selenium与xpath指定位置元素 selenium与xpath之获取指定位置的元素的实现
封妖师的徒弟 人气:0今天有点新的与大家分享,关于selenium与xpath之间爬数据获取指定位置的时候,方式不一样哦。
详情可以看我的代码,以b站来看好吧:
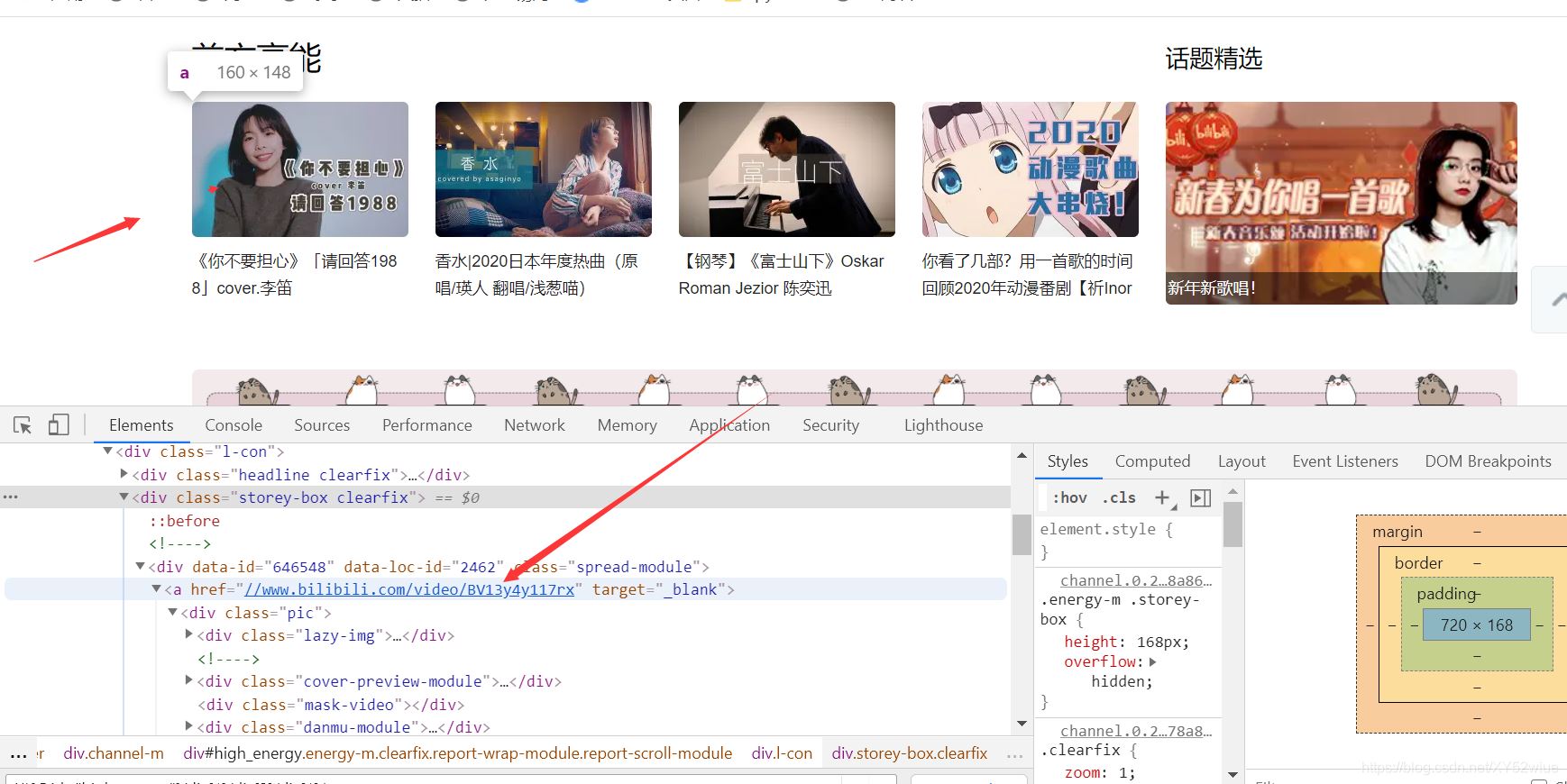
查看这href元素,如果是xpath,肯定这么写是没有问题的:
i.find_element_by_xpath('./a/@href')
但你再selenium里面这样写会报错,所以要改成这样
i.find_element_by_xpath('./a').get_attribute('href')
这样方可正确
这是一个小案例,关于爬取b站音乐视频,但我的技术水平有限,无法下载,找不到那个东东
大家如果知道如何下载可以在评论区留言,嘿嘿
import requests
from selenium.webdriver import Chrome,ChromeOptions
#后面越来越多喜欢用函数来实现了
def get_webhot(): #热搜函数
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
url ="https://www.bilibili.com/" # 微博的地址
res = requests.get(url)
#这个就是再后台上面运行那个浏览器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
#这里也要输入
browser = Chrome(options=option)
browser.get(url)
#解析那个web热搜前,按住ctrl+f会在下面出现一个框框,然后改就完事
browser.find_element_by_xpath('//*[@id="primaryChannelMenu"]/span[3]/div/a/span').click()
c = browser.find_elements_by_xpath('//*[@id="high_energy"]/div[1]/div[2]/div')
for i in c:
#这里一定要注意,在selenium中不能像xpath那样写('./a/@href')来获取指定的位置,要报错,只能这么获取,查了很久
detail_url = i.find_element_by_xpath('./a').get_attribute('href')
name = i.find_element_by_xpath('./a/p').get_attribute('title')
detail_page_text = requests.get(url=detail_url,headers = headers).text
print(detail_url,name)
#运行完事
get_webhot()
这是这个结果

加载全部内容