记录我的 python 学习历程-Day13 匿名函数、内置函数 II、闭包
Dylan_Yu 人气:1一、匿名函数
以后面试或者工作中经常用匿名函数 lambda,也叫一句话函数。
课上练习:
# 正常函数:
def func(a, b):
return a + b
print(func(4, 6)) # 10
# 匿名函数:
func = lambda a, b: a + b
print(func(11, 33)) # 44
# 写匿名函数:接收一个可切片的数据,返回索引为0与2的对应的元素(元组形式)。
func = lambda x: (x[0], x[2])
print(func('Dylan')) # ('D', 'l')
# 写匿名函数:接收两个int参数,将较大的数据返回。
func1 = lambda a, b: a if a > b else b
print(func1(11, 88)) # 88语法:
函数名 = lambda 参数:返回值
此函数不是没有名字,他是有名字的,他的名字就是你给其设置的变量,比如func.
lambda 是定义匿名函数的关键字,相当于函数的def.
lambda 后面直接加形参,形参加多少都可以,只要用逗号隔开就行。
func = lambda a,b,*args,sex= 'alex',c,**kwargs: kwargs print(func(3, 4,c=666,name='alex')) # {'name': 'alex'} # 所有类型的形参都可以加,但是一般使用匿名函数只是加位置参数,其他的用不到。返回值在冒号之后设置,返回值和正常的函数一样,可以是任意数据类型。
匿名函数不管多复杂.只能写一行.且逻辑结束后直接返回数据
二、内置函数 ii
红色重点讲解:abs() enumerate() filter() map() max() min() open() range() print() len() list() dict() str() reversed() set() sorted() sum() tuple() type() zip() dir()
# python 提供了68个内置函数。
# eval() 剥去字符串的外衣,运算里面的代码,有返回值。**
s = '1 + 3'
print(s) # 1 + 3
print(eval(s)) # 4
s1 = "{'name': 'Dylan'}"
print(s1, type(s1)) # {'name': 'Dylan'} <class 'str'>
# print(dict(s1)) # 不能转换成字典,报错。
print(eval(s1), type(eval(s1))) # {'name': 'Dylan'} <class 'dict'> 转换成字典了。
# 网络传输的 str input 输入的时候,sql 注入等,绝对不能使用 eval()。
# exec()与 eval()几科一样,代码流。
msg = '''
for i in range(10):
print(i)
'''
# print(msg)
exec(msg)
# hash() 获取一个对象(可哈希对象:int,str,Bool,tuple)的哈希值。
print(hash('Dylan')) # -2239819904114377323
# help() 帮助 **
s2 = 'Dylan'
print(help(str.upper))
s1 = s2.upper()
print(s1)
# callable():用于检查一个对象是否是可调用的。***
s1 = 'Dylan'
def func():
pass
print(callable(s1)) # False
print(callable(func)) # True
# int() 用于将一个字符串或数字转换为整型。
print(int()) # 0
print(int('12')) # 12
print(int(3.6)) # 3
print(int('0100', base=2)) # 将2进制的 0100 转化成十进制。结果为 4
# float() 用于将整数和字符串转换成浮点数。
print(float(3)) # 3.0
print(float()) # 0.0
print(float("12.33")) # 12.33
# complex() 用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。
# 如果第一个参数为字符串,则不需要指定第二个参数。
print(complex(1, 2)) # (1+2j)
# bin:将十进制转换成二进制并返回。**
# oct:将十进制转化成八进制字符串并返回。**
# hex:将十进制转化成十六进制字符串并返回。**
print(bin(10), type(bin(10))) # 0b1010 <class 'str'>
print(oct(10), type(oct(10))) # 0o12 <class 'str'>
print(hex(10), type(hex(10))) # 0xa <class 'str'>
# divmod() 计算除数与被除数的结果,返回一个包含商和余数的元组(a // b, a % b)。**
# round() 保留浮点数的小数位数,默认保留整数。**
# pow() 求x**y次幂。(三个参数为x**y的结果对z取余)**
print(divmod(8, 3)) # (2, 2)
print(round(7/3, 2)) # 2.33
print(round(7/3)) # 2
print(round(3.32353, 3)) # 3.323
print(pow(2, 3)) # 两个参数为2**3次幂
print(pow(2, 3, 3)) # 三个参数为2**3次幂,对3取余。结果 2。
# bytes() 用于不同编码之间的转化。***
s = 'Dylan'
bs = s.encode('utf-8')
print(bs) # b'Dylan'
bs = bytes(s, encoding='utf-8')
print(bs) # b'Dylan'
# ord:输入字符找该字符编码的位置
# chr:输入位置数字找出其对应的字符
print(ord('a')) # 97
print(ord('中')) # 20013
print(chr(97)) # a
print(chr(20013)) # 中
# repr:返回一个对象的string形式(原形毕露)。
print(repr('Dylan')) # 'Dylan'
print('Dylan') # Dylan
name = 'Dylan'
print('我叫%r' % name) # 我叫'Dylan'
# all:可迭代对象中,全都是True才是True
# any:可迭代对象中,有一个True 就是True
print(all([1, 2, True, 0])) # False
print(any([1, '', 0])) # True
# #################### 非常重要 ######################## #
# print() 屏幕输出。
# 源码分析
# def print(self, *args, sep=' ', end='\n', file=None): # known special case of print
#
# print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
# file: 默认是输出到屏幕,如果设置为文件句柄,输出到文件
# sep: 打印多个值之间的分隔符,默认为空格
# end: 每一次打印的结尾,默认为换行符
# flush: 立即把内容输出到流文件,不作缓存
#
print(11, 22, 33, sep='|') # 11|22|33
print(111, end='')
print(222) # 两行结果为 111222
# list() 将一个可迭代对象转换成列表
# tuple() 将一个可迭代对象转换成元组
# dict() 通过相应的方式创建字典。
l1 = list('Dylang')
print(l1) # ['D', 'y', 'l', 'a', 'n', 'g']
tu = tuple('Dylan')
print(tu) # ('D', 'y', 'l', 'a', 'n')
# dict 创建字典的几种方式
# 直接创建
# 元组的解构
dic = dict([(1, 'one'), (2, 'two'), (3, 'three')])
print(dic) # {1: 'one', 2: 'two', 3: 'three'}
dic1 = dict(one=1, two=2)
print(dic1) # {'one': 1, 'two': 2}
# fromkeys
# update
# 字典的推导式
# abs() 返回绝对值
i = -88
print(abs(i)) # 88
# sum() 求和
l1 = [i for i in range(11)]
s1 = '12345'
print(sum(l1)) # 55
print(sum(l1, 100)) # 设置初始数为100 # 结果:155
# print(sum(s1)) # 报错 TypeError: unsupported operand type(s) for +: 'int' and 'str'
# reversed() 将一个序列翻转, 返回翻转序列的迭代器 reversed
l = reversed('你好') # 获取到的是一个生成器
print(list(l)) # 将生成器中的元素转换为列表 ['好', '你']
ret = reversed([1, 4, 6, 5, 8, 7]) # 获取到的是一个生成器
print(list(ret)) # [7, 8, 5, 6, 4, 1]
# zip() 拉链方法。函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,
# 然后返回由这些元祖组成的内容,如果各个迭代器的元素个数不一致,则按照长度最短的返回
s = 'abcde'
tu = ('Dylan', 'xiaobai', 'niaoren')
l1 = [1, 2, 3, 4]
obj = zip(s, tu, l1)
for i in obj:
print(i)
print(list(obj))
# ################# 以下方法最最最最最重要 ##############
# min() 求最小值
# max() 最大值与最小值用法相同。
print(min([1, 2, 3, 4])) # 返回此序列最小值
ret = min([1, 2, -3], key=abs) # 按照绝对值的大小,返回此序列的最小值
print(ret)
# 加 key 是可以加函数名的,min 会自动获取传入函数中的参数的每个元素,
# 然后通过你设定的返回值比较大小,返回最小的传入的那个参数。
print(min(1, 2, -5, 6, -3, key=lambda x: abs(x))) # 可以设置很多参数比较大小
dic = {'a': 3, 'b': 2, 'c': 1}
print(min(dic, key=lambda x: dic[x]))
# x为dic的key,lambda的返回值(即dic的值进行比较)返回最小的值对应的键
l2 = [('太白', 18), ('alex', 73), ('wusir', 35), ('口天吴', 41)]
print(min(l2)) # ('alex', 73)
print(min(l2, key=lambda x: x[1])) # ('太白', 18)
# sorted()排序函数
# 语法:sorted(iterable,key=None,reverse=False)
# iterable : 可迭代对象
# key: 排序规则(排序函数),在sorted内部会将可迭代对象中的每一个元素传递给这个函数的参数.根据函数运算的结果进行排序
# reverse :是否是倒序,True 倒序 False 正序
l1 = [22, 33, 1, 2, 8, 7, 6, 5]
l2 = sorted(l1)
print(l1) # [22, 33, 1, 2, 8, 7, 6, 5]
print(l2) # [1, 2, 5, 6, 7, 8, 22, 33]
l3 = [('大壮', 76), ('雪飞', 70), ('纳钦', 94), ('张珵', 98), ('b哥', 96)]
print(sorted(l3)) # [('b哥', 96), ('大壮', 76), ('张珵', 98), ('纳钦', 94), ('雪飞', 70)]
print(sorted(l3, key=lambda x: x[1])) # 返回的是一个列表,默认从低到高。
print(sorted(l3, key=lambda x: x[1], reverse=True)) # # 返回的是一个列表,从高到低
# filter()筛选过滤
# 语法: filter(function,iterable)
# function: 用来筛选的函数,在filter中会自动的把iterable中的元素传递给function,
# 然后根据function返回的True或者False来判断是否保留此项数据
# iterable:可迭代对象
l1 = [2, 3, 4, 1, 6, 7, 8]
print([i for i in l1 if i > 3]) # [4, 6, 7, 8] 返回的是列表
ret = filter(lambda x: x > 3, l1) # 返回的是个迭代器
print(ret) # <filter object at 0x10601db70>
print(list(ret)) # [4, 6, 7, 8]
# map() 映射函数
# 语法: map(function,iterable) 可以对可迭代对象中的每一个元素进映射,分别取执行function
# 计算列表中每个元素的平方,返回新列表
lst = [1, 2, 3, 4, 5]
def func(s):
return s * s
mp = map(func, lst)
print(mp) # <map object at 0x10581dd30>
print(list(mp)) # [1, 4, 9, 16, 25]
# 改写成lambda
print(list(map(lambda s: s * s, lst))) # [1, 4, 9, 16, 25]
# 计算两个列表中相同位置的数据的和
lst1 = [1, 2, 3, 4, 5]
lst2 = [2, 4, 6, 8, 10]
print(list(map(lambda x, y: x + y, lst1, lst2))) # [3, 6, 9, 12, 15]
# reduce()
from functools import reduce
def func(x, y):
return x + y
# reduce 的使用方式:
# reduce(函数名,可迭代对象) # 这两个参数必须都要有,缺一个不行
ret = reduce(func, [3, 4, 5, 6, 7])
print(ret) # 结果 25
# reduce的作用是先把列表中的前俩个元素取出计算出一个值然后临时保存着,
# 接下来用这个临时保存的值和列表中第三个元素进行计算,求出一个新的值将最开始
# 临时保存的值覆盖掉,然后在用这个新的临时值和列表中第四个元素计算.依次类推
# 注意:我们放进去的可迭代对象没有更改
# 以上这个例子我们使用sum就可以完全的实现了.我现在有[1,2,3,4]想让列表中的数变成1234,就要用到reduce了.
# 普通函数版
from functools import reduce
def func(x, y):
return x * 10 + y
# 第一次的时候 x是1 y是2 x乘以10就是10,然后加上y也就是2最终结果是12然后临时存储起来了
# 第二次的时候x是临时存储的值12 x乘以10就是 120 然后加上y也就是3最终结果是123临时存储起来了
# 第三次的时候x是临时存储的值123 x乘以10就是 1230 然后加上y也就是4最终结果是1234然后返回了
l = reduce(func, [1, 2, 3, 4])
print(l)
# 匿名函数版
l = reduce(lambda x, y: x * 10 + y, [1, 2, 3, 4])
print(l)
# 在Python2.x版本中recude是直接 import就可以的, Python3.x版本中需要从functools这个包中导入
# 龟叔本打算将 lambda 和 reduce 都从全局名字空间都移除, 舆论说龟叔不喜欢lambda 和 reduce
# 最后lambda没删除是因为和一个人写信写了好多封,进行交流然后把lambda保住了.三、闭包
由于闭包这个概念比较难以理解,尤其是初学者来说,相对难以掌握,所以我们通过示例去理解学习闭包。
给大家提个需求,然后用函数去实现:完成一个计算不断增加的系列值的平均值的需求。
例如:整个历史中的某个商品的平均收盘价。什么叫平局收盘价呢?就是从这个商品一出现开始,每天记录当天价格,然后计算他的平均值:平均值要考虑直至目前为止所有的价格。
比如大众推出了一款新车:小白轿车。
第一天价格为:100000元,平均收盘价:100000元
第二天价格为:110000元,平均收盘价:(100000 + 110000)/2 元
第三天价格为:120000元,平均收盘价:(100000 + 110000 + 120000)/3 元
........
series = []
def make_averager(new_value):
series.append(new_value)
total = sum(series)
return total / len(series)
print(make_averager(100000))
print(make_averager(110000))
print(make_averager(120000))从上面的例子可以看出,基本上完成了我们的要求,但是这个代码相对来说是不安全的,因为你的这个series列表是一个全局变量,只要是全局作用域的任何地方,都可能对这个列表进行改变。
series = []
def make_averager(new_value):
series.append(new_value)
total = sum(series)
return total / len(series)
print(make_averager(100000))
print(make_averager(110000))
series.append(666) # 如果对数据进行相应改变,那么你的平均收盘价就会出现很大的问题。
print(make_averager(120000))def make_averager(new_value):
series = []
series.append(new_value)
total = sum(series)
return total / len(series)
print(make_averager(100000)) # 100000.0
print(make_averager(110000)) # 110000.0
print(make_averager(120000)) # 120000.0这样计算的结果是不正确的,那是因为执行函数,会开启一个临时的名称空间,随着函数的结束而消失,所以你每次执行函数的时候,都是重新创建这个列表,那么这怎么做呢?这种情况下,就需要用到我们讲的闭包了,我们用闭包的思想改一下这个代码。
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
avg = make_averager()
print(avg(100000))
print(avg(110000))
print(avg(120000))大家仔细看一下这个代码,我是在函数中嵌套了一个函数。那么avg 这个变量接收的实际是averager函数名,也就是其对应的内存地址,我执行了三次avg 也就是执行了三次averager这个函数。那么此时你们有什么问题?
肯定有学生就会问,那么我的make_averager这个函数只是执行了一次,为什么series这个列表没有消失?反而还可以被调用三次呢?这个就是最关键的地方,也是闭包的精华所在。我给大家说一下这个原理,以图为证:
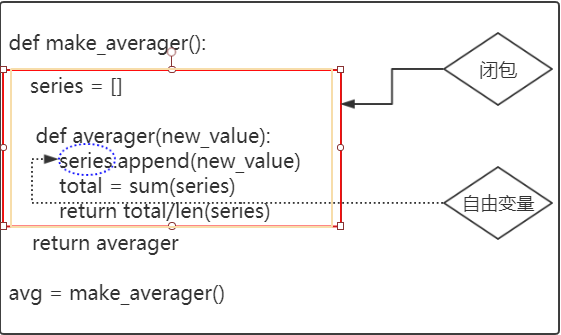
上面被红色方框框起来的区域就是闭包,被蓝色圈起来的那个变量应该是make_averager()函数的局部变量,它应该是随着make_averager()函数的执行结束之后而消失。但是他没有,是因为此区域形成了闭包,series变量就变成了一个叫自由变量的东西,averager函数的作用域会延伸到包含自由变量series的绑定。也就是说,每次我调用avg对应的averager函数 时,都可以引用到这个自用变量series,这个就是闭包。
闭包的定义:
- 闭包是嵌套在函数中的函数。
- 闭包必须是内层函数对外层函数的变量(非全局变量)的引用。
如何判断判断闭包?举例让同学回答:
# 例一:
def wrapper():
a = 1
def inner():
print(a)
return inner
ret = wrapper()
# 例二:
a = 2
def wrapper():
def inner():
print(a)
return inner
ret = wrapper()
# 例三:
def wrapper(a,b):
def inner():
print(a)
print(b)
return inner
a = 2
b = 3
ret = wrapper(a,b)以上三个例子,最难判断的是第三个,其实第三个也是闭包,如果我们每次去研究代码判断其是不是闭包,有一些不科学,或者过于麻烦了,那么有一些函数的属性是可以获取到此函数是否拥有自由变量的,如果此函数拥有自由变量,那么就可以侧面证明其是否是闭包函数了(了解):
def make_averager():
series = []
def averager(new_value):
series.append(new_value)
total = sum(series)
return total/len(series)
return averager
avg = make_averager()
# 函数名.__code__.co_freevars 查看函数的自由变量
print(avg.__code__.co_freevars) # ('series',)
当然还有一些参数,仅供了解:
# 函数名.__code__.co_freevars 查看函数的自由变量
print(avg.__code__.co_freevars) # ('series',)
# 函数名.__code__.co_varnames 查看函数的局部变量
print(avg.__code__.co_varnames) # ('new_value', 'total')
# 函数名.__closure__ 获取具体的自由变量对象,也就是cell对象。
# (<cell at 0x0000020070CB7618: int object at 0x000000005CA08090>,)
# cell_contents 自由变量具体的值
print(avg.__closure__[0].cell_contents) # []闭包的作用:保存局部信息不被销毁,保证数据的安全性。
闭包的应用:
- 可以保存一些非全局变量但是不易被销毁、改变的数据。
- 装饰器。
加载全部内容