数学基础系列(六)----特征值分解和奇异值分解(SVD)
|旧市拾荒| 人气:0一、介绍
特征值和奇异值在大部分人的印象中,往往是停留在纯粹的数学计算中。而且线性代数或者矩阵论里面,也很少讲任何跟特征值与奇异值有关的应用背景。
奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。就像是描述一个人一样,给别人描述说这个人长得浓眉大眼,方脸,络腮胡,而且带个黑框的眼镜,这样寥寥的几个特征,就让别人脑海里面就有一个较为清楚的认识,实际上,人脸上的特征是有着无数种的,之所以能这么描述,是因为人天生就有着非常好的抽取重要特征的能力,让机器学会抽取重要的特征,SVD是一个重要的方法。
在机器学习领域,有相当多的应用与奇异值都可以扯上关系,比如做feature reduction的PCA,做数据压缩(以图像压缩为代表)的算法,还有做搜索引擎语义层次检索的LSI(Latent Semantic Indexing)
特征值分解和奇异值分解在机器学习领域都是属于满地可见的方法。两者有着很紧密的关系,接下来会谈到特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。
首先来看看向量的表示及基变换
向量可以表示为(3,2),实际上表示线性组合:$x(1,0)^{T}+y(0,1)^{T}$

基:(1,0)和(0,1)叫做二维空间中的一组基
基变换:基是正交的(即内积为0,或直观说相互垂直),要求:基之间线性无关

基变换:数据与一个基做内积运算,结果作为第一个新的坐标分量,然后与第二个基做内积运算,结果作为第二个新坐标的分量
数据(3,2)映射到基中坐标:$\begin{pmatrix}\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}}\\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}}\end{pmatrix}\begin{pmatrix}3\\ 2\end{pmatrix}=\begin{pmatrix}\frac{5}{\sqrt{2}}\\ -\frac{1}{\sqrt{2}}\end{pmatrix}$
二、特征值分解
在前面一篇博客详细的理解了特征值和特征向量。
如果说一个向量v是方阵A的特征向量,那么一定可以表示成下面的形式子 : Av = λv
这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:A = Q∑Q-1
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。
当矩阵是$N\times N$的方阵且有N个线性无关的特征向量时就可以来玩啦
反过头来看看之前特征值分解的式子,分解得到的Σ矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。
总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
三、奇异值分解(SVD)
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,
比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?
奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法: A = UΣVT
特征值分解不挺好的嘛,但是它被限制住了,如果我的矩阵形状变了呢?
但是问题来了,如果M和N都很大且M不等N呢?
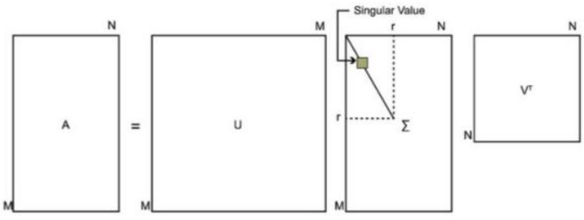
照样按照特征值的大小来进行筛选,一般取前10%的特征(甚至更少)的和就占到了总体的99%了。
取前K个来看看吧

简单推导一下
在这里顺便解释一下为什么要进行推导,在机器学习领域、深度学习领域,具体的数学推导其实不是那么重要,重要的是要知道这个东西到底是什么意思,不一定需要把数学原理搞得十分清楚。在这里只是简单的推导一下而已。
前提:对于一个二维矩阵M可以找到一组标准正交基v1和v2是的Mv1和Mv2是正交的。
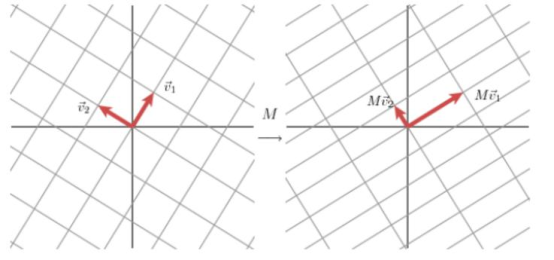
使用另一组正交基u1和u2来表示Mv1和Mv2的方向,其长度分别为:$|MV_{1}|=\sigma _{1},|MV_{2}|=\sigma _{2}$。可得:$\begin{matrix}MV_{1}=\sigma _{1}u_{1}\\ MV_{2}=\sigma _{2}u_{2}\end{matrix}$
对于向量X在这组基中的表示:$x=(v_{1}\cdot x)v_{1}+(v_{2}\cdot x)v_{2}$,(点积表示投影的长度,可转换成行向量乘列向量$v\cdot x=v^{T}x$
可得:$\begin{matrix}Mx=(v_{1}\cdot x)Mv_{1}+(v_{2}\cdot x)Mv_{2}\\ Mx=(v_{1}\cdot x)\sigma _{1}u_{1}+(v_{2}\cdot x)\sigma _{2}u_{2}\end{matrix}$
从而:$\begin{matrix}Mx=u_{1}\sigma _{1}{v_{1}}^{T}x+u_{2}\sigma _{2}{v_{2}}^{T}x\\ M=u_{1}\sigma _{1}{v_{1}}^{T}+u_{2}\sigma _{2}{v_{2}}^{T}\end{matrix}$
化简得:$M=U\sum V^{T}$
奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。
参考资料:
1、https://www.cnblogs.com/jian-gao/p/10781649.html
2、https://www.zhihu.com/collection/143068858?page=1
3、https://zhuanlan.zhihu.com/p/36546367
4、https://www.cnblogs.comhttps://img.qb5200.com/download-x/dynmi/p/11070994.html
5、https://www.jianshu.com/p/bcd196497d94
6、https://zhuanlan.zhihu.com/p/32600280
这篇博客写的很差,里面包含自己理解的内容很少,SVD很难理解,包括我现在也是一知半解,现在记录下来,后面如果有机会用到了,再来回过头来看看,争取温故而知新。
加载全部内容