Python爬虫英雄联盟 Python爬虫获取op.gg英雄联盟英雄对位胜率的源码
qq_46480884 人气:0想了解Python爬虫获取op.gg英雄联盟英雄对位胜率的源码的相关内容吗,qq_46480884在本文为您仔细讲解Python爬虫英雄联盟的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python爬虫英雄联盟,Python爬虫op.gg,下面大家一起来学习吧。
通过第三方BeautifulSoup库来爬取op.gg网页静态数据
主要思路
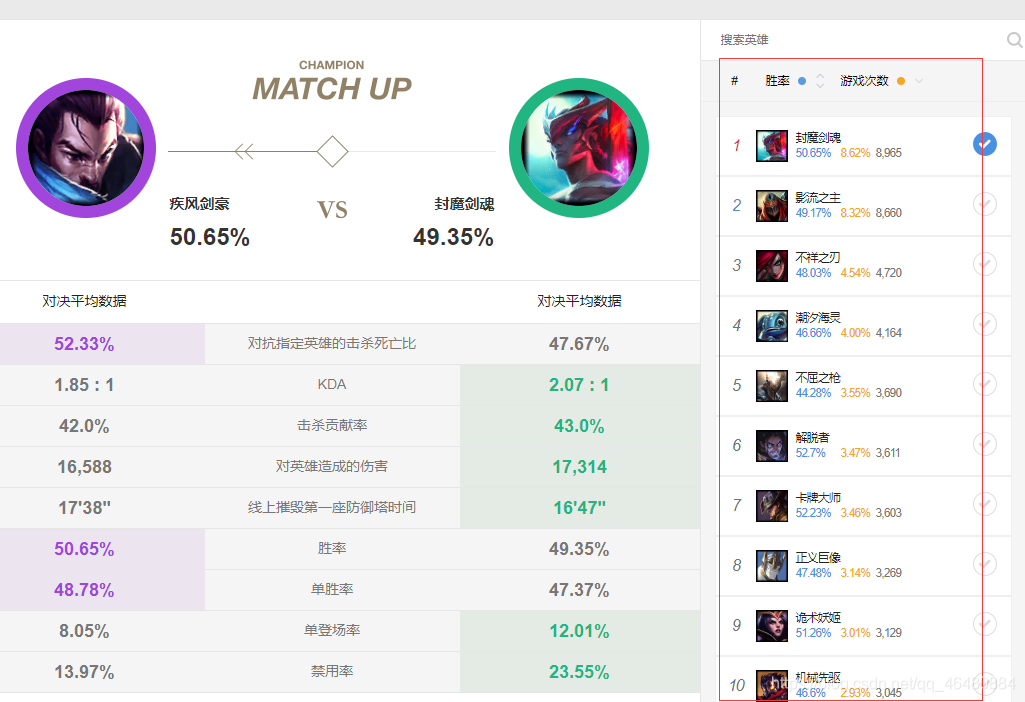
网站以出场率高低排名,并且列出对位胜率,在高出场率的前提下,胜率有很大的参考意义,在counter位很有帮助
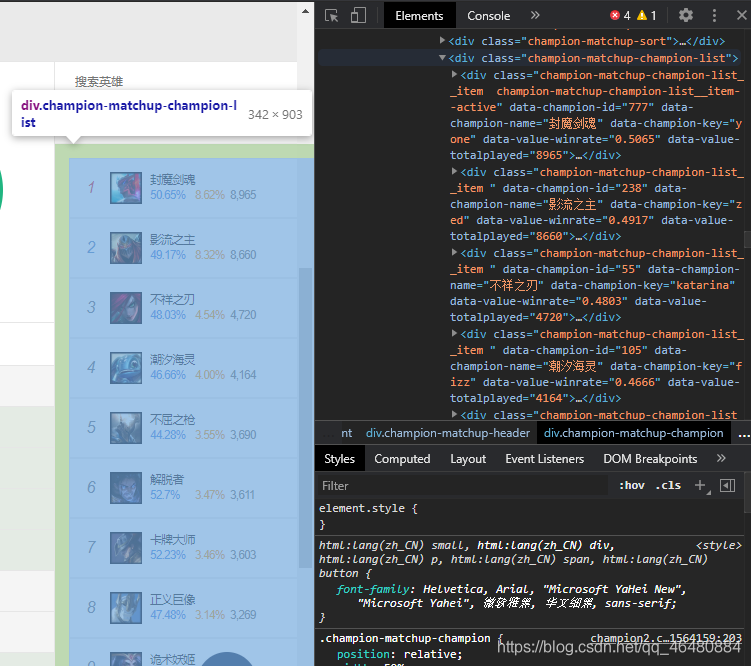
通过开发者工具找到对应部位源码,发现数据就在源码中,证明这是一个静态数据,确定使用BeautifulSoup库。
源码
import requests
from bs4 import BeautifulSoup
championname={'阿卡丽 ':'akali','牛头':'alistar','阿木木':'amumu','冰鸟':'anivia','安妮':'annie','艾希':'ashe','机器人':'blitzcrank','火男':'brand','女警':'caitlyn',
'蛇女':'cassiopeia','大虫子':'chogath','飞机':'corki','诺手':'darius','皎月':'diana','蒙多':'drmundo','德莱文':'delevin','蜘蛛':'elise',
'寡妇':'evelynn','ez':'ezreal','稻草人':'fiddlesticks','剑姬':'fiora','鱼人':'fizz','加里奥':'galio','船长':'gangplank','盖伦':'garen',
'酒桶':'gragas','人马':'hecarim','大头':'heimerdinger','刀妹':'irelia','凤女':'janna','皇子':'jarvaniv','贾克斯':'jax','杰斯':'jayce','卡尔玛':'karma',
'死歌':'karthus','卡萨丁':'kassadin','卡特':'katarina','天使':'kayle','凯南':'kennen','螳螂':'khazix','大嘴':'kogmaw','妖姬':'leblanc','盲僧':'leesin','女坦':'Leona','露露':'lulu','拉克丝':'Lux',
'石头人':'Malphite','马尔扎哈':'Malzahar','大树':'Maokai','剑圣':'Yi','女枪':'MissFortune','猴子':'Monkeyking','铁男':'Mordekaiser','莫甘娜':'Morgana'
,'娜美':'Nami','狗头':'Nasus','泰坦':'Nautilus','豹女':'Nidalee','梦魇':'Nocturne','雪人':'Nunu','奥拉夫':'Olaf','发条':'Orianna','潘森':'Pantheon','波比':'Poopy','龙龟':'Rammus','鳄鱼':'Renekton','狮子狗':'Rengar',
'瑞文':'Rivan','兰博':'Rumble','瑞兹':'Ryze','猪女':'Sejuani','小丑':'Shaco','慎':'Shen','龙女':'Shyvana','炼金':'Singed','塞恩':'Sion','希维尔':'Sivir','蝎子':'Skarner','琴女':'Sona','奶妈':'Soraka','乌鸦':'Swain','辛德拉':'Syndra'
,'男刀':'Talon','宝石':'Taric','提莫':'Teemo','锤石':'Thresh','小炮':'Tristana','巨魔':'Trundle','蛮王':'Tryndamere','卡牌':'TwistedFate','老鼠':'Twitch','乌迪尔':'Udyr','厄加特':'Urgot','维鲁斯':'Varus','薇恩':'Vayne',
'小法':'Veigar','蔚':'Vi','维克托':'Viktor','吸血鬼':'Vladimir','狗熊':'Volibear','狼人':'Warwick','泽拉斯':'Xerath','赵信':'XinZhao','掘墓':'Yorick','劫':'Zed','炸弹人':'Ziggs','时光':'Zilean','婕拉':'Zyra','佐伊':'zoe','永恩':'yone','萨米拉':'samira','亚索':'yasuo',
'塞拉斯':'sylas','卢锡安':'lucian','艾克':'ekko','阿狸':'ahri','瑟提':'sett','奇亚娜':'qiyana','龙王':'aurelionsol','克烈':'kled','妮蔻':'neeko'
}
position_all = {'top':'top','jun':'jungle','mid':'mid','ad':'bot','sup':'support'}
#由于网站反爬虫机制,使用请求通来伪装成浏览器,否则会被检测为爬虫,爬取数据失败
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'}
name_input = input('输入名字:')
myname = championname[name_input]
myposition = input('输入位置:')
position = position_all[myposition]
print('正在查询,请稍等~~~')
#向url发出请求,将请求头传入,返回结果保留在res中,res为response对象
res = requests.get('http://www.op.gg/champion/{}/statistics/{}/matchup'.format(myname,position),headers=headers)
#res.text是要解析的网页源代码,html。parser是python的解析器
soup = BeautifulSoup(res.text,'html.parser')
#find方法返回tag对象,find_all返回有tag对象组成的列表,tag是BeautifSoup中的对象
#查找class属性为champion-matchup-champion-list__item的div标签,组成名为items的列表
items = soup.find_all('div',class_='champion-matchup-champion-list__item')
print('英雄 胜率')
for i in items:
#div中的data-champion-name属性值为英雄名字
name = i['data-champion-name']
#div属性中的data-value-winrate属性值为查找的英雄胜率,这里转换为供选择的英雄胜率
rate = 1-float(i['data-value-winrate'])
print(name,'{}%'.format(round(rate*100,2)))
由于网址为英文,英雄英文名字个别十分难记难拼,所以我在字典中以中文名或者耳熟能详的外号为key,以url中英雄英文名为value,进行输入转换。
位置使用top,jun,mid,ad,sup方便输入。
加载全部内容