python爬虫虎牙女主播 python爬虫看看虎牙女主播中谁最“顶”步骤详解
萌萌哒的瓤瓤 人气:0网页链接:https://www.huya.com/g/4079
这里的主要步骤其实还是和我们之前分析的一样,如下图所示:
这里再简单带大家看一下就行,重点是我们的第二部分。
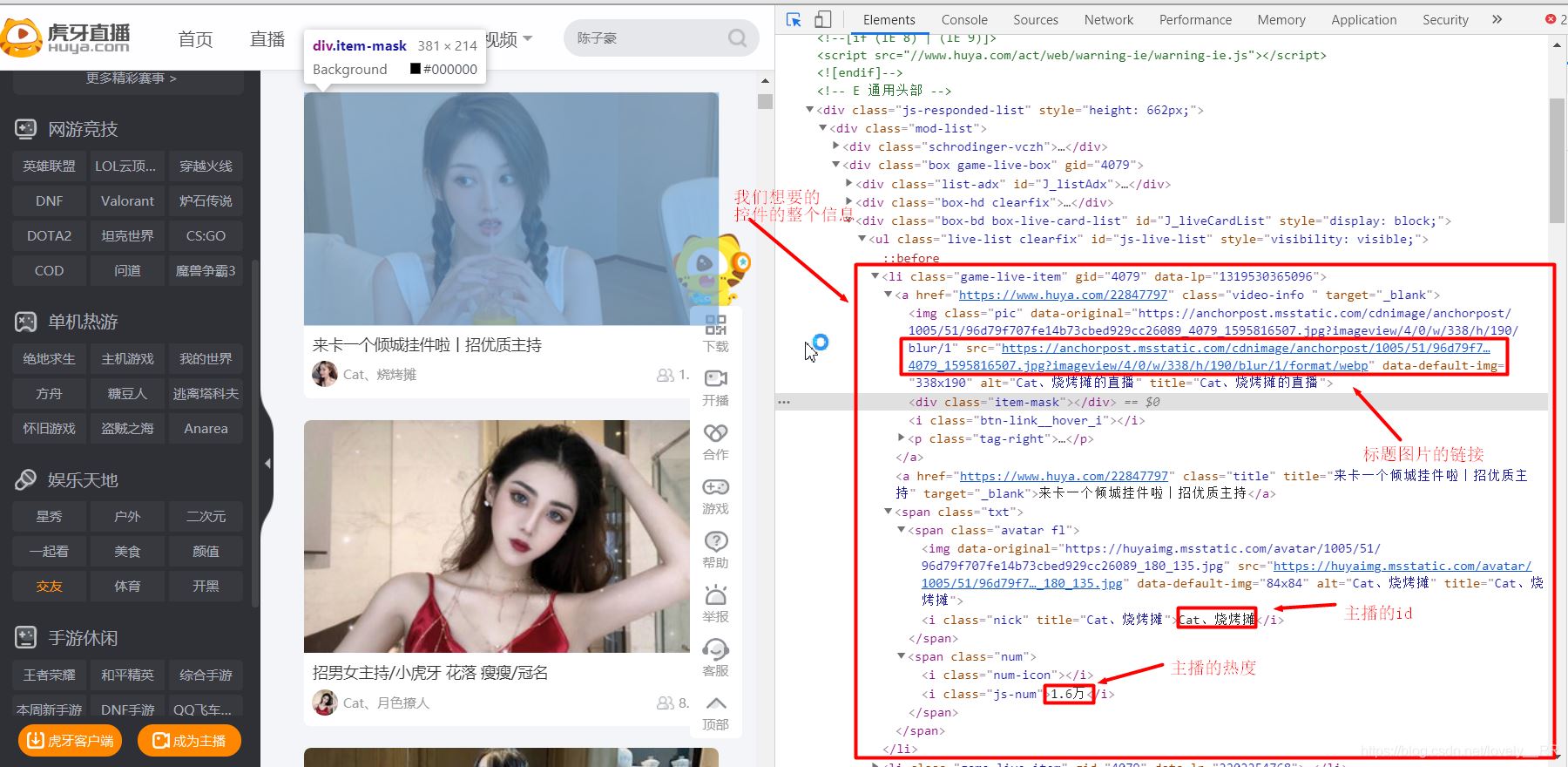
既然网页结构我们已经分析完了,那么我还是选择用之前的xpath来爬取我们所需要的资源。
# 获取所有的主播信息
def getDatas(html):
datalist=[]
parse=parsel.Selector(html)
lis=parse.xpath('//li[@class="game-live-item"]').getall()
# print(lis)
for li in lis:
data = []
parse1=parsel.Selector(li)
img_src=parse1.xpath('//img[@class="pic"]/@data-original').get("data")
data.append(img_src)
title=parse1.xpath('//i[@class="nick"]/@title').get("data")
data.append(title)
redu=parse1.xpath('//i[@class="js-num"]/text()').get("data")
data.append(redu)
datalist.append(data)
return datalist
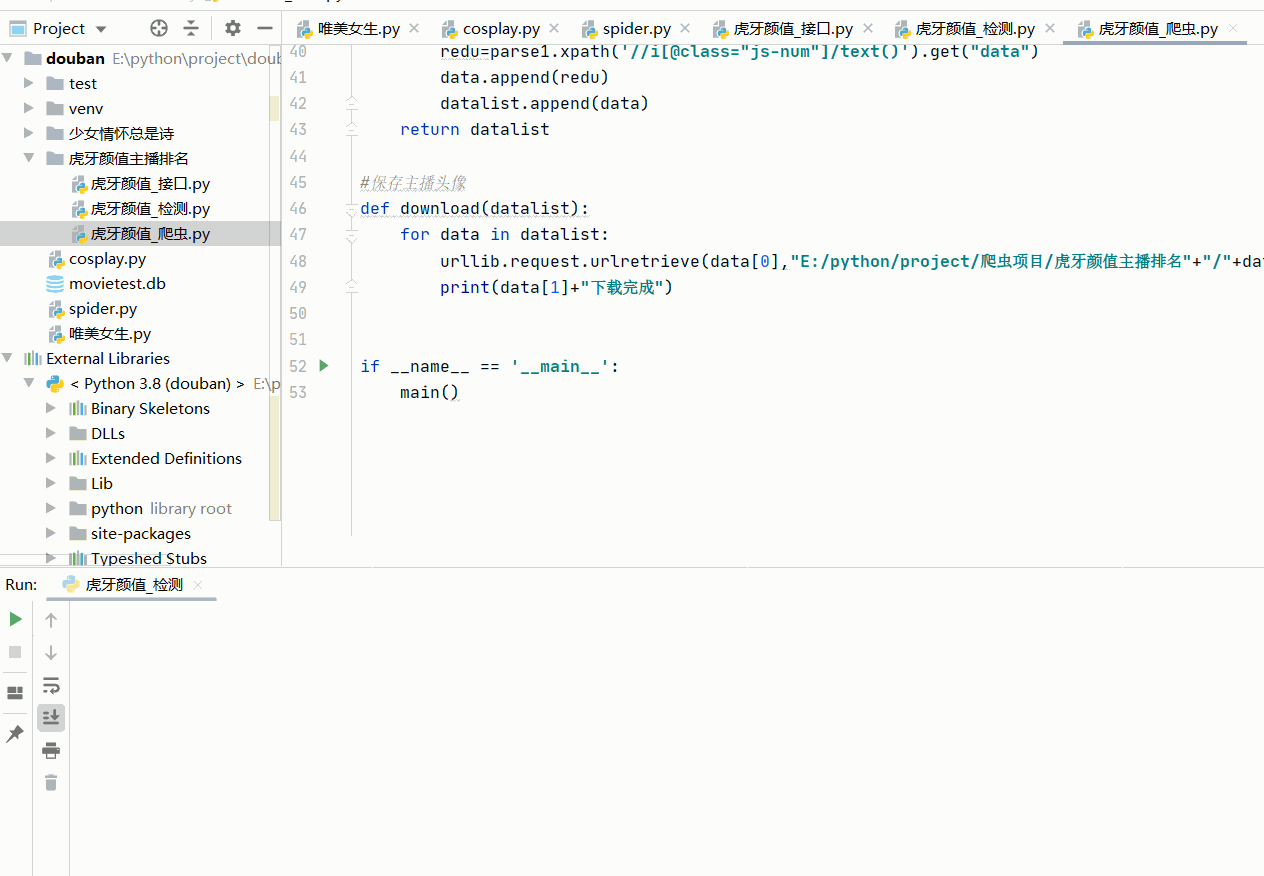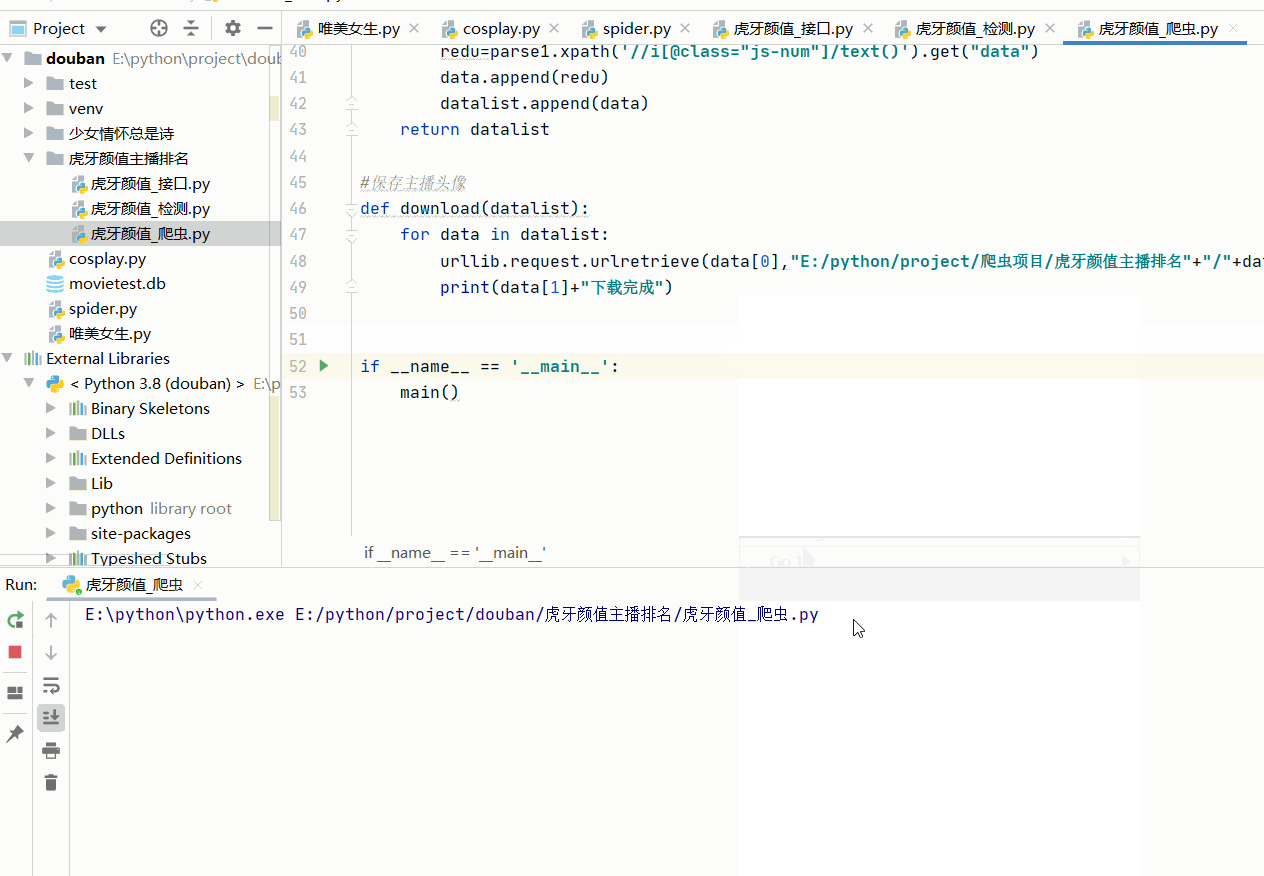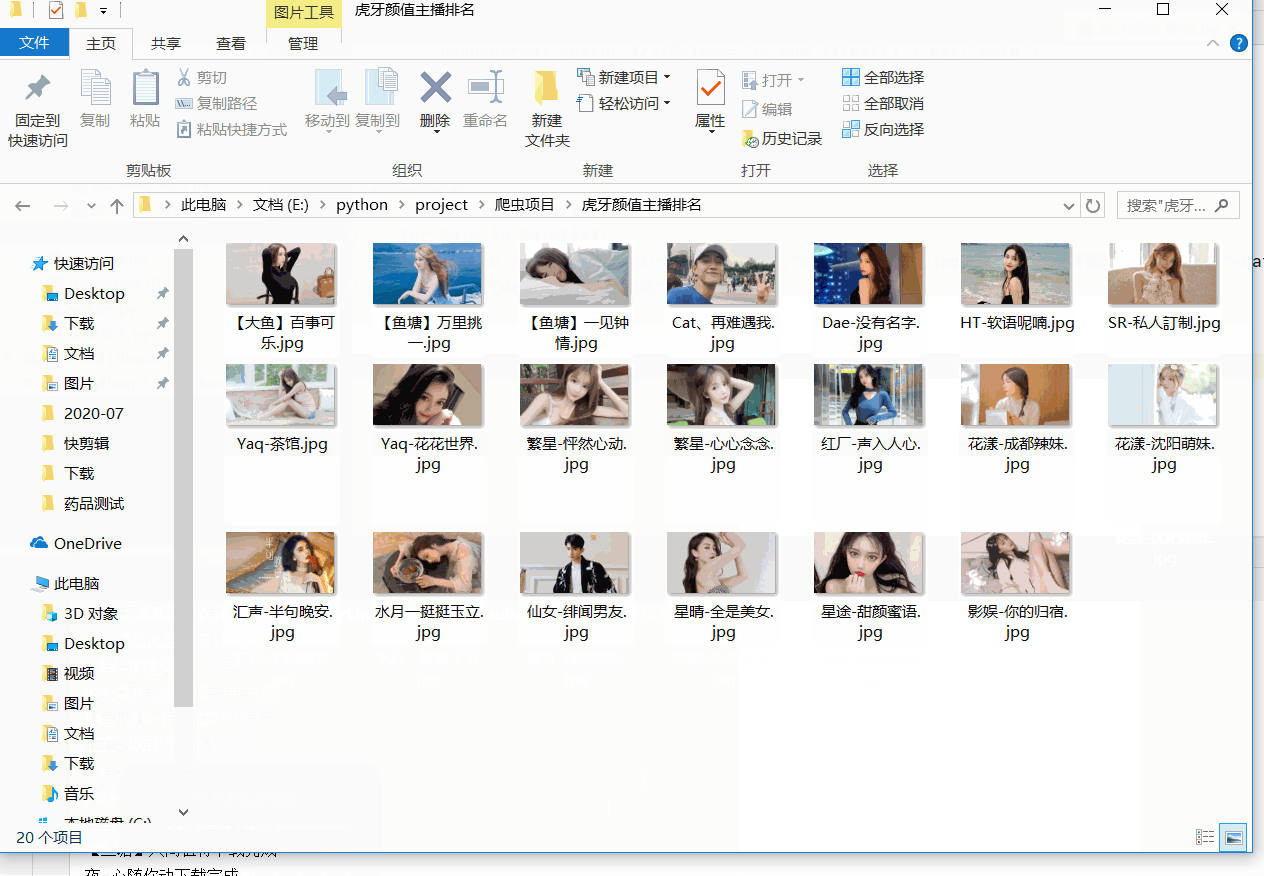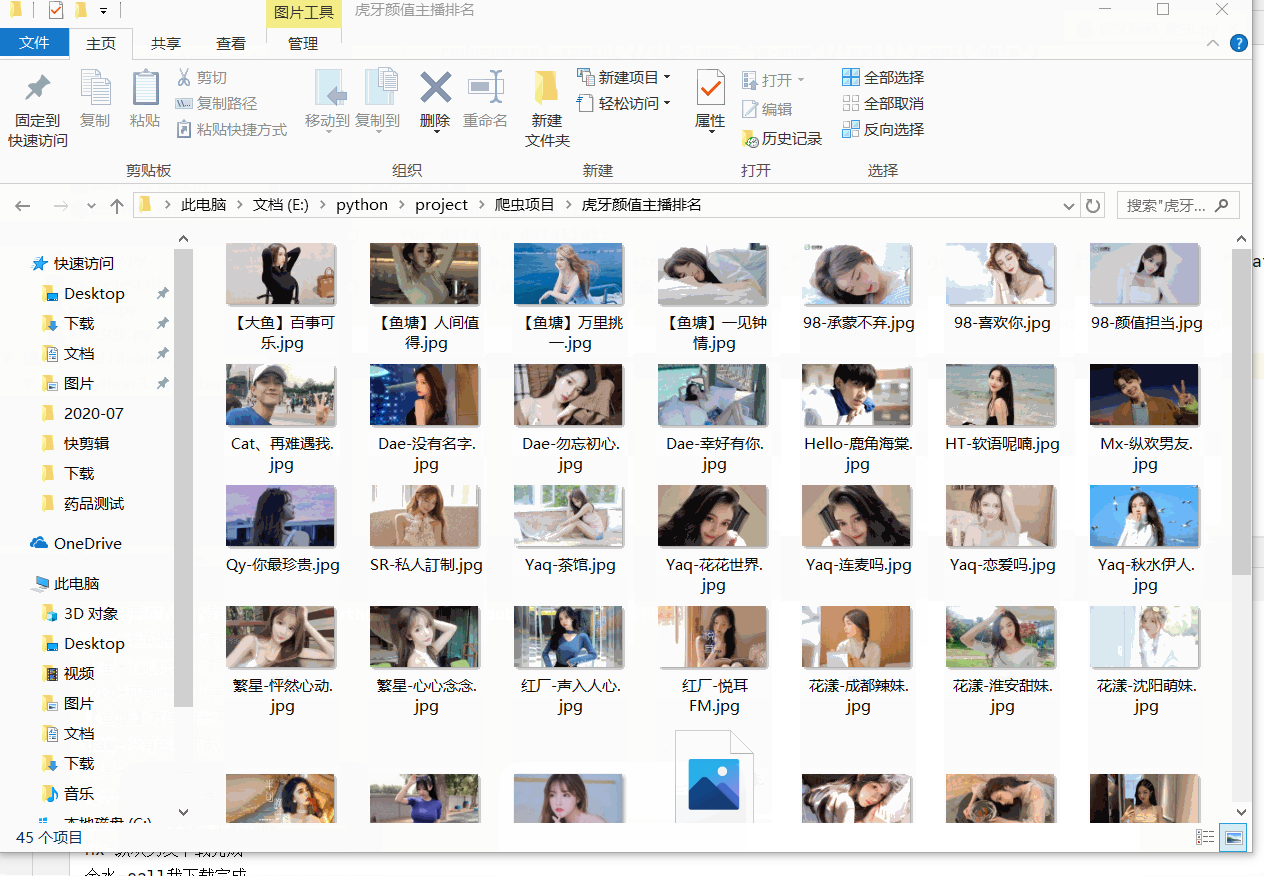
这样我们就能获取到我们所需要的所有资源,之后将图片保存下来即可。这其中有两种文件的下载方式,一种是通过 with open打开文件的方式 ,另外一种就是通过 urllib.request.urlretrieve(data,path) 的方法,网上说第二种方式的下载速度会相对快一点,并且第二种有点 set 集合的意思,可以自动进行 去重 的操作,下载的文件夹中没有该文件就下载,否则就跳过。
#保存主播头像
def download(datalist):
for data in datalist:
#第一种下载方式
with open("D:/software/python/python爬虫/虎牙颜值主播排名/", 'wb') as f:
f.write(data[0])
#第二种下载方式
urllib.request.urlretrieve(data[0],"D:/software/python/python爬虫/虎牙颜值主播排名"+"/"+data[1]+".jpg")
print(data[1]+"下载完成")
百度人脸识别接口
百度AI开放平台链接:https://ai.baidu.com/

输入相应的应用名称以及简介即可。
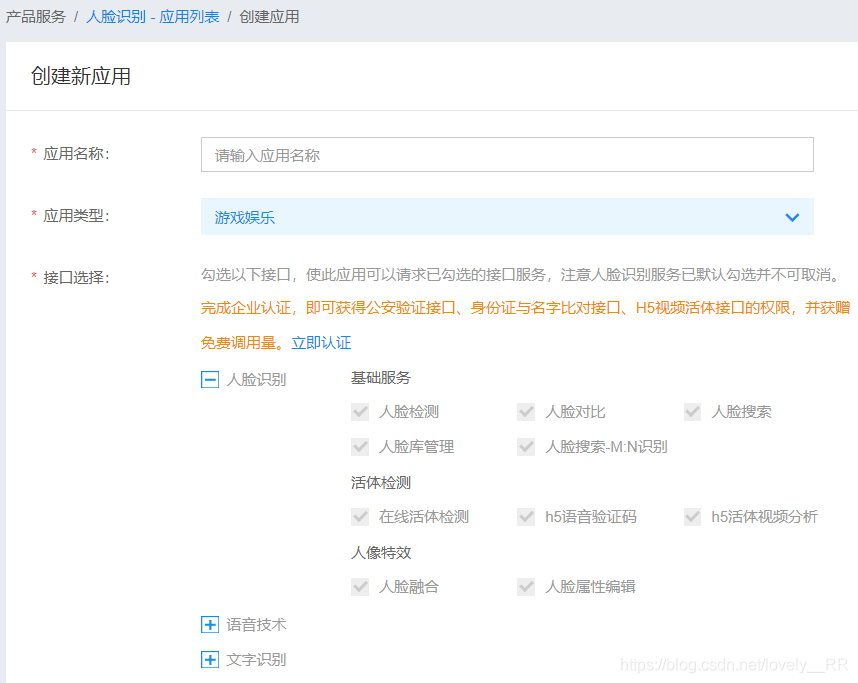
这样我们的应用就算创建完毕了。选中的部分也是我们接下来会用到的。
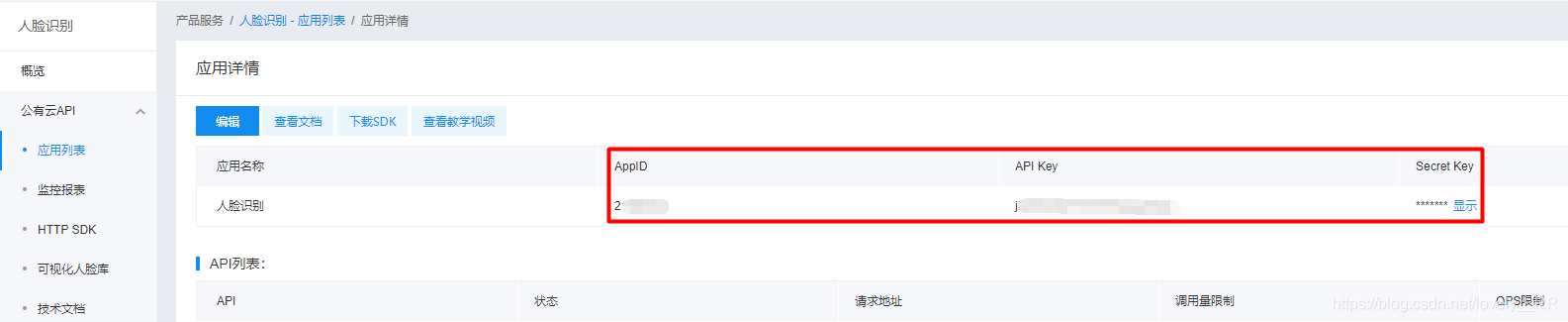
之后我们先去看一下sdk文件
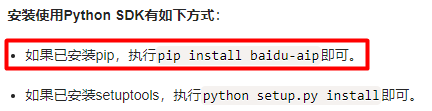
看使用说明即可,不用着急下载,之后我们直接在pycharm中安装模块就行。
之后我们来看一下简单的操作流程首先先创建客户端:

之后我们就是调用接口解析图片,因为我们需要返回颜值分数这一个参数,所以还需要带参数进行请求,否则无法将分数信息返回给我们。如下图:
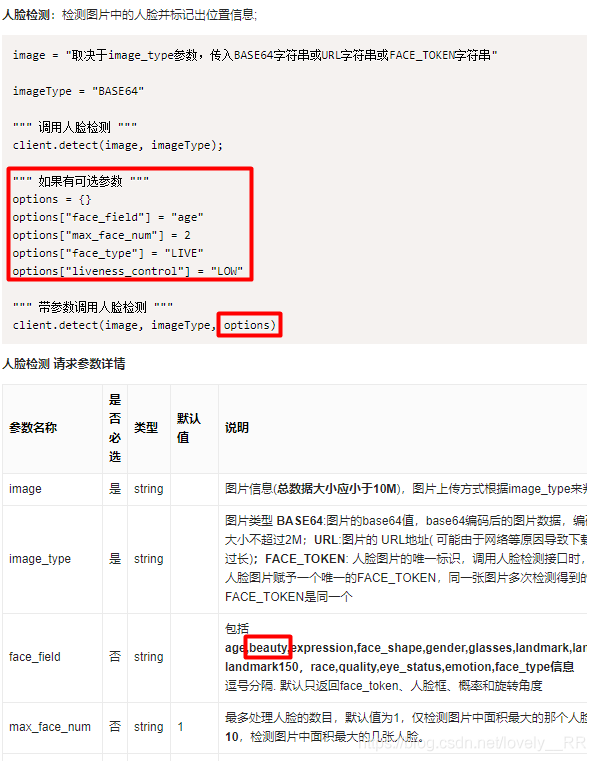
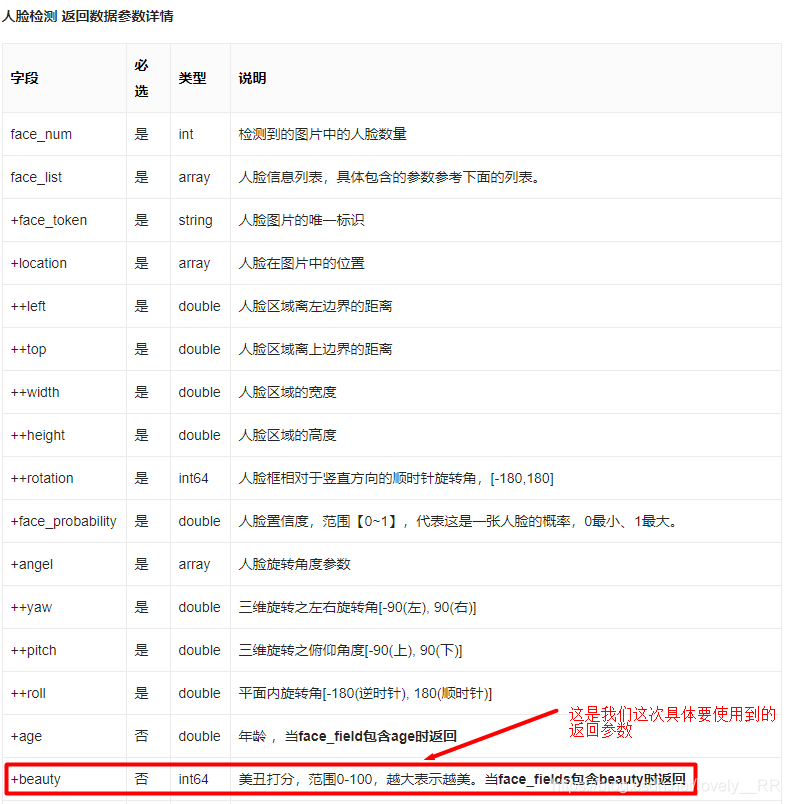
这样我们颜值检测的接口流程基本就已经理清楚了,代码如下:
def face_rg(file_path):
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipFace(APP_ID, API_KEY, SECRET_KEY)
with open(file_path,'rb')as file:
data=base64.b64encode(file.read())
image=data.decode()
imageType = "BASE64"
""" 如果有可选参数 """
options = {}
options["face_field"] = "beauty"
""" 带参数调用人脸检测 """
result=client.detect(image, imageType, options)
# print(result)
return result['result']['face_list'][0]['beauty']
之后我们就只需要编写一个遍历文件夹下面的图片进行检测,之后将整个信息按照颜值分数进行降序排列:
path=r"D:\software\python\python爬虫\虎牙颜值主播排名"
image_list=os.listdir(path)
name_score={}
for image in image_list:
try:
print(image.split(".")[0]+"颜值评分为:%d"%face_rg(path+"/"+image))
name_score[image.split(".")[0]]=face_rg(path+"/"+image)
except:
pass
second_score=sorted(name_score.items(),key=lambda x:x[1],reverse=True)
print("-------------------------------------检测结束-------------------------------------")
print("-------------------------------------以下是排名-------------------------------------")
for a,b in enumerate(second_score):
print("{}的颜值评分为:{},排名第{}".format(second_score[a][0],second_score[a][1],a+1))
这里博主测完自己的颜值是 52分,连及格线都没到 ,大家也可以在评论区说说自己的分数。

效果演示

加载全部内容