python自动签到脚本 Python 实现 T00ls 自动签到脚本代码(邮件+钉钉通知)
国光 人气:0T00ls 每日签到是可以获取 TuBi 的,由于常常忘记签到,导致损失了很多 TuBi 。于是在 T00ls 论坛搜索了一下,发现有不少大佬都写了自己的签到脚本,签到功能实现、定时任务执行以及签到提醒的方式多种多样,好羡慕啊。所以这里国光也尝试借鉴前辈们的脚本,尝试整合一个自己的自动签到脚本,因为国光有自己的服务器,所以打算使用 Linux 下的 crontab 来定时执行任务,提醒的话使用钉钉和邮件提醒基本上可以满足我的使用需求了,话不多说,下面开始脚本的编写吧。
基础签到
写代码功能得慢慢添加上去,首先得实现一个最基础的登录并签到功能,后续再添加邮件以及钉钉提醒等功能。
因为脚本功能比较简单,就直接将对应的功能封装成函数了。对应的函数都按照正规开发那样给了详细的注释和说明,话不多说直接看下面的代码吧:
import json
import requests
username = '国光' # 帐号
password = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 密码MD5 32位(小写)
question_num = 5 # 安全提问 参考下面
question_answer = 'xxx' # 安全提问答案
# 0 = 没有安全提问
# 1 = 母亲的名字
# 2 = 爷爷的名字
# 3 = 父亲出生的城市
# 4 = 您其中一位老师的名字
# 5 = 您个人计算机的型号
# 6 = 您最喜欢的餐馆名称
# 7 = 驾驶执照的最后四位数字
def t00ls_login(u_name, u_pass, q_num, q_ans):
"""
t00ls 登录函数
:param u_name: 用户名
:param u_pass: 密码的 md5 值 32 位小写
:param q_num: 安全提问类型
:param q_ans: 安全提问答案
:return: 签到要用的 hash 和 登录后的 Cookies
"""
login_data = {
'action': 'login',
'username': u_name,
'password': u_pass,
'questionid': q_num,
'answer': q_ans
}
response_login = requests.post('https://www.t00ls.net/login.json', data=login_data)
response_login_json = json.loads(response_login.text)
if response_login_json['status'] != 'success':
return None
else:
print('用户:', username, '登入成功!')
formhash = response_login_json['formhash']
t00ls_cookies = response_login.cookies
return formhash, t00ls_cookies
def t00ls_sign(t00ls_hash, t00ls_cookies):
"""
t00ls 签到函数
:param t00ls_hash: 签到要用的 hash
:param t00ls_cookies: 登录后的 Cookies
:return: 签到后的 JSON 数据
"""
sign_data = {
'formhash': t00ls_hash,
'signsubmit': "true"
}
response_sign = requests.post('https://www.t00ls.net/ajax-sign.json', data=sign_data, cookies=t00ls_cookies)
return json.loads(response_sign.text)
def main():
response_login = t00ls_login(username, password, question_num, question_answer)
if response_login:
response_sign = t00ls_sign(response_login[0], response_login[1])
if response_sign['status'] == 'success':
print('签到成功')
elif response_sign['message'] == 'alreadysign':
print('今日已签到')
else:
print('出现玄学问题了 签到失败')
else:
print('登入失败 请检查输入资料是否正确')
if __name__ == '__main__':
main()
值得一提的是,T00ls 得连续 2 天签到才会有 TuBi 奖励。
查询域名奖励
T00ls 在线工具里面有域名查询功能,每天查询域名的话也会获得 1 个 TuBi 的奖励,这样算下来每天可获得 2 个 TuBi 的奖励,1个月就是 60 TuBi 的奖励,1 年下来就是 720 TuBi 的奖励……. 瞬间感觉自己变得很壕了
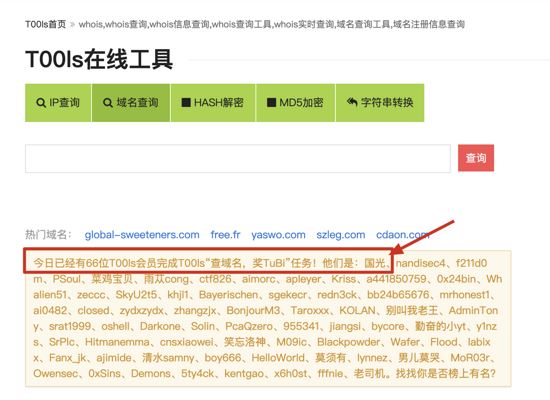
然后去 TuBi 日志里面是可以看到查询域名的记录的:

但是这个域名查询有要求的,咨询了下 T00ls 的 MoR03r 大佬:
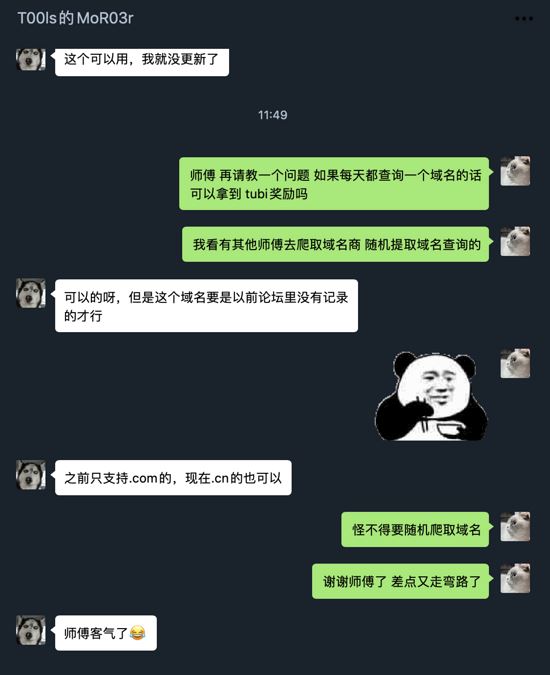
所以我们需要每天查询一个论坛里面没有记录的域名才可以,所以得多写一个流程了。下面直接贴查询域名的代码吧:
def t00ls_domain(t00ls_hash, t00ls_cookies):
# 使用站长之家查询今天注册的域名
start_time = time.time()
china_url = 'https://whois.chinaz.com/suffix'
search_data = 'ix=.com&suffix=.cn&c_suffix=&time=1&startDay=&endDay='
req_headers['Content-Type'] = 'application/x-www-form-urlencoded'
response_domains = requests.post(url=china_url, headers=req_headers, data=search_data, timeout=10)
soup = BeautifulSoup(response_domains.text, 'html.parser')
# Bs4 解析器 简单规则过滤一下放入到 domains 的列表中
domains = []
for i in soup.select('.listOther a'):
if '.' in i.string and '*' not in i.string:
domains.append(i.string)
domain = random.sample(domains, 1)[0] # 随机抽取一个 幸运儿
end_time = time.time()
print(f'站长之家随机找域名耗时: {end_time - start_time:.4f}秒')
start_time = time.time()
query_url = 'https://www.t00ls.net/domain.html'
query_data = f'domain={domain}&formhash={t00ls_hash}&querydomainsubmit=%E6%9F%A5%E8%AF%A2'
query_status = False
# 如果 t00ls 查询没有成功的话 就一直查询
while not query_status:
domain = random.sample(domains, 1)[0] # 随机抽取一个 幸运儿
query_data = f'domain={domain}&formhash={t00ls_hash}&querydomainsubmit=%E6%9F%A5%E8%AF%A2'
try:
response_query = requests.post(url=query_url, headers=req_headers, data=query_data, cookies=t00ls_cookies)
except Exception as e:
pass
if domain in response_query.text:
print('t00ls 查询域名成功')
response_tb = requests.get('https://www.t00ls.net/members-tubilog.json', cookies=t00ls_cookies)
if domain in response_tb.text:
print('查询域名 TuBi + 1')
query_status = True
else:
print('糟糕 域名查询成功 但是 TuBi 没有增加 可能域名重复了')
print('随机延时 5-10 秒,继续查询...')
time.sleep(random.randint(5, 10))
else:
print(f'查询失败?失败的域名是: {domain}')
print('随机延时 5-10 秒,继续查询...')
time.sleep(random.randint(5, 10))
end_time = time.time()
print(f't00ls 域名查询耗时: {end_time - start_time:.4f}秒')
域名查询使用了站长之家的域名服务,查询服务速度还算是可以的,但是 t00ls 查询域名服务不是很稳定,所以国光我这里写了 while 循环一直查询,当然查询失败了是需要延时的,国光随机延时了 5-10 秒 用来减轻 t00ls 服务器的负担,大家脚本拿去用的话,建议依然保持这个延时,做一个素质良好的爬虫。
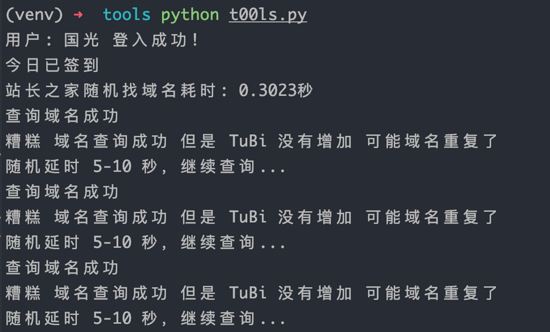
代码中基本上考虑到了各种情况,包括域名查询超时以及查询域名以及重复等问题。
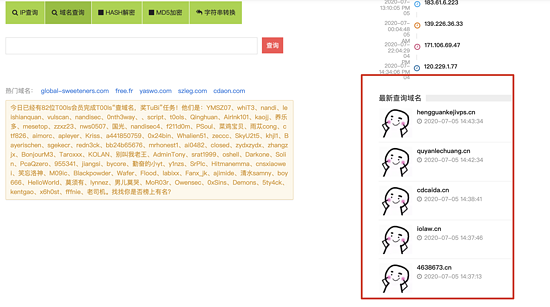
查询域名功能写完了感觉溜了溜了,一直在查询,万一被拉黑名单就尴尬了,下面来研究如何接入钉钉吧。
钉钉接入
酷公司用钉钉,很巧我们公司也用钉钉,那么现在尝试将脚本接入钉钉提醒服务。
机器人只能在群聊中添加,所以在之前你得有一个自己的一个用于接收机器人通知的群。如果没有群怎么办?手动端可以通过「发起群聊」-「选人建群」-「面对面建群」创建一个自己的群,哪怕群成员只有你 1 个人也是 OK 的。
在钉钉的「机器人管理」中我们可以添加一个自定义机器人,通过 Webhook 接入也比较方便:
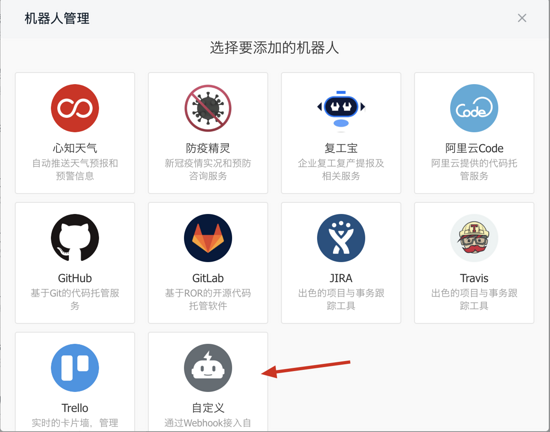
然后将机器人添加到之前新建的群中,可以自定义关键字(自定义关键词后 传入 webhook 的内容必须有关键词 否则无法传入信息):
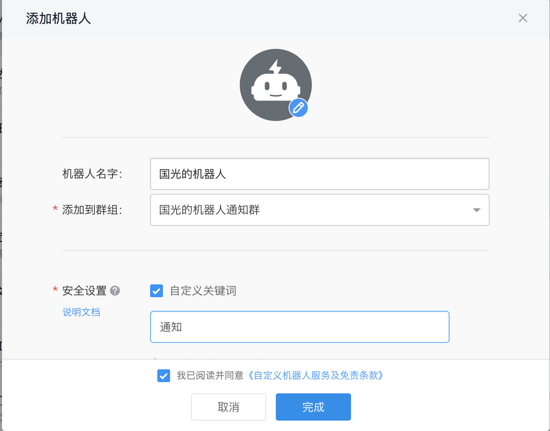
接着就会生成一串 token 地址,复制出来以备用:
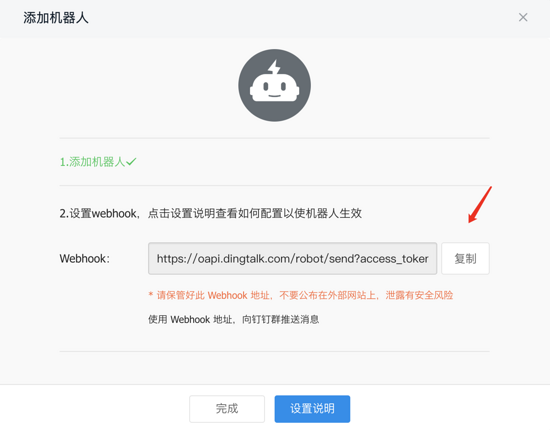
详细的钉钉自定义机器人文档可参考: 钉钉开发文档
国光这里就打算用最基础的 text 文本类型:
{
"msgtype": "text",
"text": {
"content": "我就是我, 是不一样的烟火"
},
"at": {
"atMobiles": [
"177******30",
],
"isAtAll": false
}
}
当然也可以不需要用 @ 功能,下面是国光写的最基础的 Demo:
import json
import requests
webhook = 'https://oapi.dingtalk.com/robot/send?access_token={你的机器人的token}'
dd_headers = {
"Content-Type": "application/json",
"Charset": "UTF-8"
}
dd_message = {
"msgtype": "text",
"text": {
"content": '通知:Hello World'
}
}
r = requests.post(url=webhook, headers=dd_headers, data=json.dumps(dd_message))
print(r.text)
最后的效果如下:

邮件接入
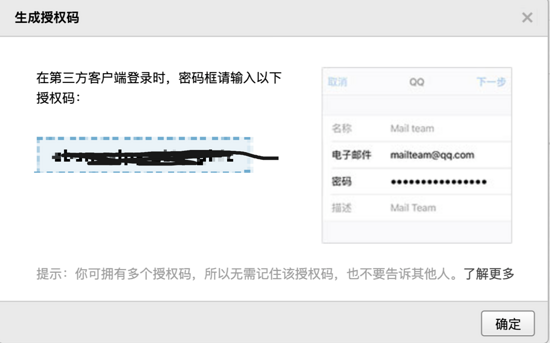
邮件接入这里选取了 QQ 邮箱作为案例,首先需要开启 POP3/SMTP 服务,然后点击生成授权码:

生成的这个授权码实际上就起到密码的作用,所以不要随便外泄:
下面是完整的Python 调用邮件的 Demo 代码,填写对应的信息之后可以直接运行:
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
sender = 'admin@sqlsec.com' # 发件人邮箱账号
sender_pass = '***********' # 发件人邮箱密码
receiver = 'admin@sqlsec.com' # 收件人邮箱账号
content = '邮件正文内容'
try:
msg = MIMEText(content, 'plain', 'utf-8')
msg['From'] = formataddr(["T00ls 签到提醒", sender]) # 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['To'] = formataddr(["", receiver]) # 括号里的对应收件人邮箱昵称、收件人邮箱账号
msg['Subject'] = "Python 发送邮件测试" # 邮件的主题,也可以说是标题
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
server.login(sender, sender_pass) # 括号中对应的是发件人邮箱账号、邮箱密码
server.sendmail(sender, [receiver, ], msg.as_string()) # 括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.quit() # 关闭连接
print("邮件发送成功")
except Exception:
print("邮件发送失败")
功能整合
项目地址: https://github.com/sqlsec/TuBi
我们实现了钉钉和邮件的 Demo 之后,现在尝试来进行最终的功能整合吧,完整的代码如下:
import time
import json
import random
import smtplib
import requests
from bs4 import BeautifulSoup
from email.mime.text import MIMEText
from email.utils import formataddr
# t00ls 账号配置
username = '国光' # 帐号
password = '***' # 密码MD5 32位(小写)
question_num = 7 # 安全提问 参考下面
question_answer = '***' # 安全提问答案
# 0 = 没有安全提问
# 1 = 母亲的名字
# 2 = 爷爷的名字
# 3 = 父亲出生的城市
# 4 = 您其中一位老师的名字
# 5 = 您个人计算机的型号
# 6 = 您最喜欢的餐馆名称
# 7 = 驾驶执照的最后四位数字
# 选择提醒方式
notice = 2 # 0 = 钉钉 1 = 邮件 2 = 我全都要
# 如果选择钉钉通知的话 请配置下方信息
webhook = 'https://oapi.dingtalk.com/robot/send?access_token=***' # 钉钉机器人的 webhook
# 如果选择邮件通知的话 请配置下方信息
sender = 'admin@sqlsec.com' # 发件人邮箱账号
sender_pass = '***********' # 发件人邮箱密码
receiver = 'admin@sqlsec.com' # 收件人邮箱账号
req_headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Safari/537.36'
}
def t00ls_login(u_name, u_pass, q_num, q_ans):
"""
t00ls 登录函数
:param u_name: 用户名
:param u_pass: 密码的 md5 值 32 位小写
:param q_num: 安全提问类型
:param q_ans: 安全提问答案
:return: 签到要用的 hash 和 登录后的 Cookies
"""
login_data = {
'action': 'login',
'username': u_name,
'password': u_pass,
'questionid': q_num,
'answer': q_ans
}
response_login = requests.post('https://www.t00ls.net/login.json', data=login_data, headers=req_headers)
response_login_json = json.loads(response_login.text)
if response_login_json['status'] != 'success':
return None
else:
print('用户:', username, '登入成功!')
formhash = response_login_json['formhash']
t00ls_cookies = response_login.cookies
return formhash, t00ls_cookies
def t00ls_sign(t00ls_hash, t00ls_cookies):
"""
t00ls 签到函数
:param t00ls_hash: 签到要用的 hash
:param t00ls_cookies: 登录后的 Cookies
:return: 签到后的 JSON 数据
"""
sign_data = {
'formhash': t00ls_hash,
'signsubmit': "true"
}
response_sign = requests.post('https://www.t00ls.net/ajax-sign.json', data=sign_data, cookies=t00ls_cookies,
headers=req_headers)
return json.loads(response_sign.text)
def t00ls_domain(t00ls_hash, t00ls_cookies):
"""
t00ls 域名查询函数
:param t00ls_hash: 签到要用的 hash
:param t00ls_cookies: 登录后的 Cookies
:return: 查询相关的日志信息
"""
content = ''
# 使用站长之家查询今天注册的域名
start_time = time.time()
china_url = 'https://whois.chinaz.com/suffix'
search_data = 'ix=.com&suffix=.cn&c_suffix=&time=1&startDay=&endDay='
req_headers['Content-Type'] = 'application/x-www-form-urlencoded'
response_domains = requests.post(url=china_url, headers=req_headers, data=search_data, timeout=10)
# Bs4 解析器 简单规则过滤一下放入到 domains 的列表中
soup = BeautifulSoup(response_domains.text, 'html.parser')
domains = []
for i in soup.select('.listOther a'):
if '.' in i.string and '*' not in i.string:
domains.append(i.string)
domain = random.sample(domains, 1)[0] # 随机抽取一个 幸运儿
end_time = time.time()
print(f'站长之家随机找域名耗时: {end_time - start_time:.4f}秒')
content += f'\n站长之家随机找域名耗时: {end_time - start_time:.4f}秒\n\n'
start_time = time.time()
query_url = 'https://www.t00ls.net/domain.html'
query_data = f'domain={domain}&formhash={t00ls_hash}&querydomainsubmit=%E6%9F%A5%E8%AF%A2'
query_status = False
query_count = 1 # 查询重试次数
# 如果 t00ls 查询没有成功的话 就一直查询
while not query_status and query_count < 4:
domain = random.sample(domains, 1)[0] # 随机抽取一个 幸运儿
query_data = f'domain={domain}&formhash={t00ls_hash}&querydomainsubmit=%E6%9F%A5%E8%AF%A2'
try:
response_query = requests.post(url=query_url, headers=req_headers, data=query_data, cookies=t00ls_cookies)
except Exception:
pass
if domain in response_query.text:
response_tb = requests.get('https://www.t00ls.net/members-tubilog.json', cookies=t00ls_cookies)
if domain in response_tb.text:
print('查询域名成功 TuBi + 1 \n')
content += '查询域名成功 TuBi + 1\n'
query_status = True
else:
print('糟糕 域名查询成功 但是 TuBi 没有增加 可能域名重复了')
content += '糟糕 域名查询成功 但是 TuBi 没有增加 可能域名重复了\n'
query_count += 1
print(f'随机延时 5-10 秒,继续第 {query_count} 次查询')
content += f'随机延时 5-10 秒,继续第 {query_count} 次查询\n\n'
time.sleep(random.randint(5, 10))
else:
print(f'查询失败?失败的域名是: {domain}')
content += f'查询失败?失败的域名是: {domain}\n'
query_count += 1
print(f'随机延时 5-10 秒,继续第 {query_count} 次查询')
content += f'随机延时 5-10 秒,继续第 {query_count} 次查询\n\n'
time.sleep(random.randint(5, 10))
if query_count == 4:
print('重试查询次数已达上限 终止查询')
content += '重试查询次数已达上限 终止查询\n\n'
end_time = time.time()
print(f't00ls 域名查询耗时: {end_time - start_time:.4f}秒')
content += f't00ls 域名查询耗时: {end_time - start_time:.4f}秒\n'
return content
def dingtalk(content):
"""
钉钉通知函数
:param content: 要通知的内容
:return: none
"""
webhook_url = webhook
dd_headers = {
"Content-Type": "application/json",
"Charset": "UTF-8"
}
dd_message = {
"msgtype": "text",
"text": {
"content": f'T00ls 签到通知\n{content}'
}
}
r = requests.post(url=webhook_url, headers=dd_headers, data=json.dumps(dd_message))
def mail(content):
"""
邮件通知函数
:param content: 要通知的内容
:return: none
"""
msg = MIMEText(content, 'plain', 'utf-8')
msg['From'] = formataddr(["T00ls 签到提醒", sender])
msg['To'] = formataddr(["", receiver])
msg['Subject'] = "T00ls 每日签到提醒"
server = smtplib.SMTP_SSL("smtp.qq.com", 465)
server.login(sender, sender_pass)
server.sendmail(sender, [receiver, ], msg.as_string())
server.quit()
def main():
content = ''
response_login = t00ls_login(username, password, question_num, question_answer)
if response_login:
response_sign = t00ls_sign(response_login[0], response_login[1])
if response_sign['status'] == 'success':
print('签到成功 TuBi + 1')
content += '\n签到成功 TuBi + 1\n'
verbose_log = t00ls_domain(response_login[0], response_login[1])
content += verbose_log
if notice == 0:
try:
dingtalk(content)
except Exception:
print('请检查钉钉配置是否正确')
elif notice == 1:
try:
mail(content)
except Exception:
print('请检查邮件配置是否正确')
else:
try:
dingtalk(content)
except Exception:
print('请检查钉钉配置是否正确')
try:
mail(content)
except Exception:
print('请检查邮件配置是否正确')
elif response_sign['message'] == 'alreadysign':
print('已经签到过啦')
content += '\n已经签到过啦\n'
verbose_log = t00ls_domain(response_login[0], response_login[1])
content += verbose_log
if notice == 0:
try:
dingtalk(content)
except Exception:
print('请检查钉钉配置是否正确')
elif notice == 1:
try:
mail(content)
except Exception:
print('请检查邮件配置是否正确')
else:
try:
dingtalk(content)
except Exception:
print('请检查钉钉配置是否正确')
try:
mail(content)
except Exception:
print('请检查邮件配置是否正确')
else:
print('出现玄学问题了 签到失败')
else:
print('登入失败 请检查输入资料是否正确')
if __name__ == '__main__':
main()
最终整合的代码看上去就不是那么优雅的… 看来还是正如古人说的那样:“有善始者实繁,能克终者盖寡” 啊。
不管这么多了,以后有机会再来改进代码吧,下面直接看效果图:
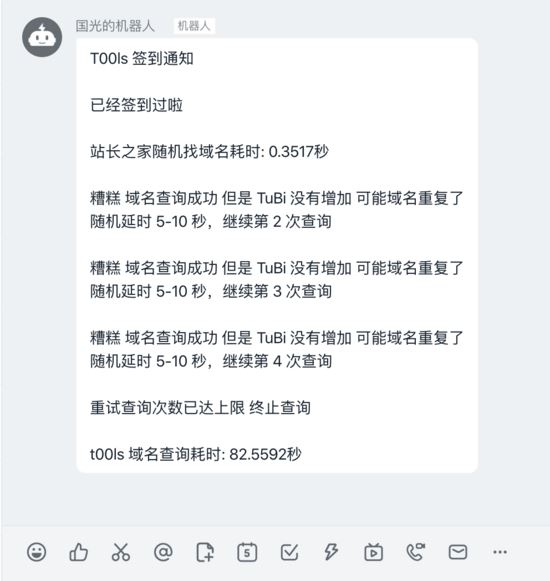
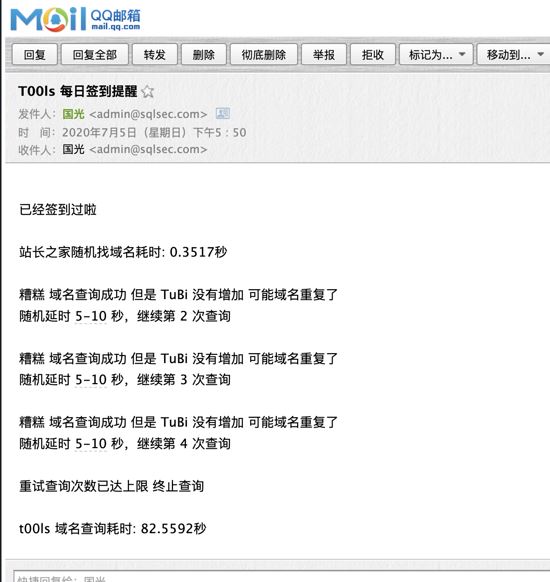
因为国光我今天签到并查询过了,所以图片上看的都是失败的。
定时任务
看了不少网友使用了 腾讯云函数 和 Github 自带的 Actions 来实现自动触发脚本,的确也很不错,感兴趣的朋友也可研究看看。因为国光我有一台 Web 服务器,所以国光我就采用了在 Linux 下使用原生的 crontab 命令实现定时任务了:
# 查看定时任务 crontab -l # 编辑定时任务 crontab -e
编辑定时任务,一行一个任务,国光我本次填写的内容如下:
30 9 * * * /usr/bin/python3 /root/code/t00ls/TuBi.py>&1
表示每天 9:30 自动运行下面的命令:
/usr/bin/python3 /root/code/t00ls/TuBi.py
这样看起来是不是很简单呢,如果语法没有问题的话,会得到如下提示:
crontab: installing new crontab
这表示新建定时任务成功,后面就可以躺着赚去每天的 2 个 TuBi 了。
总结
这个脚本虽然并没有啥难度,但是还是比实用的。钉钉的 webhook 调用也很方便,以后再也其他类似脚本的话就可以少走一些弯路了,总之不论是开发还是安全都有很长的路要走,路漫漫其修远兮,吾将上下而求索,共勉 !
加载全部内容