WebGL简易教程(十五):加载gltf模型
charlee44 人气:1目录
- 1. 概述
- 2. 实例
- 2.1. 数据
- 2.2. 程序
- 2.2.1. 文件读取
- 2.2.2. glTF格式解析
- 2.2.3. 初始化顶点缓冲区
- 2.2.4. 其他
- 3. 结果
- 4. 参考
- 5. 相关
1. 概述
一般来说,图形渲染总是需要从磁盘数据开始,最终保存到磁盘数据中,保存这种数据的就是3D模型文件。3D模型文件一般会把顶点、索引、纹理、材质等等信息都保存起来,方便下次直接读取。3D模型文件格式一般是与图形渲染工作强关联的,了解3D模型文件格式的组成,有助于进一步了解图形渲染的流程。
glTF可以说是专门为WebGL量身定制的数据格式,具有以下特点:
- 场景数据结构是使用JSON来描述的,读取后即可解析,无需再自定义组织对象。
- buffer数据被保存为二进制文件,占用空间小,读取后即可使用,无需转换过程。
- 纹理数据可以使用jpg文件,方便压缩和传输。
从以上特性可以看出,glTF特别方便与互联网的使用场景,便于传输且预处理程度小。在这篇教程中,就通过一个带纹理的地形文件,具体解析以下glTF格式,顺便加深一下WebGL中初始化数据的理解。
2. 实例
2.1. 数据
使用的地形glTF文件已经处理好并上传到文章末尾的地址中(具体的转换过程可以参看《DEM转换为gltf》)。glTF是这样一个JSON文件:
{
"asset": {
"generator": "CL",
"version": "2.0"
},
"scene": 0,
"scenes": [
{
"nodes": [
0
]
}
],
"nodes": [
{
"mesh": 0
}
],
"meshes": [
{
"primitives": [
{
"attributes": {
"POSITION": 1,
"TEXCOORD_0": 2
},
"indices": 0,
"material": 0
}
]
}
],
"materials": [
{
"pbrMetallicRoughness": {
"baseColorTexture": {
"index": 0
}
}
}
],
"textures": [
{
"sampler": 0,
"source": 0
}
],
"images": [
{
"uri": "tex.jpg"
}
],
"samplers": [
{
"magFilter": 9729,
"minFilter": 9987,
"wrapS": 33648,
"wrapT": 33648
}
],
"buffers": [
{
"uri": "new.bin",
"byteLength": 595236
}
],
"bufferViews": [
{
"buffer": 0,
"byteOffset": 374400,
"byteLength": 220836,
"target": 34963
},
{
"buffer": 0,
"byteStride": 20,
"byteOffset": 0,
"byteLength": 374400,
"target": 34962
}
],
"accessors": [
{
"bufferView": 0,
"byteOffset": 0,
"componentType": 5123,
"count": 110418,
"type": "SCALAR",
"max": [
18719
],
"min": [
0
]
},
{
"bufferView": 1,
"byteOffset": 0,
"componentType": 5126,
"count": 18720,
"type": "VEC3",
"max": [
770,
0.0,
1261.151611328125
],
"min": [
0.0,
-2390,
733.5555419921875
]
},
{
"bufferView": 1,
"byteOffset": 12,
"componentType": 5126,
"count": 18720,
"type": "VEC2",
"max": [
1,
1
],
"min": [
0,
0
]
}
]
}
可以看到这个文件链接了两个外部文件new.bin和tex.jpg。new.bin也就是保存的顶点数据信息,是个二进制文件,tex.jpg也就是纹理图片。将这个数据导入到glTF Viewer网站上查看,显示结果如下:

注意,由于安全策略的原因,浏览器导入数据时应该将new.gltf、new.bin、tex.jpg这三个文件一同导入,否则无法正确读取显示。
2.2. 程序
2.2.1. 文件读取
由于需要一次性加载多个文件,所以需要将input控件改成支持多文件的:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title> 显示地形 </title>
</head>
<body onload="main()">
<div><input type='file' id='demFile' multiple="multiple"></div>
<div>
<canvas id="webgl" width="600" height="600">
请使用支持WebGL的浏览器
</canvas>
</div>
<script src="../lib/webgl-utils.js"></script>
<script src="../lib/webgl-debug.js"></script>
<script src="../lib/cuon-utils.js"></script>
<script src="../lib/cuon-matrix.js"></script>
<script src="TerrainViewer.js"></script>
</body>
</html>在glTF Viewer网站中查看glTF的原理并不是将数据提交到后台,而是直接交给前段页面的JS进行读取。可以通过FileReader对象来进行读取。FileReader读取的好处是不会触发浏览器的安全策略,不用设置跨域(至少chrome不用):
var demFile = document.getElementById('demFile');
if (!demFile) {
console.log("Failed to get demFile element!");
return;
}
//加载文件后的事件
demFile.addEventListener("change", function (event) {
//判断浏览器是否支持FileReader接口
if (typeof FileReader == 'undefined') {
console.log("你的浏览器不支持FileReader接口!");
return;
}
//读取文件后的事件
var reader = new FileReader();
reader.onload = function () {
if (reader.result) {
var gltfObj = JSON.parse(reader.result);
for (var fi = 0; fi < input.files.length; fi++) {
//读取bin文件
if (gltfObj.buffers[0].uri === input.files[fi].name) {
var binReader = new FileReader();
binReader.onload = function () {
if (binReader.result) {
for (var fi = 0; fi < input.files.length; fi++) {
if (gltfObj.images[0].uri === input.files[fi].name) {
//读取纹理图像
var imgReader = new FileReader();
imgReader.onload = function () {
//创建一个image对象
var image = new Image();
if (!image) {
console.log('Failed to create the image object');
return false;
}
//图像加载的响应函数
image.onload = function () {
//绘制函数
onDraw(gl, canvas, gltfObj, binReader.result, image);
};
//浏览器开始加载图像
image.src = imgReader.result;
}
imgReader.readAsDataURL(input.files[fi]); //按照base64格式读取
break;
}
}
}
}
binReader.readAsArrayBuffer(input.files[fi]); //按照ArrayBuffer格式读取
break;
}
}
}
}
var input = event.target;
var flag = false;
for (var fi = 0; fi < input.files.length; fi++) {
if (getFileSuffix(input.files[fi].name) === "gltf") {
flag = true;
reader.readAsText(input.files[fi]); //按照字符串格式读取
break;
}
}
if (!flag) {
alert("没有找到gltf");
}
});这段代码看起来很繁复,其实原理很简单:遍历加载的文件,对于gltf文件采用FileReader.readAsText()也就是字符串格式的方法读取,这个字符串随后被解析成JSON;对于bin文件采用FileReader.readAsArrayBuffer()读取,将其读取成ArrayBuffer对象;对于jpg文件采用FileReader.readAsDataURL读取,将其读取成data:url开头的base64字符串,这个字符串可以直接生成JS的Image对象。
注意FileReader的读取方式都是异步读取,必须等到三个文件都读取完成,才调用onDraw()函数进行绘制。读取得到的对象也不用再多做处理,可以直接在后面的初始化步骤中使用。
2.2.2. glTF格式解析
初始化顶点缓冲区函数initVertexBuffers()中就用到了之前获取的对象。gltfObj是获取的JSON对象,里面记录了对三维物体的描述信息。具体解析如下:
2.2.2.1. 场景节点
"asset": {
"generator": "CL",
"version": "2.0"
},
"scene": 0,
"scenes": [
{
"nodes": [
0
]
}
],
"nodes": [
{
"mesh": 0
}
],asset表示的是元数据信息,version一般为2.0。
scene是整个场景的入口,0表示scenes数组的第一个;scenes节点又包含了一个nodes数组,其中每个nodes对象包含一个children数组,这一数组引用了nodes对象的所有子结点。通过孩子结点,构成了整个场景结构:
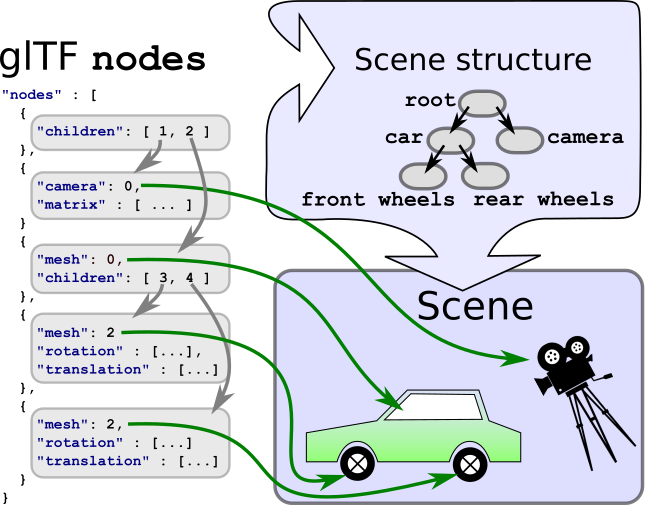
这一段描述的其实是场景的结构层次模型。基本上来讲,一般的三维渲染引擎都会将三维场景中的物体分解成节点,采用树的结构来描述场景,这样做能够很方便的进行状态控制以及姿态传递。这里没有那么复杂的结构,就简化为0。
mesh则表示场景节点中的几何对象。
2.2.2.2. 网格
"meshes": [
{
"primitives": [
{
"attributes": {
"POSITION": 1,
"TEXCOORD_0": 2
},
"indices": 0,
"material": 0
}
]
}
],mesh对象包含了一个primitive数组对象。primitive表达的是一个图元,描述每个网格是怎样的几何图形。其attributes对象表达了图元顶点的属性。这里的POSITION属性表示顶点的位置信息,属性值1表示访问器对象accessors数组的索引;TEXCOORD_0表示顶点的纹理位置信息,属性值2表示访问器对象accessors数组的索引。
indices属性表示图元顶点数据是通过索引来描述的,其值3表示访问器对象accessors数组的索引。
而material则表示图元用到了材质,在materials节点中可以找到其具体的描述。
2.2.2.3. 缓冲,缓冲视图和访问器
"buffers": [
{
"uri": "new.bin",
"byteLength": 595236
}
],
"bufferViews": [
{
"buffer": 0,
"byteOffset": 374400,
"byteLength": 220836,
"target": 34963
},
{
"buffer": 0,
"byteStride": 20,
"byteOffset": 0,
"byteLength": 374400,
"target": 34962
}
],
"accessors": [
{
"bufferView": 0,
"byteOffset": 0,
"componentType": 5123,
"count": 110418,
"type": "SCALAR",
"max": [
18719
],
"min": [
0
]
},
{
"bufferView": 1,
"byteOffset": 0,
"componentType": 5126,
"count": 18720,
"type": "VEC3",
"max": [
770,
0.0,
1261.151611328125
],
"min": [
0.0,
-2390,
733.5555419921875
]
},
{
"bufferView": 1,
"byteOffset": 12,
"componentType": 5126,
"count": 18720,
"type": "VEC2",
"max": [
1,
1
],
"min": [
0,
0
]
}
]这里详细描述了上面提到的访问器对象accessors。之所以定义这个属性对象,是因为顶点数据信息被直接保存为二进制buffer了,需要去区分描述buffer哪些是位置信息,哪些是纹理坐标信息,哪些是索引信息。
buffers对象就是顶点数据的二进制buffer,url表示被保存为外部的二进制文件new.bin,byteLength表示其长度为595236,这个文件在导入的时候会被读取成JS的ArrayBuffer对象。
bufferViews对象将buffers分成两个视图:前374400个字节表达的是顶点数据,步长byteStride为20个表示每20个字节的数据表达一个顶点,target为34962表示的就是ARRAY_BUFFER;而从374400开始的220836个字节表示的是顶点索引的数据,target为34963表示的就是ELEMENT_ARRAY_BUFFER。
accessors对象则进一步描述了顶点数据的组织。
- 属性bufferView表示的就是前面bufferViews对象的索引值。
- byteOffset表示数据从那个字节开始;componentType表示保存的数据类型,5123表示为UNSIGNED_SHORT型,占用2个字节;而5126表示FLOAT信号,占用4个字节。
- count表示数据的个数。
- type表示数据的类型,可以为标量SCALAR,也可以为矢量"VEC2"、"VEC3"等,甚至可以为矩阵"MAT3"等。
- min,max则表示每个值得最大最小值,填写正确的范围,有助于浏览操作。
通过以上属性值,就能够正确区分描述顶点数据信息了。注意顶点数据的bufferViews对象在accessors对象被进一步划分视图,分别描述了位置信息和纹理坐标信息:bufferViews对象的步长byteStride被设置为20,accessors对象的偏移量byteOffset分别设置为0和12,说明二进制bin中的组织的结构为:
位置X坐标 位置Y坐标 位置Z坐标 纹理S坐标 纹理T坐标
位置X坐标 位置Y坐标 位置Z坐标 纹理S坐标 纹理T坐标
位置X坐标 位置Y坐标 位置Z坐标 纹理S坐标 纹理T坐标
...
当然,二进制bin中是没有空格和回车的,这里只是为了方便好看。
2.2.2.4. 纹理材质
"materials": [
{
"pbrMetallicRoughness": {
"baseColorTexture": {
"index": 0
}
}
}
],
"textures": [
{
"sampler": 0,
"source": 0
}
],
"images": [
{
"uri": "tex.jpg"
}
],
"samplers": [
{
"magFilter": 9729,
"minFilter": 9987,
"wrapS": 33648,
"wrapT": 33648
}
],在primitives对象的material的属性中,指向的就是这个materials节点的索引值。materials对象又指向了纹理对象textures,textures对象通过索引引用了一个sampler对象和一个image对象。image对象包含了一个uri,引用了一个外部图像文件。samplers是一个采样器,用于设置纹理具体的采样方式,其设置参数与WebGL中设置纹理的方式向对应。
2.2.3. 初始化顶点缓冲区
读取后的数据可以直接交给initVertexBuffers()初始化顶点缓冲区,具体的实现代码如下:
//
function initVertexBuffers(gl, gltfObj, binBuf) {
//获取顶点数据位置信息
var positionAccessorId = gltfObj.meshes[0].primitives[0].attributes.POSITION;
if (gltfObj.accessors[positionAccessorId].componentType != 5126) {
return 0;
}
var positionBufferViewId = gltfObj.accessors[positionAccessorId].bufferView;
var verticesColors = new Float32Array(binBuf, gltfObj.bufferViews[positionBufferViewId].byteOffset, gltfObj.bufferViews[positionBufferViewId].byteLength / Float32Array.BYTES_PER_ELEMENT);
gltfObj.cuboid = new Cuboid(gltfObj.accessors[positionAccessorId].min[0], gltfObj.accessors[positionAccessorId].max[0], gltfObj.accessors[positionAccessorId].min[1], gltfObj.accessors[positionAccessorId].max[1], gltfObj.accessors[positionAccessorId].min[2], gltfObj.accessors[positionAccessorId].max[2]);
// 创建缓冲区对象
var vertexColorBuffer = gl.createBuffer();
var indexBuffer = gl.createBuffer();
if (!vertexColorBuffer || !indexBuffer) {
console.log('Failed to create the buffer object');
return -1;
}
// 将缓冲区对象绑定到目标
gl.bindBuffer(gl.ARRAY_BUFFER, vertexColorBuffer);
// 向缓冲区对象写入数据
gl.bufferData(gl.ARRAY_BUFFER, verticesColors, gl.STATIC_DRAW);
//获取着色器中attribute变量a_Position的地址
var a_Position = gl.getAttribLocation(gl.program, 'a_Position');
if (a_Position < 0) {
console.log('Failed to get the storage location of a_Position');
return -1;
}
// 将缓冲区对象分配给a_Position变量
gl.vertexAttribPointer(a_Position, 3, gl.FLOAT, false, gltfObj.bufferViews[positionBufferViewId].byteStride, gltfObj.accessors[positionAccessorId].byteOffset);
// 连接a_Position变量与分配给它的缓冲区对象
gl.enableVertexAttribArray(a_Position);
//获取顶点数据纹理信息
var txtCoordAccessorId = gltfObj.meshes[0].primitives[0].attributes.TEXCOORD_0;
if (gltfObj.accessors[txtCoordAccessorId].componentType != 5126) {
return 0;
}
var txtCoordBufferViewId = gltfObj.accessors[txtCoordAccessorId].bufferView;
//获取着色器中attribute变量a_TxtCoord的地址
var a_TexCoord = gl.getAttribLocation(gl.program, 'a_TexCoord');
if (a_TexCoord < 0) {
console.log('Failed to get the storage location of a_TexCoord');
return -1;
}
// 将缓冲区对象分配给a_Color变量
gl.vertexAttribPointer(a_TexCoord, 2, gl.FLOAT, false, gltfObj.bufferViews[txtCoordBufferViewId].byteStride, gltfObj.accessors[txtCoordAccessorId].byteOffset);
// 连接a_Color变量与分配给它的缓冲区对象
gl.enableVertexAttribArray(a_TexCoord);
//获取顶点数据索引信息
var indicesAccessorId = gltfObj.meshes[0].primitives[0].indices;
var indicesBufferViewId = gltfObj.accessors[indicesAccessorId].bufferView;
var indices = new Uint16Array(binBuf, gltfObj.bufferViews[indicesBufferViewId].byteOffset, gltfObj.bufferViews[indicesBufferViewId].byteLength / Uint16Array.BYTES_PER_ELEMENT);
// 将顶点索引写入到缓冲区对象
gl.bindBuffer(gl.ELEMENT_ARRAY_BUFFER, indexBuffer);
gl.bufferData(gl.ELEMENT_ARRAY_BUFFER, indices, gl.STATIC_DRAW);
return indices.length;
}这段代码的原理非常简单,读取的glTF被直接解析为JSON后,通过primitives属性找到顶点位置坐标和顶点纹理坐标的访问器对象accessors,继而找到缓冲区buffer和缓冲区视图bufferView。由于缓冲区数据文件new.bin已经被读取成ArrayBuffer,可以将这个ArrayBuffer分成两个视图[6],一组视图为Float32Array类型的顶点数组,一组视图为Uint16Array类型的顶点数组索引。其中,顶点数组可以通过 gl.vertexAttribPointer()函数做进一步分配,分别给着色器分配位置变量和纹理坐标变量(可以复习一下《WebGL简易教程(三):绘制一个三角形(缓冲区对象)》创建缓冲区对象的五个步骤)。
2.2.4. 其他
程序其他的步骤基本上没有变化,由于数据读取后JS的Image对象已经生成,仍然按照以前的方式根据Image对象生成纹理对象。着色器部分也非常简单:
// 顶点着色器程序
var VSHADER_SOURCE =
'attribute vec4 a_Position;\n' + //位置
'attribute vec2 a_TexCoord;\n' + //颜色
'varying vec2 v_TexCoord;\n' + //纹理坐标
'uniform mat4 u_MvpMatrix;\n' +
'void main() {\n' +
' gl_Position = u_MvpMatrix * a_Position;\n' + // 设置顶点坐标
' v_TexCoord = a_TexCoord;\n' + //纹理坐标
'}\n';
// 片元着色器程序
var FSHADER_SOURCE =
'precision mediump float;\n' +
'uniform sampler2D u_Sampler;\n' +
'varying vec2 v_TexCoord;\n' + //纹理坐标
'void main() {\n' +
' gl_FragColor = texture2D(u_Sampler, v_TexCoord);\n' +
'}\n';纹理坐标传入顶点着色器再传入片元着色器,通过纹理对象插值得到片元最终值。
3. 结果
从以上解析过程可以看到,glTF的格式设计确实非常精妙,读取的数据能够直接为WebGL所用,既节省了空间又省略了一些预处理的过程,值得进一步深入研究。
打开HTML页面,导入new.gltf、new.bin、tex.jpg,显示的效果如下:

这个例子是通过JS的FileReader来处理数据,所以不需要设置浏览器跨域。
4. 参考
1.《WebGL编程指南》
2.glTF格式详解(目录)
3.glTF Tutorial
4.前端H5中JS用FileReader对象读取blob对象二进制数据,文件传输
5.gltf2.0规范
6.JavaScript 之 ArrayBuffer
5. 相关
代码和数据地址
上一篇
目录
下一篇
加载全部内容