Keras DenseNet结构 Keras实现DenseNet结构操作
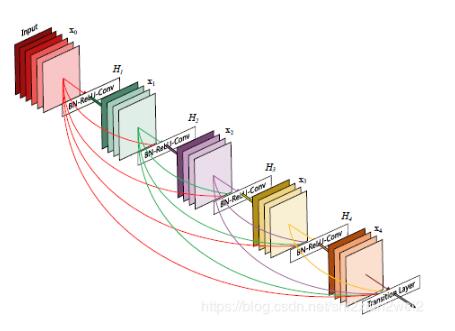
小石学CS 人气:0DenseNet结构在16年由Huang Gao和Liu Zhuang等人提出,并且在CVRP2017中被评为最佳论文。网络的核心结构为如下所示的Dense块,在每一个Dense块中,存在多个Dense层,即下图所示的H1~H4。各Dense层之间彼此均相互连接,即H1的输入为x0,输出为x1,H2的输入即为[x0, x1],输出为x2,依次类推。最终Dense块的输出即为[x0, x1, x2, x3, x4]。这种结构个人感觉非常类似生物学里边的神经元连接方式,应该能够比较有效的提高了网络中特征信息的利用效率。
DenseNet的其他结构就非常类似一般的卷积神经网络结构了,可以参考论文中提供的网路结构图(下图)。但是个人感觉,DenseNet的这种结构应该是存在进一步的优化方法的,比如可能不一定需要在Dense块中对每一个Dense层均直接进行相互连接,来缩小网络的结构;也可能可以在不相邻的Dense块之间通过简单的下采样操作进行连接,进一步提升网络对不同尺度的特征的利用效率。

由于DenseNet的密集连接方式,在构建一个相同容量的网络时其所需的参数数量远小于其之前提出的如resnet等结构。进一步,个人感觉应该可以把Dense块看做对一个有较多参数的卷积层的高效替代。因此,其也可以结合U-Net等网络结构,来进一步优化网络性能,比如单纯的把U-net中的所有卷积层全部换成DenseNet的结构,就可以显著压缩网络大小。
下面基于Keras实现DenseNet-BC结构。首先定义Dense层,根据论文描述构建如下:
def DenseLayer(x, nb_filter, bn_size=4, alpha=0.0, drop_rate=0.2): # Bottleneck layers x = BatchNormalization(axis=3)(x) x = LeakyReLU(alpha=alpha)(x) x = Conv2D(bn_size*nb_filter, (1, 1), strides=(1,1), padding='same')(x) # Composite function x = BatchNormalization(axis=3)(x) x = LeakyReLU(alpha=alpha)(x) x = Conv2D(nb_filter, (3, 3), strides=(1,1), padding='same')(x) if drop_rate: x = Dropout(drop_rate)(x) return x
论文原文中提出使用1*1卷积核的卷积层作为bottleneck层来优化计算效率。原文中使用的激活函数全部为relu,但个人习惯是用leakyrelu进行构建,来方便调参。
之后是用Dense层搭建Dense块,如下:
def DenseBlock(x, nb_layers, growth_rate, drop_rate=0.2): for ii in range(nb_layers): conv = DenseLayer(x, nb_filter=growth_rate, drop_rate=drop_rate) x = concatenate([x, conv], axis=3) return x
如论文中所述,将每一个Dense层的输出与其输入融合之后作为下一Dense层的输入,来实现密集连接。
最后是各Dense块之间的过渡层,如下:
def TransitionLayer(x, compression=0.5, alpha=0.0, is_max=0): nb_filter = int(x.shape.as_list()[-1]*compression) x = BatchNormalization(axis=3)(x) x = LeakyReLU(alpha=alpha)(x) x = Conv2D(nb_filter, (1, 1), strides=(1,1), padding='same')(x) if is_max != 0: x = MaxPooling2D(pool_size=(2, 2), strides=2)(x) else: x = AveragePooling2D(pool_size=(2, 2), strides=2)(x) return x
论文中提出使用均值池化层来作下采样,不过在边缘特征提取方面,最大池化层效果应该更好,这里就加了相关接口。
将上述结构按照论文中提出的结构进行拼接,这里选择的参数是论文中提到的L=100,k=12,网络连接如下:
growth_rate = 12 inpt = Input(shape=(32,32,3)) x = Conv2D(growth_rate*2, (3, 3), strides=1, padding='same')(inpt) x = BatchNormalization(axis=3)(x) x = LeakyReLU(alpha=0.1)(x) x = DenseBlock(x, 12, growth_rate, drop_rate=0.2) x = TransitionLayer(x) x = DenseBlock(x, 12, growth_rate, drop_rate=0.2) x = TransitionLayer(x) x = DenseBlock(x, 12, growth_rate, drop_rate=0.2) x = BatchNormalization(axis=3)(x) x = GlobalAveragePooling2D()(x) x = Dense(10, activation='softmax')(x) model = Model(inpt, x) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary()
虽然我们已经完成了网络的架设,网络本身的参数数量也仅有0.5M,但由于以这种方式实现的网络在Dense块中,每一次concat均需要开辟一组全新的内存空间,导致实际需要的内存空间非常大。作者在17年的时候,还专门写了相关的技术报告:https://arxiv.org/abs/1707.06990来说明怎么节省内存空间,不过单纯用keras实现起来是比较麻烦。下一篇博客中将以pytorch框架来对其进行实现。
最后放出网络完整代码:
import numpy as np
import keras
from keras.models import Model, save_model, load_model
from keras.layers import Input, Dense, Dropout, BatchNormalization, LeakyReLU, concatenate
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, GlobalAveragePooling2D
## data
import pickle
data_batch_1 = pickle.load(open("cifar-10-batches-py/data_batch_1", 'rb'), encoding='bytes')
data_batch_2 = pickle.load(open("cifar-10-batches-py/data_batch_2", 'rb'), encoding='bytes')
data_batch_3 = pickle.load(open("cifar-10-batches-py/data_batch_3", 'rb'), encoding='bytes')
data_batch_4 = pickle.load(open("cifar-10-batches-py/data_batch_4", 'rb'), encoding='bytes')
data_batch_5 = pickle.load(open("cifar-10-batches-py/data_batch_5", 'rb'), encoding='bytes')
train_X_1 = data_batch_1[b'data']
train_X_1 = train_X_1.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
train_Y_1 = data_batch_1[b'labels']
train_X_2 = data_batch_2[b'data']
train_X_2 = train_X_2.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
train_Y_2 = data_batch_2[b'labels']
train_X_3 = data_batch_3[b'data']
train_X_3 = train_X_3.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
train_Y_3 = data_batch_3[b'labels']
train_X_4 = data_batch_4[b'data']
train_X_4 = train_X_4.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
train_Y_4 = data_batch_4[b'labels']
train_X_5 = data_batch_5[b'data']
train_X_5 = train_X_5.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
train_Y_5 = data_batch_5[b'labels']
train_X = np.row_stack((train_X_1, train_X_2))
train_X = np.row_stack((train_X, train_X_3))
train_X = np.row_stack((train_X, train_X_4))
train_X = np.row_stack((train_X, train_X_5))
train_Y = np.row_stack((train_Y_1, train_Y_2))
train_Y = np.row_stack((train_Y, train_Y_3))
train_Y = np.row_stack((train_Y, train_Y_4))
train_Y = np.row_stack((train_Y, train_Y_5))
train_Y = train_Y.reshape(50000, 1).transpose(0, 1).astype("int32")
train_Y = keras.utils.to_categorical(train_Y)
test_batch = pickle.load(open("cifar-10-batches-py/test_batch", 'rb'), encoding='bytes')
test_X = test_batch[b'data']
test_X = test_X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float")
test_Y = test_batch[b'labels']
test_Y = keras.utils.to_categorical(test_Y)
train_X /= 255
test_X /= 255
# model
def DenseLayer(x, nb_filter, bn_size=4, alpha=0.0, drop_rate=0.2):
# Bottleneck layers
x = BatchNormalization(axis=3)(x)
x = LeakyReLU(alpha=alpha)(x)
x = Conv2D(bn_size*nb_filter, (1, 1), strides=(1,1), padding='same')(x)
# Composite function
x = BatchNormalization(axis=3)(x)
x = LeakyReLU(alpha=alpha)(x)
x = Conv2D(nb_filter, (3, 3), strides=(1,1), padding='same')(x)
if drop_rate: x = Dropout(drop_rate)(x)
return x
def DenseBlock(x, nb_layers, growth_rate, drop_rate=0.2):
for ii in range(nb_layers):
conv = DenseLayer(x, nb_filter=growth_rate, drop_rate=drop_rate)
x = concatenate([x, conv], axis=3)
return x
def TransitionLayer(x, compression=0.5, alpha=0.0, is_max=0):
nb_filter = int(x.shape.as_list()[-1]*compression)
x = BatchNormalization(axis=3)(x)
x = LeakyReLU(alpha=alpha)(x)
x = Conv2D(nb_filter, (1, 1), strides=(1,1), padding='same')(x)
if is_max != 0: x = MaxPooling2D(pool_size=(2, 2), strides=2)(x)
else: x = AveragePooling2D(pool_size=(2, 2), strides=2)(x)
return x
growth_rate = 12
inpt = Input(shape=(32,32,3))
x = Conv2D(growth_rate*2, (3, 3), strides=1, padding='same')(inpt)
x = BatchNormalization(axis=3)(x)
x = LeakyReLU(alpha=0.1)(x)
x = DenseBlock(x, 12, growth_rate, drop_rate=0.2)
x = TransitionLayer(x)
x = DenseBlock(x, 12, growth_rate, drop_rate=0.2)
x = TransitionLayer(x)
x = DenseBlock(x, 12, growth_rate, drop_rate=0.2)
x = BatchNormalization(axis=3)(x)
x = GlobalAveragePooling2D()(x)
x = Dense(10, activation='softmax')(x)
model = Model(inpt, x)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
for ii in range(10):
print("Epoch:", ii+1)
model.fit(train_X, train_Y, batch_size=100, epochs=1, verbose=1)
score = model.evaluate(test_X, test_Y, verbose=1)
print('Test loss =', score[0])
print('Test accuracy =', score[1])
save_model(model, 'DenseNet.h5')
model = load_model('DenseNet.h5')
pred_Y = model.predict(test_X)
score = model.evaluate(test_X, test_Y, verbose=0)
print('Test loss =', score[0])
print('Test accuracy =', score[1])
以上这篇Keras实现DenseNet结构操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容