java参数传递原理 一文助你搞懂参数传递原理解析(java、go、python、c++)
crossoverJie 人气:1前言
最近一年多的时间陆续接触了一些对我来说陌生的语言,主要就是 Python 和 Go,期间为了快速实现需求只是依葫芦画瓢的撸代码;并没有深究一些细节与原理。
就拿参数传递一事来说各个语言的实现细节各不相同,但又有类似之处;在许多新手入门时容易搞不清楚,导致犯一些低级错误。
Java
基本类型传递
先拿我最熟悉的 Java 来说,我相信应该没人会写这样的代码:
@Test
public void testBasic() {
int a = 10;
modifyBasic(a);
System.out.println(String.format("最终结果 main a==%s", a));
}
private void modifyBasic(int aa) {
System.out.println(String.format("修改之前 aa==%s", aa));
aa = 20;
System.out.println(String.format("修改之后 aa==%s", aa));
}
输出结果:
修改之前 aa==10
修改之后 aa==20
最终结果 main a==10
不过从这段代码的目的来看应该是想要修改 a 的值,从直觉上来说如果修改成功也是能理解的。
至于结果与预期不符合的根本原因是理解错了参数的值传递与引用传递。
在这之前还是先明确下值传递与引用传递的区别:

这里咱们先抛出结论,Java 采用的是值传递;这样也能解释为什么上文的例子没有成功修改原始数据。
参考下图更好理解:

当发生函数调用的时候 a 将自己传入到 modifyBasic 方法中,同时将自己的值复制了一份并赋值给了一个新变量 aa 从图中可以看出这是 a 和 aa 两个变量没有一毛钱关系,所以对 aa 的修改并不会影响到 a。
有点类似于我把苹果给了老婆,她把苹果削好了;但我手里这颗并没有变化,因为她只是从餐盘里拿了一颗一模一样的苹果削好了。
如果我想要她那颗,只能让她把削好的苹果给我;也就类似于使用方法的返回值。
a = modifyBasic(a);
引用类型传递
下面来看看引用类型的传递:
private class Car{
private String name;
public Car(String name) {
this.name = name;
}
@Override
public String toString() {
return "Car{" +
"name='" + name + '\'' +
'}';
}
}
@Test
public void test01(){
Car car1 = new Car("benz");
modifyCar1(car1);
System.out.println(String.format("最终结果 main car1==%s", car1));
}
private void modifyCar1(Car car){
System.out.println(String.format("修改之前 car==%s", car));
car.name = "bwm";
System.out.println(String.format("修改之后 car==%s", car));
}
在这个例子里先创建了一个 benz 的 car1,通过一个方法修改为 bmw 那最开始的 car1 会受到影响嘛?
修改之前 car==Car{name='benz'}
修改之后 car==Car{name='bwm'}
最终结果 main car1==Car{name='bwm'}
结果可能会与部分人预期相反,这样的修改却是可以影响到原有数据的?这岂不是和值传递不符,看样子这是引用传递吧?
别急,通过下图分析后大家就能明白:
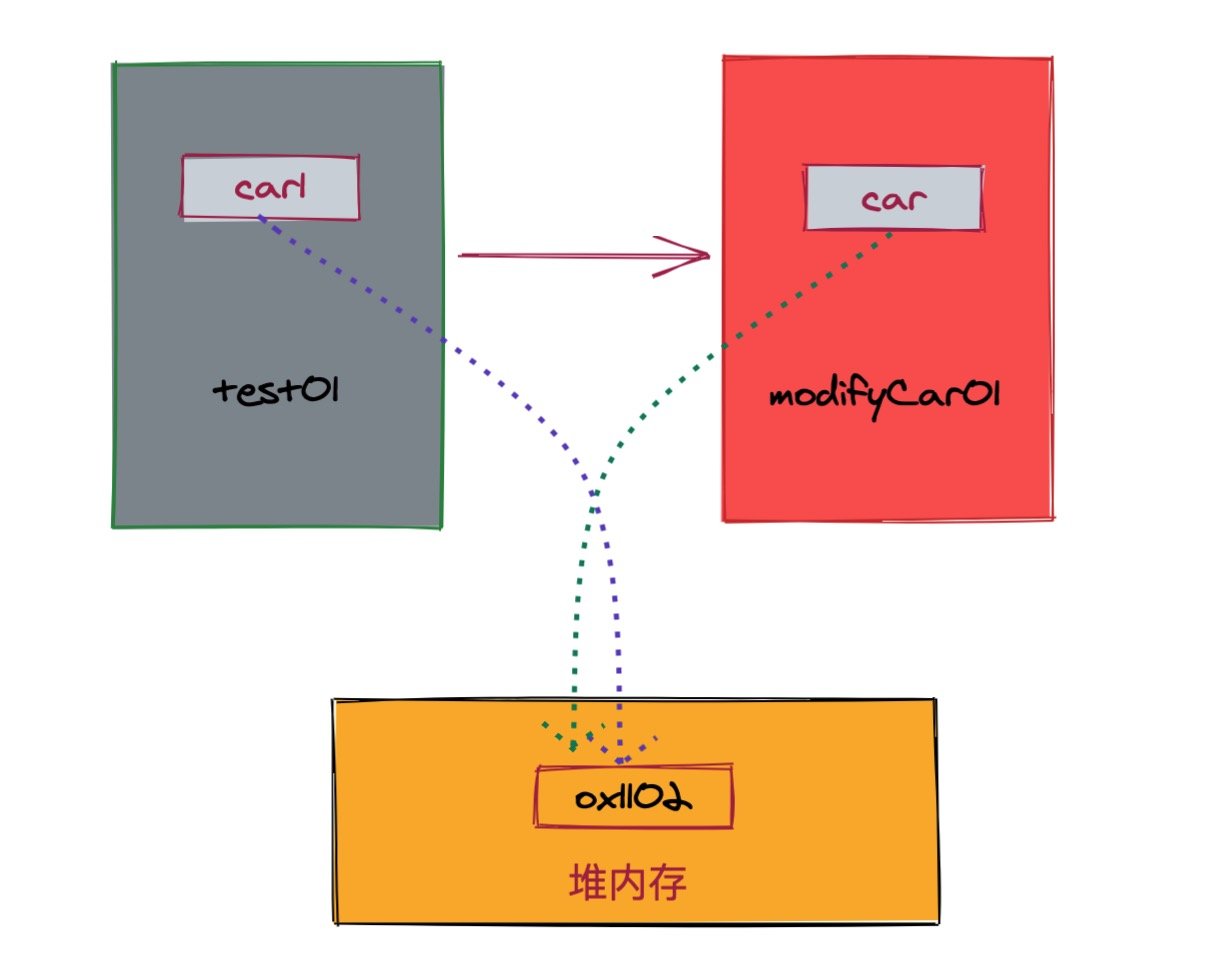
在 test01 方法中我们创建了一个 car1 的对象,该对象存放于堆内存中,假设内存地址为 0x1102 ,于是 car1 这个变量便应用了这块内存地址。
当我们调用 modifyCar1 这个方法的时候会在该方法栈中创建一个变量 car ,接下来重点到了:
这个 car 变量是由原本的入参 car1 复制而来,所以它所对应的堆内存依然是 0x1102;
所以当我们通过 car 这个变量修改了数据后,本质上修改的是同一块堆内存中的数据。从而原本引用了这块内存地址的 car1 也能查看到对应的变化。
这里理解起来可能会比较绕,但我们记住一点就行:
传递引用类型的数据时,传递的并不是引用本身,依然是值;只是这个值 是内存地址罢了。
因为把相同的内存地址传过去了,所以对数据的操作依然会影响到外部。
所以同理,类似于这样的代码也会影响到外部原始数据:
@Test
public void testList(){
List<Integer> list = new ArrayList<>();
list.add(1);
addList(list);
System.out.println(list);
}
private void addList(List<Integer> list) {
list.add(2);
}
[1, 2]
那如果是这样的代码:
@Test
public void test02(){
Car car1 = new Car("benz");
modifyCar(car1);
System.out.println(String.format("最终结果 main car1==%s", car1));
}
private void modifyCar(Car car2) {
System.out.println(String.format("修改之前 car2==%s", car2));
car2 = new Car("bmw");
System.out.println(String.format("修改之后 car2==%s", car2));
}
假设 Java 是引用传递那最终的结果应该是打印 bmw 才对。
修改之前 car2==Car{name='benz'}
修改之后 car2==Car{name='bmw'}
最终结果 main car1==Car{name='benz'}
从结果又能佐证这里依然是值传递。

如果是引用传递,原本的 0x1102 应该是被直接替换为新创建的 0x1103 才对;而实际情况如上图所示,car2 直接重新引用了一个对象,两个对象之间互不干扰。
Go
相对于 Java 来说 Go 的用法又有所不同,不过我们也可以先得出结论:
Go语言的参数也是值传递。
在 Go 语言中数据类型主要有以下两种:
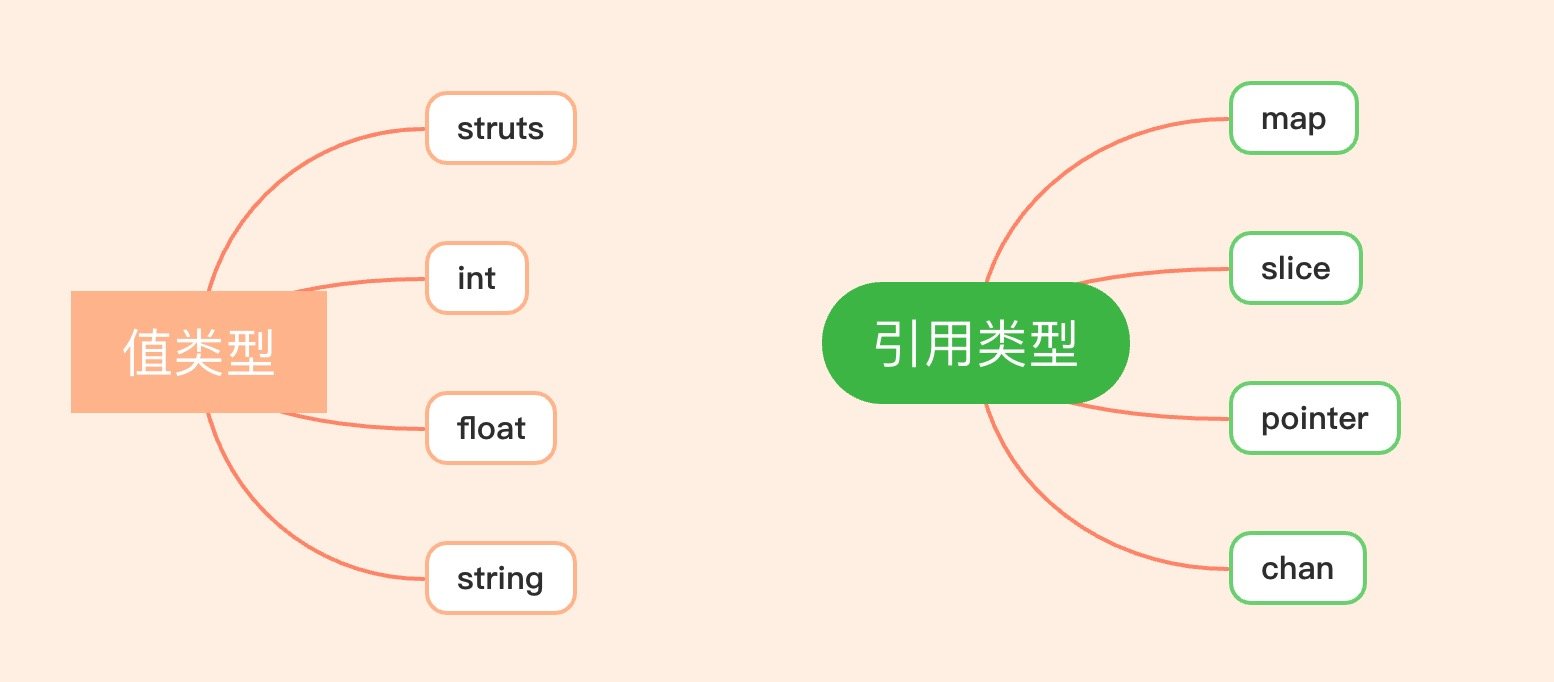
值类型与引用类型;
值类型
先以值类型举例:
func main() {
a :=10
modifyValue(a)
fmt.Printf("最终 a=%v", a)
}
func modifyValue(a int) {
a = 20
}
输出:最终 a=10
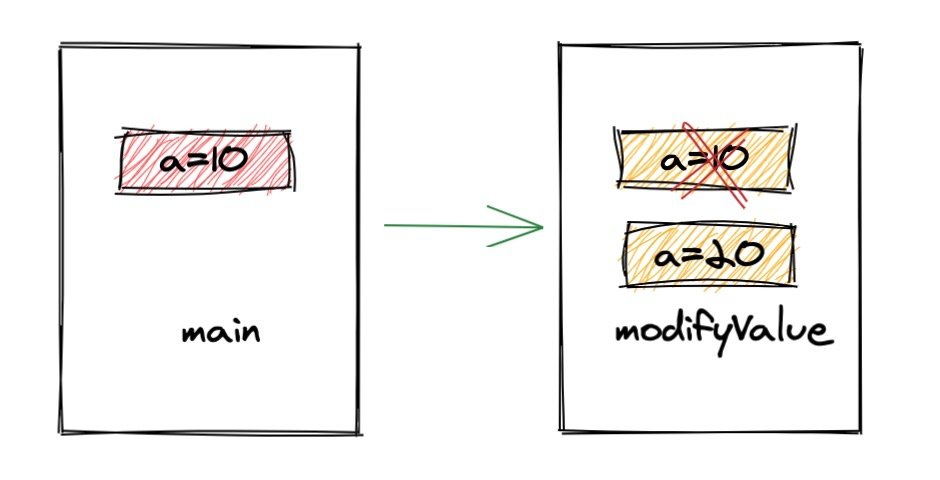
函数调用过程与之前的 Java 类似,本质上传递到函数中的值也是 a 的拷贝,所以对其的修改不会影响到原始数据。
当我们把代码稍加修改:
func main() {
a :=10
fmt.Printf("传递之前a的内存地址%p \n", &a)
modifyValue(&a)
fmt.Printf("最终 a=%v", a)
}
func modifyValue(a *int) {
fmt.Printf("传递之后a的内存地址%p \n", &a)
*a = 20
}
传递之前a的内存地址0xc0000b4040
传递之后a的内存地址0xc0000ae020
最终 a=20
从结果来看最终 a 的值是被方法修改了,这点便是 Go 与 Java 很大的不同点:
在 Go 中存在着指针的概念,我们可以将变量通过指针的方式传递到不同的方法中,在方法里便可通过这个指针访问甚至修改原始数据。
那这么一看不就是引用传递嘛?
其实不然,我们仔细看看刚才的输出会发现参数传递前后的内存地址并不相同。
传递之前a的内存地址0xc0000b4040 传递之后a的内存地址0xc0000ae020
这也恰好论证了值传递,因为这里实际传递的是指针的拷贝。
也就是说 modifyValue 方法中的参数与入参的&a都是同一块内存的指针,但指针本身也是需要内存来存放的,所以在方法调用过程中新建了一个指针 a ,从而导致他们的内存地址不同。
虽然内存地址不同,但指向的数据都是同一块,所以方法内修改后原始数据也受到了影响。
引用类型
对于 map slice channel 这类引用类型又略有不同:
func main() {
var personList = []string{"张三","李四"}
modifySlice(personList)
fmt.Printf("slice=%v \n", personList)
}
func modifySlice(personList []string) {
personList[1] = "王五"
}
slice=[张三 王五]
最终我们会发现原始数据也被修改了,但我们并没有传递指针;同样的特性也适用于 map 。
但其实我们查看 slice 的源码会发现存放数据的 array 就是指针类型:
type slice struct {
array unsafe.Pointer
len int
cap int
}
所以我们可以直接对数据进行修改,相当于间接的带了指针。
使用建议
那我们在什么时候使用指针呢?有以下几点建议:
如果参数是基本的值类型,比如 int,float 建议直接传值。如果需要修改基本的值类型,那只能是指针;但考虑到代码可读性还是建议将修改后的值返回用于重新赋值。数据量较大时建议使用指针,减少不必要的值拷贝。(具体多大可以自行判断)
Python
在 Python 中变量是否可变是影响参数传递的重要因素:

如上图所示,bool int float 这些不可变类型在参数传递过程中是不能修改原始数据的。
if __name__ == '__main__':
x = 1
modify(x)
print('最终 x={}'.format(x))
def modify(val):
val = 2
最终 x=1
原理与 Java Go中类似,是基于值传递的,这里就不再复述。
这里重点看看可变数据类型在参数传递中的过程:
if __name__ == '__main__':
x = [1]
modify(x)
print('最终 x={}'.format(x))
def modify(val):
val.append(2)
最终 x=[1, 2]
最终数据受到了影响,那么就表明这是引用传递嘛?再看个例子试试:
if __name__ == '__main__':
x = [1]
modify(x)
print('最终 x={}'.format(x))
def modify(val):
val = [1, 2, 3]
最终 x=[1]
显而易见这并不是引用传递,如果是引用传递最终 x 应当等于 [1, 2 ,3] 。
从结果来看这个传递过程非常类似 Go 中的指针传递,val 拿到的也是 x 这个参数内存地址的拷贝;他们都指向了同一块内存地址。
所以对这块数据的修改本质上改的是同一份数据,但一旦重新赋值就会创建一块新的内存从而不会影响到原始数据。

与 Java 中的上图类似。
所以总结下:
- 对于不可变数据:在参数传递时传递的是值,对参数的修改不会影响到原有数据。
- 对于可变数据:传递的是内存地址的拷贝,对参数的操作会影响到原始数据。
这么说来这三种都是值传递了,那有没有引用传递的语言呢?
当然,C++是支持引用传递的:
#include <iostream>
using namespace std;
class Box
{
public:
double len;
};
void modify(Box& b);
int main ()
{
Box b1;
b1.len=100;
cout << "调用前,b1 的值:" << b1.len << endl;
modify(b1);
cout << "调用后,b1 的值:" << b1.len << endl;
return 0;
}
void modify(Box& b)
{
b.len=10.0;
Box b2;
b2.len = 999;
b = b2;
return;
}
调用前,b1 的值:100
调用后,b1 的值:999
可以看到把新对象 b2 赋值给入参 b 后是会影响到原有数据的。
总结
其实这几种语言看下来会发现他们中也有许多相似之处,所以通常我们在掌握一门语言后也能快速学习其他语言。
但往往是这些基础中的基础最让人忽略,希望大家在日常编码时能够考虑到这些基础知识多想想一定会写出更漂亮的代码(bug)。
加载全部内容