Java 输入流read(byte[] b) Java 输入流中的read(byte[] b)方法详解
Rrrrrandom 人气:0我就废话不多说了,大家还是直接看代码吧~
public int read(byte[] b) throws IOException
从一个输入流中读取一定数量的字节,并将这些字节存储到其缓冲作用的数组b中。这个函数会返回一次性读取的字节数。
这个函数是一个阻塞式的函数,当它读到有效数据、确认的文件尾(EOF)或者抛出一个异常时它才会执行其他语句,否则一直停在read()函数处等待。
比如下面的列子:
ServerSocket server = new ServerSocket(port) Socket client = server.accept(); BufferedInputStream bis = new BufferedInputStream(client.getInputStream);
byte[] box = new byte[1024];
int len = 0;
while(-1!=(len = bis.read(box))) {
System.out.println(len);
String msg = new String(box, 0, len);
}语句1;语句二;
在这种情况下,当从客户端接收了一条信息并转成msg字符串后,while循环会又回到read()函数,不会跳出循环执行语句一和二。
因为这时read()函数并没有遇到文件尾或者抛出异常,所以下一次while条件判断read()函数会一直等待有效数据的输入,而不是返回-1。此时整个程序将会阻塞在这里。
如果我们是从文件用这个函数以这种while循环方式读取数据的话并不会遇到这个问题,因为读到最后会遇到EOF的。
如果用这种方式读取控制台的输入的话,我们可以选择不要while循环。或者设置条件跳出循环,即如果len小于box的长度话就跳出循环。
我们还可以选择用DataInputStream的readUTF()函数也可以。还有就是我们可以采用监听机制,当监听到输入流中有数据之后再读取。
补充:教你完全理解IO流里的 read(),read(byte[]),read(byte[],int off,int len)以及write
好的我们先来讲它们的作用,然后再用代码来实现给大家看
read():
1.从读取流读取的是一个一个字节
2.返回的是字节的(0-255)内的字节值
3.读一个下次就自动到下一个,如果碰到-1说明没有值了.
read(byte[] bytes)
1.从读取流读取一定数量的字节,如果比如文件总共是102个字节
2.我们定义的数组长度是10,那么默认前面10次都是读取10个长度
3.最后一次不够十个,那么读取的是2个
4.这十一次,每次都是放入10个长度的数组.
read(byte[] bytes,int off ,int len)
1.从读取流读取一定数量的字节,如果比如文件总共是102个字节
2.我们定义的数组长度是10,但是这里我们写read(bytes,0,9)那么每次往里面添加的(将只会是9个长度),就要读12次,最后一次放入3个.
3.所以一般读取流都不用这个而是用上一个方法:read(byte[]);
下面讲解write
write(int i);
直接往流写入字节形式的(0-255)int值.
write(byte[] bytes);
往流里边写入缓冲字节数组中的所有内容,不满整个数组长度的”空余内容”也会加入,这个下面重点讲,
write(byte[] bytes,int off,int len);
1.这个是更严谨的写法,在外部定义len,然后每次len(为的是最后一次的细节长度)都等于流往数组中存放的长度
2.如上述read(bytes),前面每次都放入十个,第十一次放入的是2个,如果用第二种write(bytes),将会写入输出流十一次,每次写入十个长度,造成后面有8个空的,比原来的内容多了
3.所以用write(byte[] bytes,int off,int len);就不会出现多出来的空的情况,因为最后一次len不同
下面是详细的代码
public class Test{
public static void main(String[] args) throws Exception {
UseTimeTool.getInstance().start();
FileInputStream fis = new FileInputStream("D:\\1.mp3");
FileOutputStream fos = new FileOutputStream("D:\\1copy.mp3");
//(PS:一下3个大家分开来写和测试,为了方便我都列出来了)
/*--------------不使用缓冲--------------*/
//如果不缓冲,花了差不多14"秒"
int len = -1;
while ((len = fis.read()) != -1) {
//这里就不是长度的问题了,而是读取的字节"内容",读到一个写一个,相当慢.
System.out.println("len : "+ len);
fos.write(len);
}
/*--------------使用缓冲--------------*/
//缓冲方法复制歌曲用了不到20"毫秒"
//创建一个长度为1024的字节数组,每次都读取5kb,目的是缓存,如果不用缓冲区,用fis.read(),就会效率低,一个一个读字节,缓冲区是一次读5000个
byte[] bytes = new byte[1024*5];
//每次都是从读取流中读取(5k)长度的数据,然后再写到文件去(5k的)数据,注意,每次读取read都会不同,是获取到下一个,直到后面最后一个.
while (fis.read(bytes)!=-1) {
//write是最追加到文件后面,所以直接每次添5K.
fos.write(bytes);
}
/*--------------解释len--------------*/
//告诉你为什么用len
byte[] bytes = new byte[1024*5];
int len = -1;
//解释这个fis.read(bytes)的意思:从读取流"读取数组长度"的数据(打印len可知),并放入数组
while ((len = fis.read(bytes,0,1024)) != -1) {
//虽然数组长度的*5,但是这里我们设置了1024所以每次输出1024
System.out.println("len : "+ len);
//因为每次得到的是新的数组,所以每次都是新数组的"0-len"
fos.write(bytes,0,len);
}
fis.close();
fos.close();
UseTimeTool.getInstance().stop();
}
}
为了方便大家,也给大家一个统计时间的工具类
class UseTimeTool {
private static UseTimeTool utt = new UseTimeTool();
private UseTimeTool() {
}
public static UseTimeTool getInstance() {
return utt;
}
private long start;
public void start() {
start = System.currentTimeMillis();
}
public void stop() {
long end = System.currentTimeMillis();
System.out.println("所用時間 : " + (end - start) + "毫秒");
}
}
好了最后一个:len问题 最后多出数组不满的部分我特再写一个出来给大家分析
首先,文本的内容是

public class Test{
public static void main(String[] args) throws Exception {
UseTimeTool.getInstance().start();
FileInputStream fis = new FileInputStream("D:\\a.txt");
FileOutputStream fos = new FileOutputStream("D:\\acopy.txt");
不使用len:
byte[] bytes = new byte[1024*5];
while (fis.read(bytes)!=-1) {
fos.write(bytes);
}
得到的效果:

发现后续后很多的空部分,所以说不严谨
使用len:
byte[] bytes = new byte[1024*5];
int len = -1;
while ((len = fis.read(bytes,0,1024)) != -1) {
fos.write(bytes,0,len);
}
得到的效果
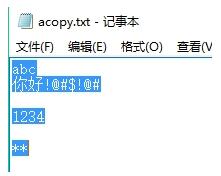
和原来一模一样,讲了那么多就是希望能帮助大家真正的理解。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
加载全部内容