python读写csv python读写数据读写csv文件(pandas用法)
小朱小朱绝不服输 人气:0python中数据处理是比较方便的,经常用的就是读写文件,提取数据等,本博客主要介绍其中的一些用法。Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
一、pandas读取csv文件
数据处理过程中csv文件用的比较多。
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
下面看一下pd.read_csv常用的参数:
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
常用参数解释:read_csv与read_table常用的参数(更多参数查看官方手册):
filepath_or_buffer #需要读取的文件及路径 sep / delimiter 列分隔符,普通文本文件,应该都是使用结构化的方式来组织,才能使用dataframe header 文件中是否需要读取列名的一行,header=None(使用names自定义列名,否则默认0,1,2,...),header=0(将首行设为列名) names 如果header=None,那么names必须制定!否则就没有列的定义了。 shkiprows= 10 # 跳过前十行 nrows = 10 # 只去前10行 usecols=[0,1,2,...] #需要读取的列,可以是列的位置编号,也可以是列的名称 parse_dates = ['col_name'] # 指定某行读取为日期格式 index_col = None /False /0,重新生成一列成为index值,0表示第一列,用作行索引的列编号或列名。可以是单个名称/数字或由多个名称/数宇组成的列表(层次化索引) error_bad_lines = False # 当某行数据有问题时,不报错,直接跳过,处理脏数据时使用 na_values = 'NULL' # 将NULL识别为空值 encoding='utf-8' #指明读取文件的编码,默认utf-8
读取csv/txt/tsv文件,返回一个DataFrame类型的对象。
举例:

import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
name age birth
0 zhu 20 2000.1.5
1 wang 20 2000.6.18
2 zhang 21 1999.11.11
3 zhu 22 1998.10.24
pandas用iloc,loc提取数据
提取行数据:
loc函数:通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第2行的数据)
import pandas as pd
import numpy as np
#创建一个Dataframe
data = pd.DataFrame(np.arange(16).reshape(4, 4), index=list('abcd'), columns=list('ABCD'))
print(data)
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
loc提取'a'的行:
print(data.loc['a']) A 0 B 1 C 2 D 3 Name: a, dtype: int32
iloc提取第2行:
print(data.iloc[2]) A 8 B 9 C 10 D 11 Name: c, dtype: int32
提取列数据:
print(data.loc[:, ['A']])#取'A'列所有行,多取几列格式为 data.loc[:,['A','B']] A a 0 b 4 c 8 d 12
print(data.iloc[:, [0]]) A a 0 b 4 c 8 d 12
提取指定行,指定列:
print(data.loc[['a','b'],['A','B']]) #提取index为'a','b',列名为'A','B'中的数据 A B a 0 1 b 4 5
print(data.iloc[[0,1],[0,1]]) #提取第0、1行,第0、1列中的数据 A B a 0 1 b 4 5
提取所有行所有列:
print(data.loc[:,:])#取A,B,C,D列的所有行 print(data.iloc[:,:]) A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 d 12 13 14 15
根据某个指定数据提取行:
print(data.loc[data['A']==0])#提取data数据(筛选条件: A列中数字为0所在的行数据) A B C D a 0 1 2 3
二、pandas写入csv文件
pandas将多组列表写入csv
import pandas as pd
#任意的多组列表
a = [1,2,3]
b = [4,5,6]
#字典中的key值即为csv中列名
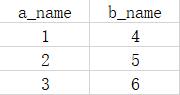
dataframe = pd.DataFrame({'a_name':a,'b_name':b})
#将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv("test.csv",index=False,sep=',')
结果:
如果你想写入一行,就是你存储的一个列表是一行数据,你想把这一行数据写入csv文件。
这个时候可以使用csv方法,一行一行的写
import csv
with open("test.csv","w") as csvfile:
writer = csv.writer(csvfile)
#先写入columns_name
writer.writerow(["index","a_name","b_name"])
#写入一行用writerow
#write.writerow([0,1,2])
#写入多行用writerows
writer.writerows([[0,1,3],[1,2,3],[2,3,4]])
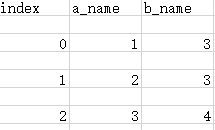
可以看到,每次写一行,就自动空行,解决办法就是在打开文件的时候加上参数newline=''
import csv
with open("F:/zhu/test/test.csv","w", newline='') as csvfile:
writer = csv.writer(csvfile)
#先写入columns_name
writer.writerow(["index","a_name","b_name"])
#写入多行用writerows
writer.writerows([[0,1,3],[1,2,3],[2,3,4]])

写入txt文件类似
(1)创建txt数据文件,创建好文件记得要关闭文件,不然读取不了文件内容
(2)读取txt文件
#读取txt文件
file=open("G:\\info.txt",'r',encoding='utf-8')
userlines=file.readlines()
file.close()
for line in userlines:
username=line.split(',')[0] #读取用户名
password=line.split(',')[1] #读取密码
print(username,password)
三、pandas查看数据表信息
1)查看维度:data.shape
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
print(data.shape)
index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4
(3, 3)
2)查看数据表基本信息:data.info
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
print(data.info)
index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4
<bound method DataFrame.info of index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4>
3)查看每一行的格式:data.dtype
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data.dtypes)
index int64
a_name int64
b_name int64
dtype: object
4)查看前2行数据、后2行数据
df.head() #默认前10行数据,注意:可以在head函数中填写参数,自定义要查看的行数 df.tail() #默认后10 行数据
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
print(data.head(2))
print(data.tail(2))
index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4
index a_name b_name
0 0 1 3
1 1 2 3
index a_name b_name
1 1 2 3
2 2 3 4
四、数据清洗
1)NaN数值的处理:用数字0填充空值
data.fillna(value=0,inplace=True)
注意:df.fillna不会立即生效,需要设置inplace=True
2)清除字符字段的字符空格
字符串(str)的头和尾的空格,以及位于头尾的\n \t之类给删掉
data['customername']=data['customername'].map(str.strip)#如清除customername中出现的空格
3)大小写转换
data['customername']=data['customername'].str.lower()
4)删除重复出现的值
data.drop_duplicates(['customername'],inplace=True)
5)数据替换
data['customername'].replace('111','qqq',inplace=True)
参考:
加载全部内容