Python 逐块读取文本 Python 数据分析之逐块读取文本的实现
毕小宝 人气:0背景
《利用Python进行数据分析》,第 6 章的数据加载操作 read_xxx,有 chunksize 参数可以进行逐块加载。
经测试,它的本质就是将文本分成若干块,每次处理 chunksize 行的数据,最终返回一个TextParser 对象,对该对象进行迭代遍历,可以完成逐块统计的合并处理。
示例代码
文中的示例代码分析如下:
from pandas import DataFrame,Series import pandas as pd path='D:/AStudy2018/pydata-book-2nd-edition/examples/ex6.csv' # chunksize return TextParser chunker=pd.read_csv(path,chunksize=1000) # an array of Series tot=Series([]) chunkercount=0 for piece in chunker: print '------------piece[key] value_counts start-----------' #piece is a DataFrame,lenth is chunksize=1000,and piece[key] is a Series ,key is int ,value is the key column print piece['key'].value_counts() print '------------piece[key] value_counts end-------------' #piece[key] value_counts is a Series ,key is the key column, and value is the key count tot=tot.add(piece['key'].value_counts(),fill_value=0) chunkercount+=1 #last order the series tot=tot.order(ascending=False) print chunkercount print '--------------'
流程分析
首先,例子数据 ex6.csv 文件总共有 10000 行数据,使用 chunksize=1000 后,read_csv操作返回一个 TextParser 对象,该对象总共有10个元素,遍历过程中打印 chunkercount验证得到。
其次,每个 piece 对象是一个 DataFrame 对象,piece['key'] 得到的是一个 Series 对象,默认是数值索引,值为 csv 文件中的 key 列的值,即各个字符串。
将每个 Series 的 value_counts 作为一个Series,与上一次统计的 tot 结果进行 add 操作,最终得到所有块数据中各个 key 的累加值。
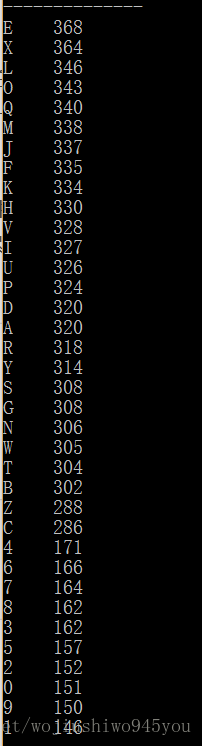
最后,对 tot 进行 order 排序,按降序得到各个 key 的值在 csv 文件中出现的总次数。
这里很巧妙了使用 Series 对象的 add 操作,对两个 Series 执行 add 操作,即合并相同key:key相同的记录的值累加,key不存在的记录设置填充值为0。
输出结果为:
加载全部内容