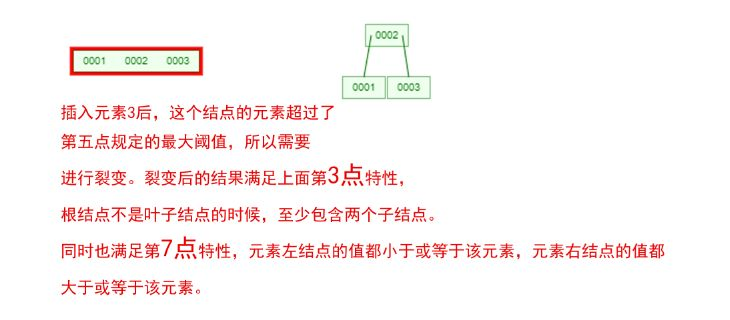
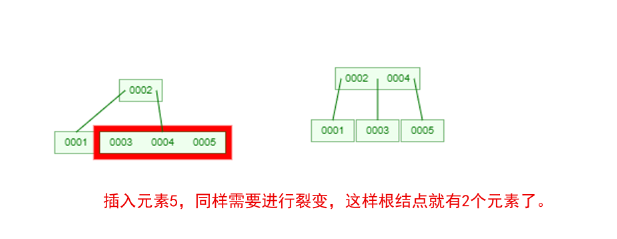
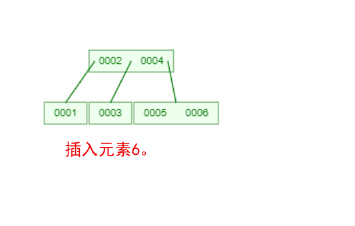
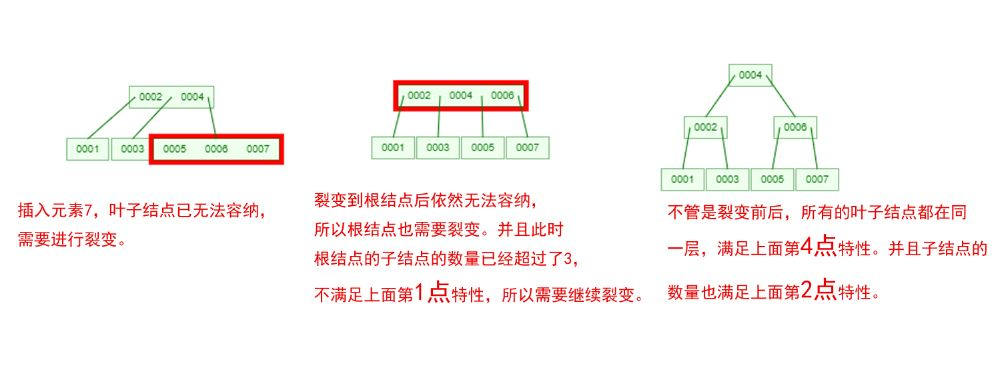
在 B-Tree 中,每个结点都可能包含多个元素,并且非叶子结点在元素的左右都有指向子结点的指针。
2.3.B-Tree搜索原理
如果需要查找一个元素,那流程是怎么样的呢?我们看下图,如果我们要在下面的 B-Tree 中找到关键字 24,那流程如下:
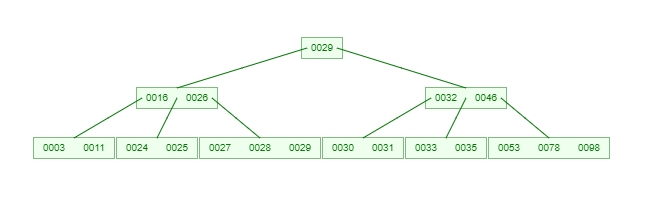
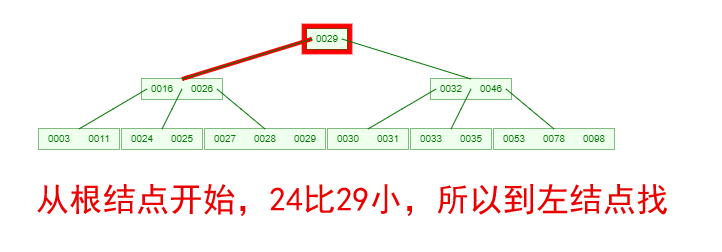
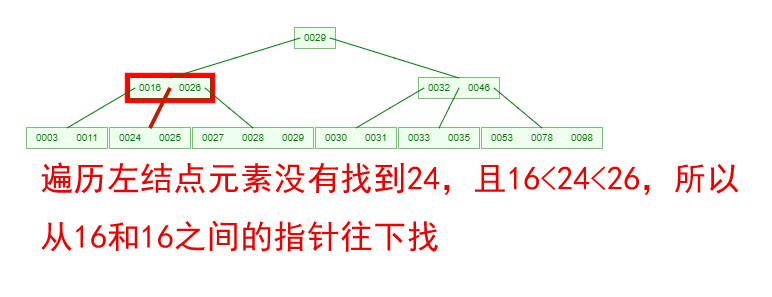
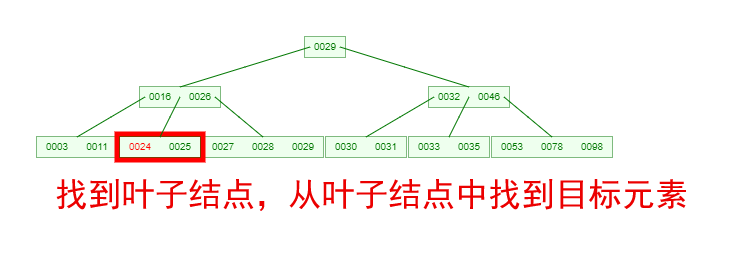
从这个流程我们能看出,B-Tree 的查询效率好像也并不比平衡二叉树高。但是查询所经过的结点数量要少很多,也就意味着要少很多次的磁盘 IO,这对性能的提升是很大的。
从前面对 B-Tree 操作的图,我们能看出来,元素就是类似 1、2、3 这样的数值。
2.4.B-Tree在数据库中的应用
但是数据库的数据都是一条条的数据,如果某个数据库以 B-Tree 的数据结构存储数据,那数据怎么存放的呢?
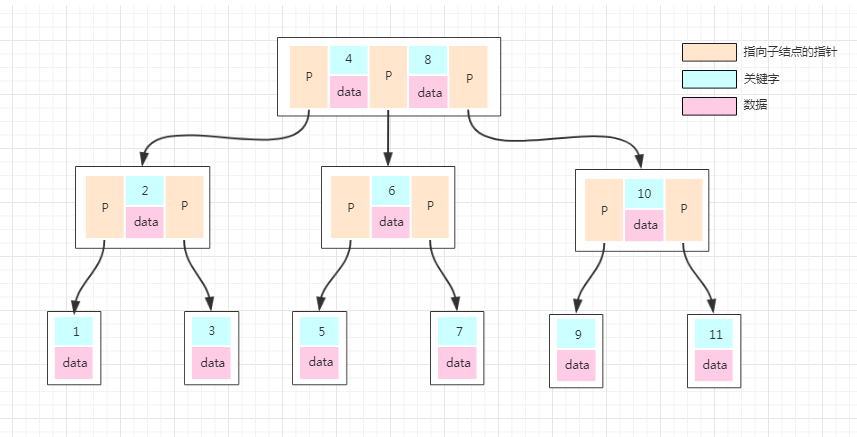
普通的 B-Tree 的结点中,元素就是一个个的数字。但是上图中,我们把元素部分拆分成了 key-data 的形式,Key 就是数据的主键,Data 就是具体的数据。
这样我们在找一条数的时候,就沿着根结点往下找就 OK 了,效率是比较高的。
3.B+Tree
B+Tree 是在 B-Tree 基础上的一种优化,使其更适合实现外存储索引结构。
B+Tree 与 B-Tree 的结构很像,但是也有几个自己的特性:
-
所有的非叶子节点只存储关键字信息。
-
所有卫星数据(具体数据)都存在叶子结点中。
-
所有的叶子结点中包含了全部元素的信息。
-
所有叶子节点之间都有一个链指针。
-
如果上面 B-Tree 的图变成 B+Tree,那应该如下:
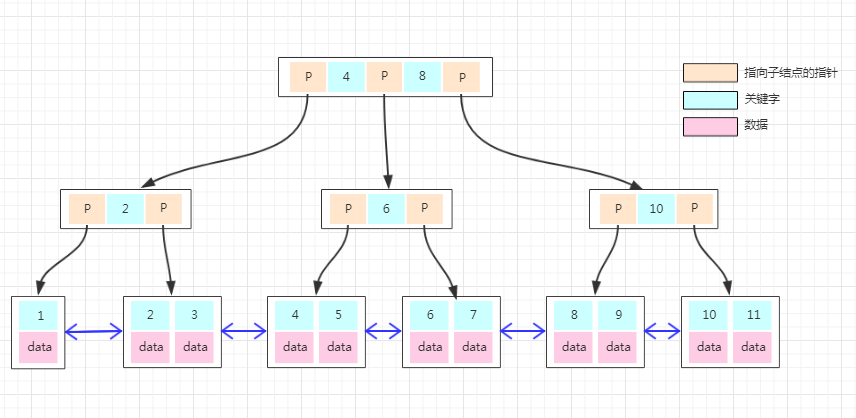
细对比于 B-Tree 的图,他们之间存在以下不同:
-
-
非叶子结点上已经只有 Key 信息了,满足上面第 1 点特性!
-
所有叶子结点下面都有一个 Data 区域,满足上面第 2 点特性!
-
非叶子结点的数据在叶子结点上都能找到,如根结点的元素 4、8 在最底层的叶子结点上也能找到,满足上面第 3 点特性!
-
注意图中叶子结点之间的箭头,满足上面第 4 点特性!
-
4、B-Tree 和 B+Tree 该如何选择呢?都有哪些优劣呢?
①B-Tree 因为非叶子结点也保存具体数据,所以在查找某个关键字的时候找到即可返回。
而 B+Tree 所有的数据都在叶子结点,每次查找都得到叶子结点。所以在同样高度的 B-Tree 和 B+Tree 中,B-Tree 查找某个关键字的效率更高。
②由于 B+Tree 所有的数据都在叶子结点,并且结点之间有指针连接,在找大于某个关键字或者小于某个关键字的数据的时候,B+Tree 只需要找到该关键字然后沿着链表遍历就可以了,而 B-Tree 还需要遍历该关键字结点的根结点去搜索。
③由于 B-Tree 的每个结点(这里的结点可以理解为一个数据页)都存储主键+实际数据,而 B+Tree 非叶子结点只存储关键字信息,而每个页的大小是有限的,所以同一页能存储的 B-Tree 的数据会比 B+Tree 存储的更少。
这样同样总量的数据,B-Tree 的深度会更大,增大查询时的磁盘 I/O 次数,进而影响查询效率。
鉴于以上的比较,所以在常用的关系型数据库中,都是选择 B+Tree 的数据结构来存储数据!
下面我们以 MySQL 的 InnoDB 存储引擎为例讲解,其他类似 SQL Server、Oracle 的原理!
InnoDB 引擎数据存储
在 InnoDB 存储引擎中,也有页的概念,默认每个页的大小为 16K,也就是每次读取数据时都是读取 4*4K 的大小!
假设我们现在有一个用户表,我们往里面写数据:
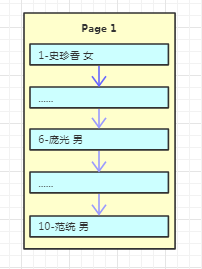
这里需要注意的一点是,在某个页内插入新行时,为了减少数据的移动,通常是插入到当前行的后面或者是已删除行留下来的空间,所以在某一个页内的数据并不是完全有序的(后面页结构部分有细讲)。
但是为了数据访问顺序性,在每个记录中都有一个指向下一条记录的指针,以此构成了一条单向有序链表,不过在这里为了方便演示我是按顺序排列的!
由于数据还比较少,一个页就能容下,所以只有一个根结点,主键和数据也都是保存在根结点(左边的数字代表主键,右边名字、性别代表具体的数据)。
假设我们写入 10 条数据之后,Page1 满了,再写入新的数据会怎么存放呢?
我们继续看下图:
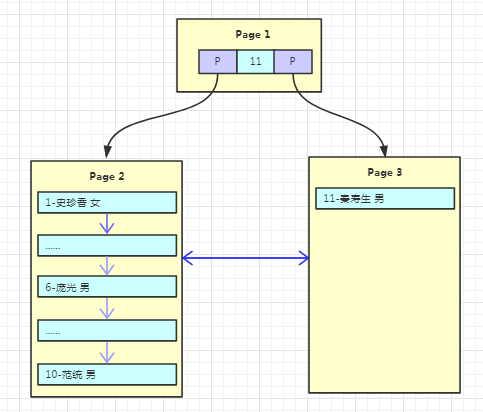
有个叫“秦寿生”的朋友来了,但是 Page1 已经放不下数据了,这时候就需要进行页分裂,产生一个新的 Page。
在 InnoDB 中的流程是怎么样的呢?
-
-
产生新的 Page2,然后将 Page1 的内容复制到 Page2。
-
产生新的 Page3,“秦寿生”的数据放入 Page3。
-
原来的 Page1 依然作为根结点,但是变成了一个不存放数据只存放索引的页,并且有两个子结点 Page2、Page3。
-
这里有两个问题需要注意的是:
①为什么要复制 Page1 为 Page2 而不是创建一个新的页作为根结点,这样就少了一步复制的开销了?
如果是重新创建根结点,那根结点存储的物理地址可能经常会变,不利于查找。
并且在 InnoDB 中根结点是会预读到内存中的,所以结点的物理地址固定会比较好!
②原来 Page1 有 10 条数据,在插入第 11 条数据的时候进行裂变,根据前面对 B-Tree、B+Tree 特性的了解,那这至少是一棵 11 阶的树,裂变之后每个结点的元素至少为 11/2=5 个。
那是不是应该页裂变之后主键 1-5 的数据还是在原来的页,主键 6-11 的数据会放到新的页,根结点存放主键 6?
如果是这样的话,新的页空间利用率只有 50%,并且会导致更为频繁的页分裂。
所以 InnoDB 对这一点做了优化,新的数据放入新创建的页,不移动原有页面的任何记录。
随着数据的不断写入,这棵树也逐渐枝繁叶茂,如下图:
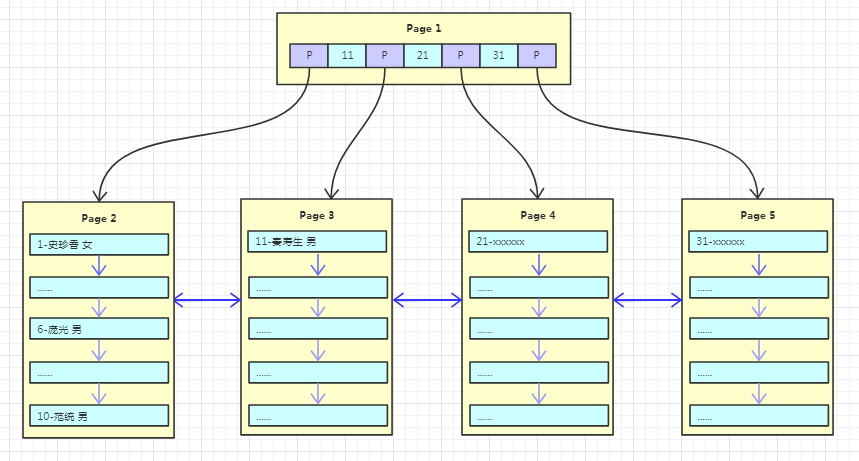
每次新增数据,都是将一个页写满,然后新创建一个页继续写,这里其实是有个隐含条件的,那就是主键自增!
主键自增写入时新插入的数据不会影响到原有页,插入效率高!且页的利用率高!
但是如果主键是无序的或者随机的,那每次的插入可能会导致原有页频繁的分裂,影响插入效率!降低页的利用率!这也是为什么在 InnoDB 中建议设置主键自增的原因!
这棵树的非叶子结点上存的都是主键,那如果一个表没有主键会怎么样?在 InnoDB 中,如果一个表没有主键,那默认会找建了唯一索引的列,如果也没有,则会生成一个隐形的字段作为主键!
有数据插入那就有删除,如果这个用户表频繁的插入和删除,那会导致数据页产生碎片,页的空间利用率低,还会导致树变的“虚高”,降低查询效率!这可以通过索引重建来消除碎片提高查询效率!
InnoDB 引擎数据查找
数据插入了怎么查找呢?
-
-
找到数据所在的页。这个查找过程就跟前面说到的 B+Tree 的搜索过程是一样的,从根结点开始查找一直到叶子结点。
-
在页内找具体的数据。读取第 1 步找到的叶子结点数据到内存中,然后通过分块查找的方法找到具体的数据。
-
这跟我们在新华字典中找某个汉字是一样的,先通过字典的索引定位到该汉字拼音所在的页,然后到指定的页找到具体的汉字。
InnoDB 中定位到页后用了哪种策略快速查找某个主键呢?这我们就需要从页结构开始了解。
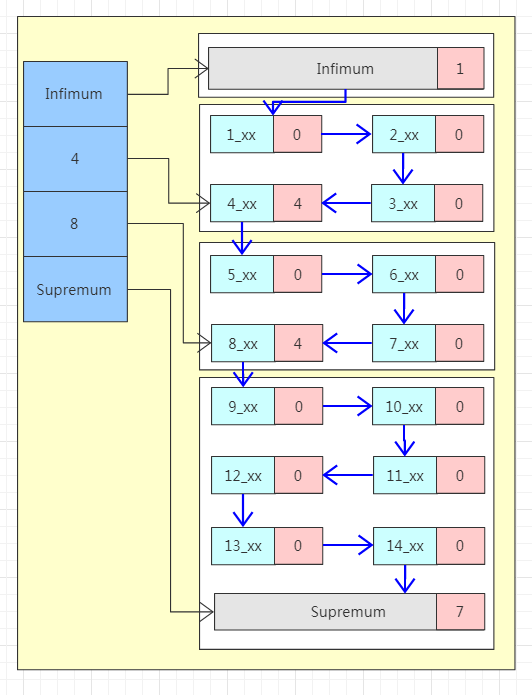
左边蓝色区域称为 Page Directory,这块区域由多个 Slot 组成,是一个稀疏索引结构,即一个槽中可能属于多个记录,最少属于 4 条记录,最多属于 8 条记录。
槽内的数据是有序存放的,所以当我们寻找一条数据的时候可以先在槽中通过二分法查找到一个大致的位置。
右边区域为数据区域,每一个数据页中都包含多条行数据。注意看图中最上面和最下面的两条特殊的行记录 Infimum 和 Supremum,这是两个虚拟的行记录。
在没有其他用户数据的时候 Infimum 的下一条记录的指针指向 Supremum。
当有用户数据的时候,Infimum 的下一条记录的指针指向当前页中最小的用户记录,当前页中最大的用户记录的下一条记录的指针指向 Supremum,至此整个页内的所有行记录形成一个单向链表。
行记录被 Page Directory 逻辑的分成了多个块,块与块之间是有序的,也就是说“4”这个槽指向的数据块内最大的行记录的主键都要比“8”这个槽指向的数据块内最小的行记录的主键要小。但是块内部的行记录不一定有序。
每个行记录的都有一个 n_owned 的区域(图中粉红色区域),n_owned 标识这个块有多少条数据。
伪记录 Infimum 的 n_owned 值总是 1,记录 Supremum 的 n_owned 的取值范围为[1,8],其他用户记录 n_owned 的取值范围[4,8]。
并且只有每个块中最大的那条记录的 n_owned 才会有值,其他的用户记录的 n_owned 为 0。
所以当我们要找主键为 6 的记录时,先通过二分法在稀疏索引中找到对应的槽,也就是 Page Directory 中“8”这个槽。
“8”这个槽指向的是该数据块中最大的记录,而数据是单向链表结构,所以无法逆向查找。
所以需要找到上一个槽即“4”这个槽,然后通过“4”这个槽中最大的用户记录的指针沿着链表顺序查找到目标记录。
聚集索引&非聚集索引
前面关于数据存储的都是演示的聚集索引的实现,如果上面的用户表需要以“用户名字”建立一个非聚集索引,是怎么实现的呢?
我们看下图:
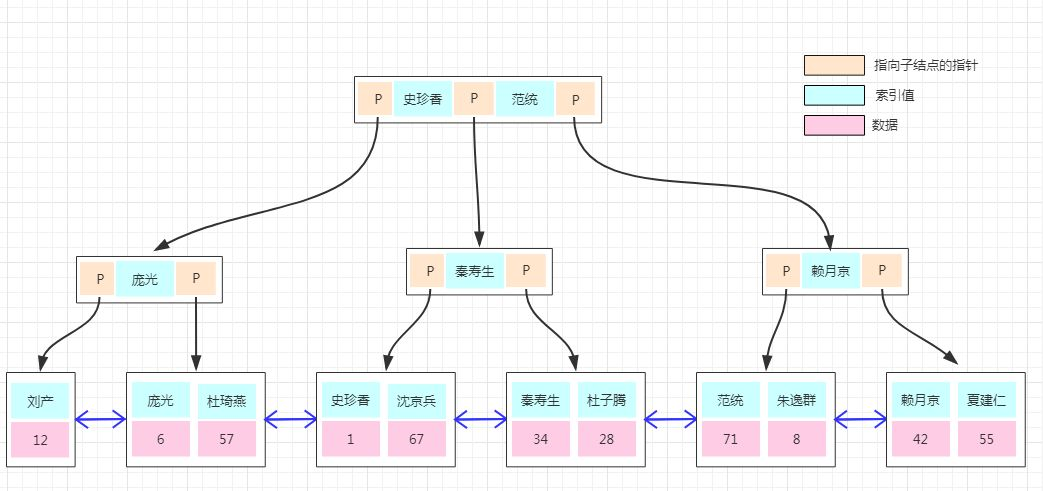
非聚集索引的存储结构与前面是一样的,不同的是在叶子结点的数据部分存的不再是具体的数据,而是数据的聚集索引的 Key。
所以通过非聚集索引查找的过程是先找到该索引 Key 对应的聚集索引的 Key,然后再拿聚集索引的 Key 到主键索引树上查找对应的数据,这个过程称为回表!
InnoDB 与 MyISAM 引擎对比
上面包括存储和搜索都是拿的 InnoDB 引擎为例,那 MyISAM 与 InnoDB 在存储上有啥不同呢?看图:
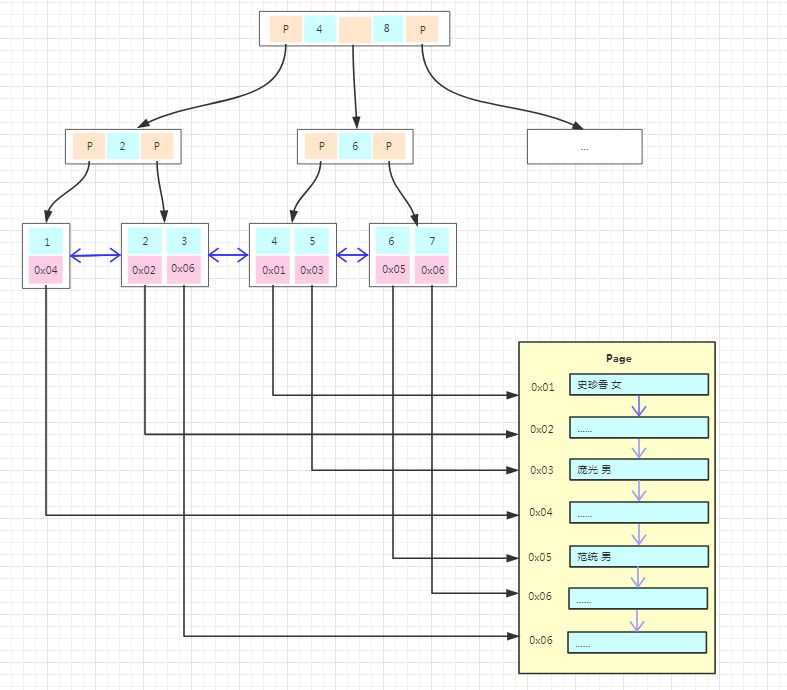
上图为 MyISAM 主键索引的存储结构,我们能看到的不同是:
-
-
主键索引树的叶子结点的数据区域没有存放实际的数据,存放的是数据记录的地址。
-
数据的存储不是按主键顺序存放的,是按写入的顺序存放。
-
也就是说 InnoDB 引擎数据在物理上是按主键顺序存放,而 MyISAM 引擎数据在物理上按插入的顺序存放。
并且 MyISAM 的叶子结点不存放数据,所以非聚集索引的存储结构与聚集索引类似,在使用非聚集索引查找数据的时候通过非聚集索引树就能直接找到数据的地址了,不需要回表,这比 InnoDB 的搜索效率会更高呢!
索引优化建议
大家经常会在很多的文章或书中能看到一些索引的使用建议,比如说:
-
-
like 的模糊查询以 % 开头,会导致索引失效。
-
一个表建的索引尽量不要超过 5 个。
-
尽量使用覆盖索引。
-
尽量不要在重复数据多的列上建索引。
-
......
-
很多这里就不一一列举了!那看完这篇文章,我们能否带着疑问去分析一下为什么要有这些建议?
为什么 like 的模糊查询以 % 开头,会导致索引失效?为什么一个表建的索引尽量不要超过 5 个?
加载全部内容