python爬取图片方法 python根据用户需求输入想爬取的内容及页数爬取图片方法详解
派大星.. 人气:0想了解python根据用户需求输入想爬取的内容及页数爬取图片方法详解的相关内容吗,派大星..在本文为您仔细讲解python爬取图片方法的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:python爬取,爬取图片,python爬取图片,下面大家一起来学习吧。
本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数。
主要步骤:
1.提示用户输入爬取的内容及页码。
2.根据用户输入,获取网址列表。
3.模拟浏览器向服务器发送请求,获取响应。
4.利用xpath方法找到图片的标签。
5.保存数据。
代码用面向过程的形式编写的。
关键字:requests库,xpath,面向过程
现在就来讲解代码书写的过程:
1.导入模块
import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配 import requests # 爬虫主要的包 from urllib.request import urlretrieve # 本文用来下载图片 import os # 标准库,本文用来新建文件夹
每个模块的作用都已经备注了。
2.提示用户输入内容和页数
if not os.path.exists("王一博图片"):
os.mkdir("王一博图片") # 判断有没有该文件夹,如果没有就创建改文件夹
k = input("请输入你想搜索的关键字:")
num = int(input("请输入你想搜索的页数:"))
3.准备好url和header
header = {"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Mobile Safari/537.36"
}
base_url = "https://www.duitang.com/search/?kw=" + k + "&type=feed#!s-p"
title_url = []
n = 0
user-agent是服务器识别浏览器的重要参数,我们就用这个来蒙骗服务器,user-agent在浏览器里可以找到
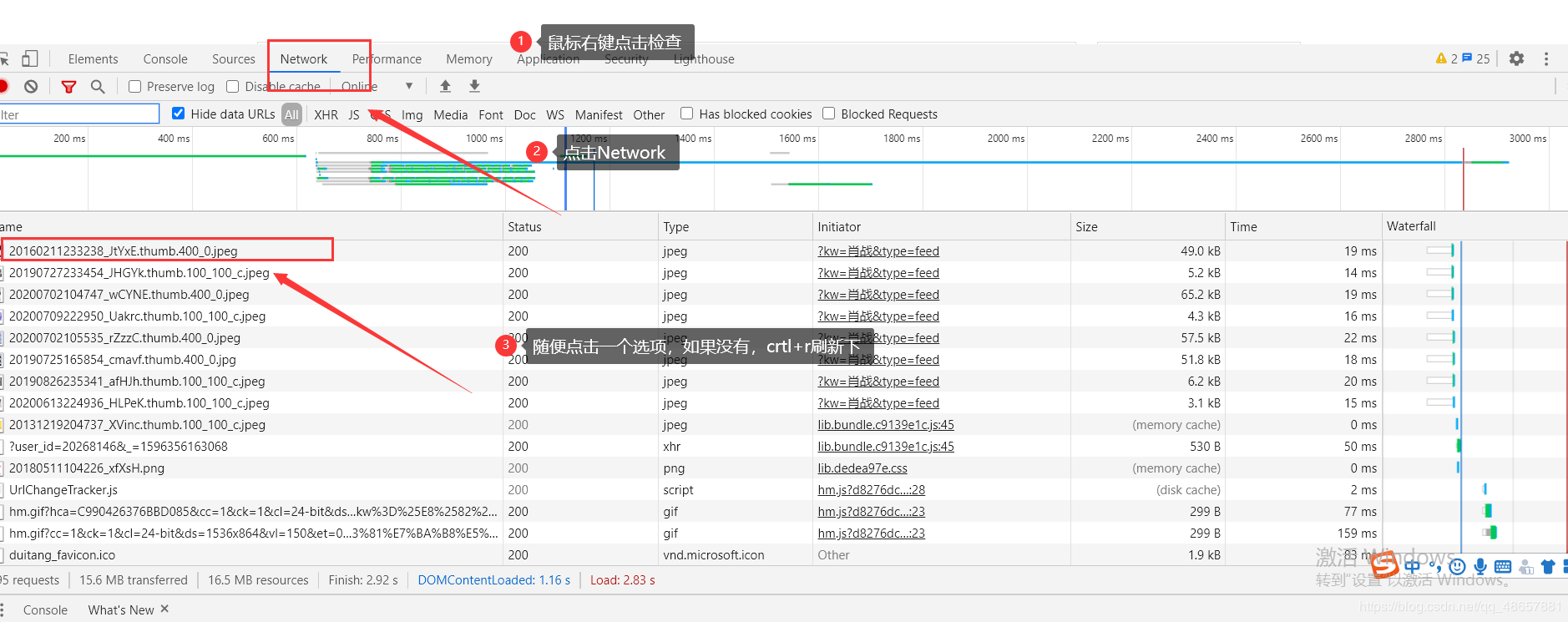
那么现在我们就关注右边
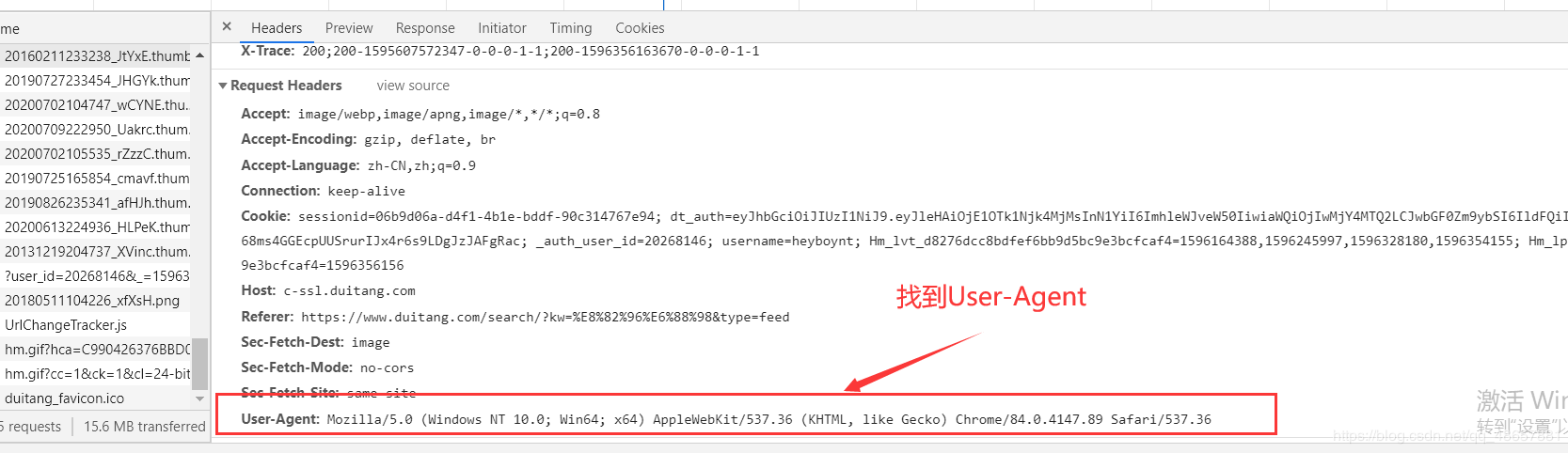
这样header就找到了,注意要以字典的形式
4.发送请求、
for i in range(num):
title_url = base_url + str(i)
respons = requests.get(title_url, headers=header).text
html = parsel.Selector(respons) # 解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
pic_url = html.xpath('//div[@class="mbpho"]/a/img/@src').extract()
一切准备就绪后,就可以发送请求了。request.get.text返回的是网页的源代码,然后将源代码转换为Selector对象,再通过xpath的方法找到图片的网址。
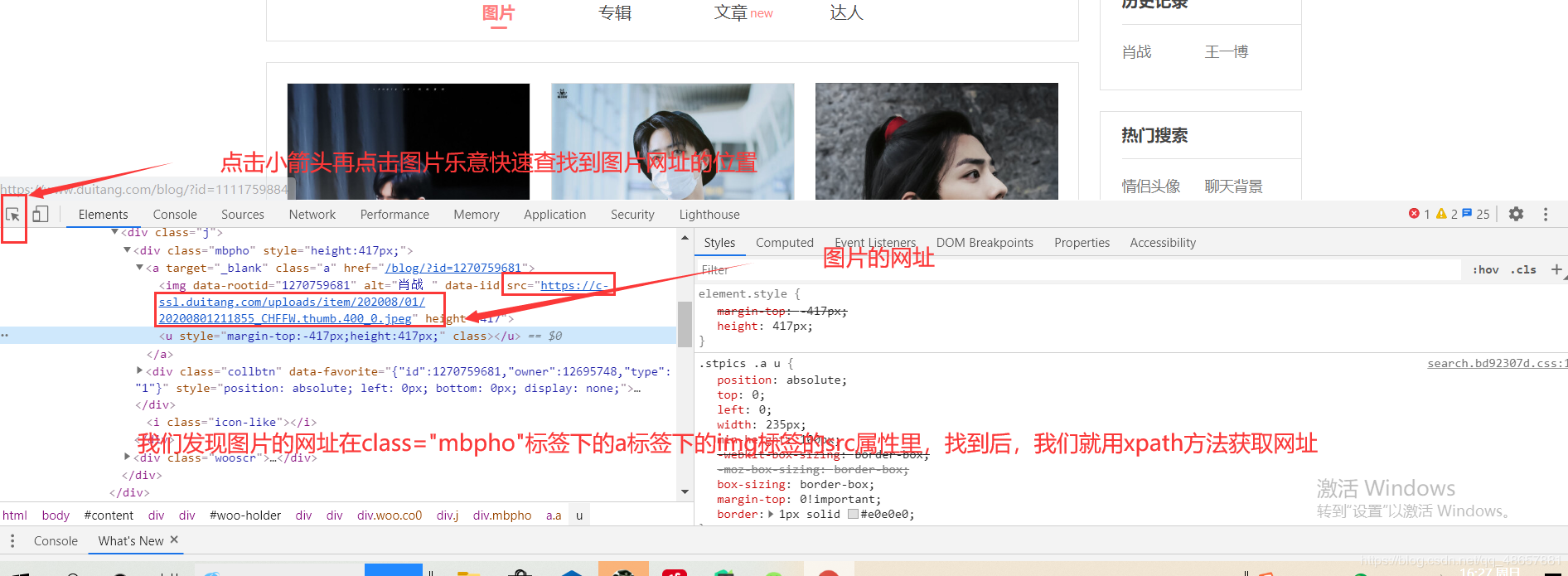
xpath的方法可以参考:https://zhuanlan.zhihu.com/p/29436838
5.保存数据
获取图片的图片的链接后,我们就可以保存了。
for url in pic_url:
n = n + 1
file_path = "王一博图片" + '/' + str(n)+".jpg"
urlretrieve(url, file_path) # 下载图片,具体的用法可以去搜索下,很简单的
print("第%d张图片下载成功" % n)
注意:这里的for循环是在上面的循环里嵌套的。
最后来看看全部的代码吧!
import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配
import requests
from urllib.request import urlretrieve # 本文用来下载图片
import os # 标准库,本文用来新建文件夹
if not os.path.exists("王一博图片"):
os.mkdir("王一博图片") # 判断有没有该文件夹,如果没有就创建改文件夹
k = input("请输入你想搜索的关键字:")
num = int(input("请输入你想搜索的页数:"))
header = {"user-agent":
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Mobile Safari/537.36"
}
base_url = "https://www.duitang.com/search/?kw=" + k + "&type=feed#!s-p"
title_url = []
n = 0
for i in range(num):
title_url = base_url + str(i)
respons = requests.get(title_url, headers=header).text
html = parsel.Selector(respons)
pic_url = html.xpath('//div[@class="mbpho"]/a/img/@src').extract()
# print(pic_url)
for url in pic_url:
n = n + 1
file_path = "王一博图片" + '/' + str(n)+".jpg"
urlretrieve(url, file_path) # 下载图片,具体的用法可以去搜索下,很简单的
print("第%d张图片下载成功" % n)
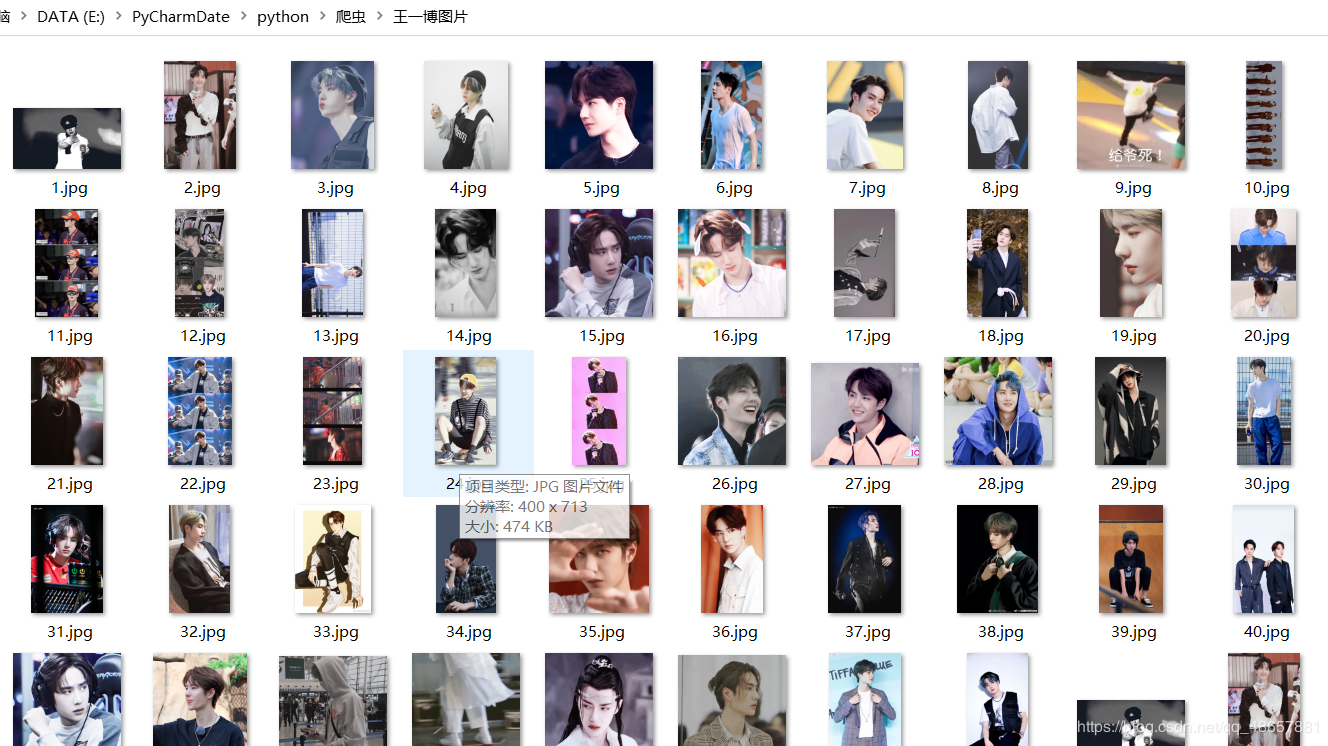
来看看运行的结果,以搜索王一博,搜索5页为例。
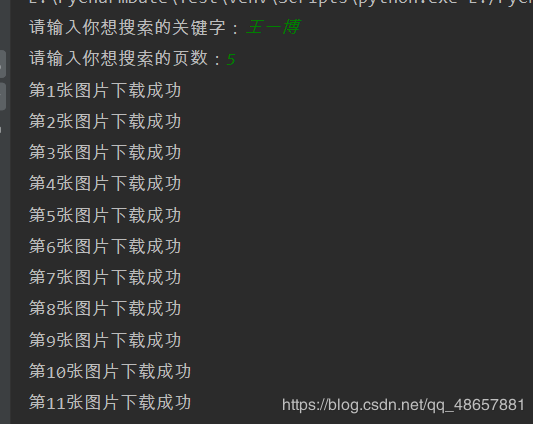
然后你就发信多了一个王一博的文件夹了,点开就可以看见王一博的帅照了。
到此这篇关于python根据用户需求输入想爬取的内容及页数爬取图片方法详解的文章就介绍到这了,更多相关python爬取图片方法内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
加载全部内容