Azure Table Storage(一) : 简单介绍
LeoLaw 人气:0Azure Table Storage是什么:

Azure Table Storage是隶属于微软Azure Storage这个大服务下的一个子服务, 这个服务在Azure上算是老字号了, 个人大概在2013年的时候就已经用过了(那会还叫Windows Azure的年代).
也算是微软Azure上最早的NoSql服务之一(那会NoSql也才开始兴起).
Table Storage有大概如下几个我认为比较重要的特点:
①在它约定的设计模式下可以提供(但不保证)较高的性能
②廉价的存储
③NoSql, 任意字段随便存
Table Storage的内部结构:
其大概分为如下几个层次:
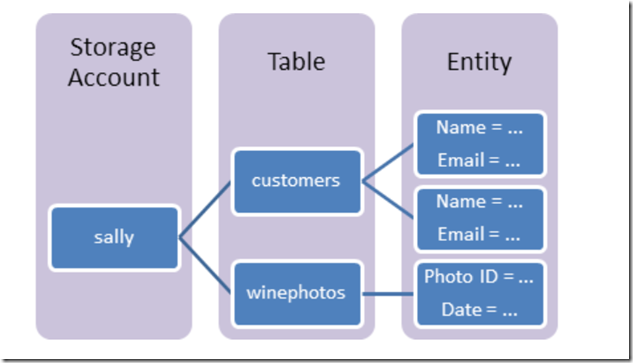
首先是在你的一个Azure Storage下,可以新建多个表.
每个表按照规定会拥有至少3个字段字段:PartitionKey(分区键)/RowKey(行键)/Timestamp(时间戳,注意这个存的是Utc时间).
在上述三个字段之外,你可以自定义任意自己的字段(但是注意一个实体最多1M大小的限制), 而且可以我第一行数据100个字段,第二行数据20个字段,类似这样结构可以自己任意改任意构造.
Table Storage的性能最主要受你自己的表是如何设计的影响
其中最重要的就是如何设计PartitionKey和RowKey, 因为Table Storage内部有且仅有这2个索引.
微软有文章详细阐述各种场景下如何设计 表设计准则
我这里简单的说一下:
PartitionKey是分区键
相同PartitionKey它内部会存储在一起,而不同的PartitionKey则(理论上)存储在不同的地方(如果你分的太多,不同的key有概率也是在一起).
用常规关系型数据库的思维去理解的话,就是这个是它分库分表的依据.
RowKey是行键
在同一个PartitionKey内Rowkey必须是唯一,否则会报错,RowKey是按顺序存储(可以用于排序之类的需求).
用常规关系型数据库的思维去理解的话,Rowkey就是主键(PrimmeryKey).
基于上述的设计,Table Storage的性能大概会呈现出如下几个情况(按照速度由快到慢排序)
①同时命中PartitionKey和RowKey的点查询(都是where =模式)
②对PartitionKey进行点查询(where =)然后对RowKey进行范围查询(where <>)
③对PartitionKey进行点查询(where =)然后对非RowKey的字段进行任意查询(任意where)
④不命中PartitionKey的查询,将触发表扫描,效率将会相当低
一句话总结: 没命中Partitionkey的任意查询都会很慢,RowKey可用于辅助加速.
Table Storage贵吗?
前面说过,Table Storage的存储是廉价的,有多廉价呢:
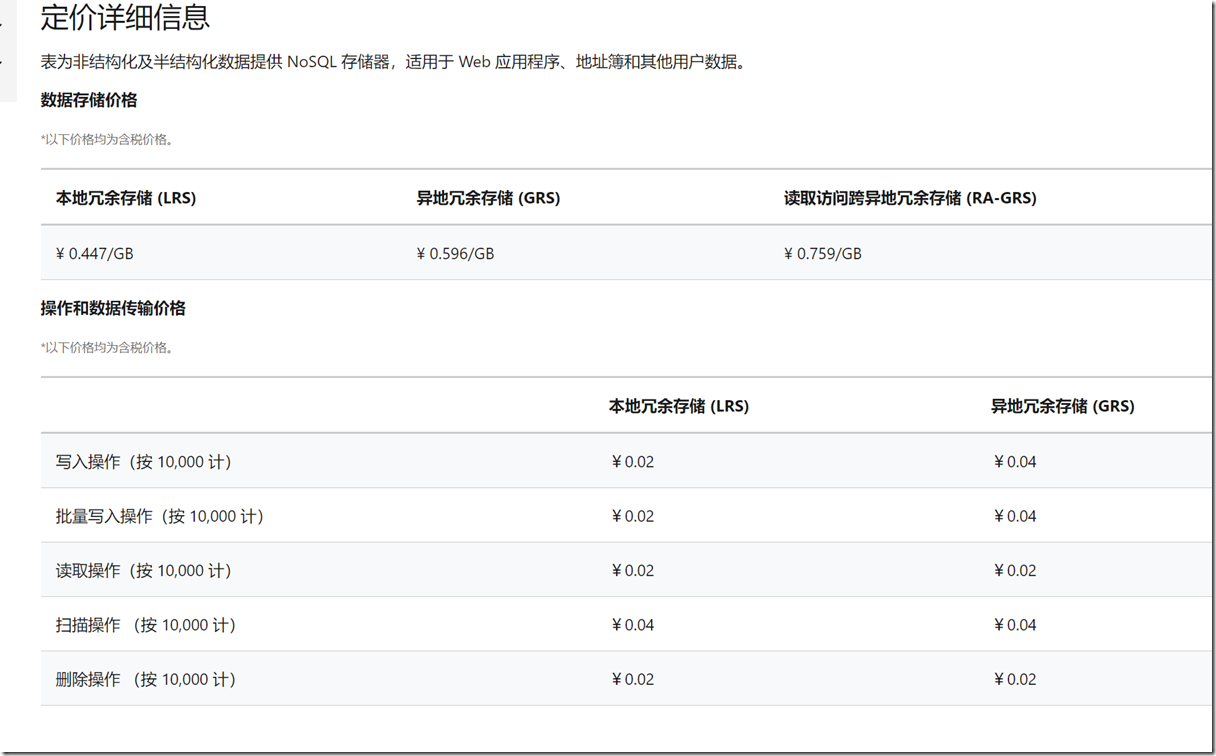
上述价格是Azure世纪互联版(国内版)的价格.
在本地冗余存储的情况下, 4毛5不到一个GB.
4毛5啊, Azure上存东西的服务中比4毛5更低的也就blob那类存文件的了.
但这玩意却提供你一个类似nosql数据库那样子的服务(虽然有点儿约束).
隔壁家其他云的, nosql类型的数据库基本都是mongdb这种级别的, 但是存储成本基本都是几块钱一个G, 而且一般还要额外的计算资源成本(多少核多少内存).
当然关于价格有人还会说还有个操作(写入/读取等)的成本, 但是0.02元1万次, 这是什么概念……
假设你一条数据1kb, 你塞满1g那应该是要 1024 * 1024 = 1,048,576, 然后除以10000后再乘以 0.02, 也就是2块钱左右.
另外Azure是入站流量不收费,所以没有额外的网络有关的费用,上述成本将是你对这个服务要掏的所有成本.
Table Storage能干什么?
一直以来,我自己脑子里都是一种NoSQL的思想.
我的NoSql的意思是 Not Only Sql
诚然传统关系型数据库,其实真的是一个银弹, 只要是”存东西” 活儿它基本都能干.
但是随着时代发展, 虽然它能干这个活, 但它干的并不好.
比如最常见的就是随着现代数据量的暴涨, 在大数据(仅指数据量多)的情况下传统关系型数据库真的有点力不从心.
所以我观点是: 专业的地方找专业的解决方案, 每个地方尽量用上最合适的存储技术.
而Table Storage结合下它几个特点:
限定PartitionKey(潜在RowKey辅助加速)下能有较好性能.
廉价的存储.
首先第一个场景就应用而生了: 记录参数日志
我们想下参数日志的数据有什么特点: 量大, 每条日志的价值点很低, 绝大多数数据都不会被查询, 但是真要用的时候又希望数据不能丢的完整都有.
之前我们参数日志记录到数据库里,由于量过大,基本都是三周一清.
于是乎如果有一个问题活到三周以外的话, 对我们很大概率就是个蛋疼的问题了(一个核心日志缺失,排查难度+++).
而2020年我们开始将参数日志且到Table之后, 妈妈再也不用担心我的数据量问题拉.
关于这个日志的事情, 后续会在第二篇章再写一篇博客出来详细介绍下我们基于Table如何解决我们的的日志问题的设计体系.
第二个场景还在构思中, 就是能否用来存储类似GPS之类的轨迹数据
GPS的设备Id作为PartitionKey, 然后时间是RowKey, 那么我要查这个GPS信息时候大概率可以通过 “对PartitionKey进行点查询(where =)然后对RowKey进行范围查询(where <>)”的模式进行快速查找.
Table Storage怎么用:
我觉得作为一个软系的程序员, 每当问到软家产品怎么用的时候,我总是会说出: docs.microsoft.com
别人写的比绝大多数人写的都更加的专业.
我就不赘述了.
传送门: .Net SDK使用Table Storage
另:
后面微软出的CosmosDb里也包含了一个Table Api
这个是和Azure Storage里的Table是兼容的, 两者的关系官方上有对比.
使用 Azure 表存储 API 和 Azure Cosmos DB 进行开发

我简单挑几个我认为重点的区别说下:
CosmosDB的更贵,(每GB存储成本到2块多了),但是能保证性能(也有更快的性能)而且不再像Table那样只有PartitionKey和RowKey是索引, 它是全表索引.
反正就更隔壁家其他云的mongdb之类的差不多了, 只是API用的是同一套而已.
怎么选择看自己场景, 比如我前面说的日志是属于量大但是每个数据的价值相对较低的, 那么应该用Table, 但是如果你数据价值较高且对性能敏感的那么应该要用CosmosDb的.
还是那句话: 专业的地方找专业的解决方案, 每个地方尽量用上最合适的存储技术.
加载全部内容