c# Selenium爬取数据时防止webdriver封爬虫的方法
UP技术控 人气:0这篇文章主要介绍了c# Selenium爬取数据时防止webdriver封爬虫的方法,帮助大家更好的理解和使用c#,感兴趣的朋友可以了解下
背景
大家在使用Selenium + Chromedriver爬取网站信息的时候,以为这样就能做到不被网站的反爬虫机制发现。但是实际上很多参数和实际浏览器还是不一样的,只要网站进行判断处理,就能轻轻松松识别你是否使用了Selenium + Chromedriver模拟浏览器。其中
window.navigator.webdriver
就是很重要的一个。
问题窥探
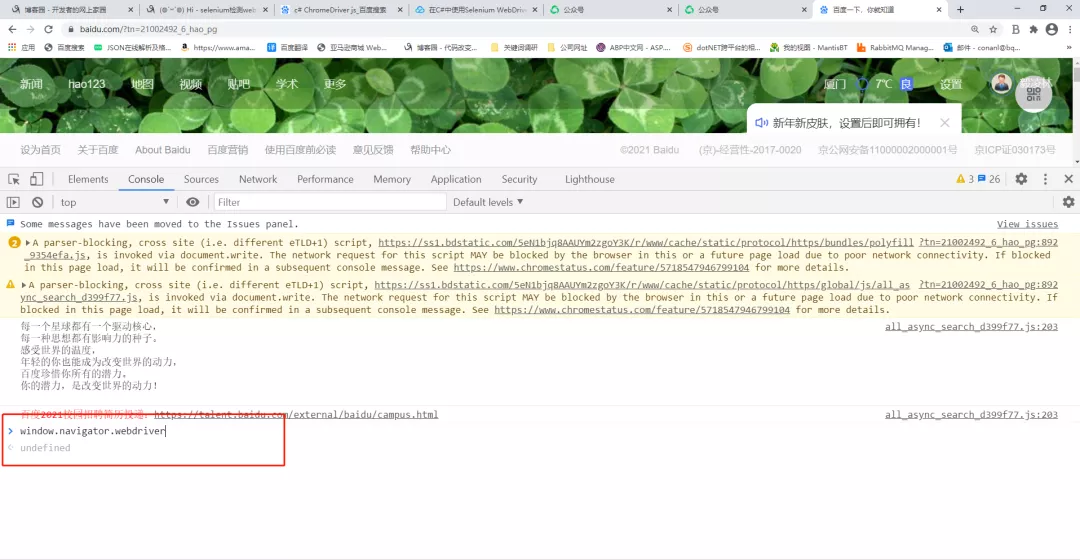
正常浏览器打开是这样的
模拟器打开是这样的
ChromeOptions options = null;
IWebDriver driver = null;
try
{
options = new ChromeOptions();
options.AddArguments("--ignore-certificate-errors");
options.AddArguments("--ignore-ssl-errors");
// options.AddExcludedArgument("enable-automation");
// options.AddAdditionalCapability("useAutomationExtension", false);
var listCookie = CookieHelp.GetCookie();
if (listCookie != null)
{
// options.AddArgument("headless");
}
// string ss = @"{ ""source"": ""Object.defineProperty(navigator, 'webdriver', { get: () => undefined})""}";
// options.AddUserProfilePreference("Page.addScriptToEvaluateOnNewDocument", new ssss() { source = " Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) " });
ChromeDriverService service = ChromeDriverService.CreateDefaultService(System.Environment.CurrentDirectory);
service.HideCommandPromptWindow = true;
driver = new ChromeDriver(service, options, TimeSpan.FromSeconds(120));
////session.Page.AddScriptToEvaluateOnNewDocument(new OpenQA.Selenium.DevTools.Page.AddScriptToEvaluateOnNewDocumentCommandSettings()
////{
//// Source = @"Object.defineProperty(navigator, 'webdriver', { get: () => undefined })"
////}
//// );
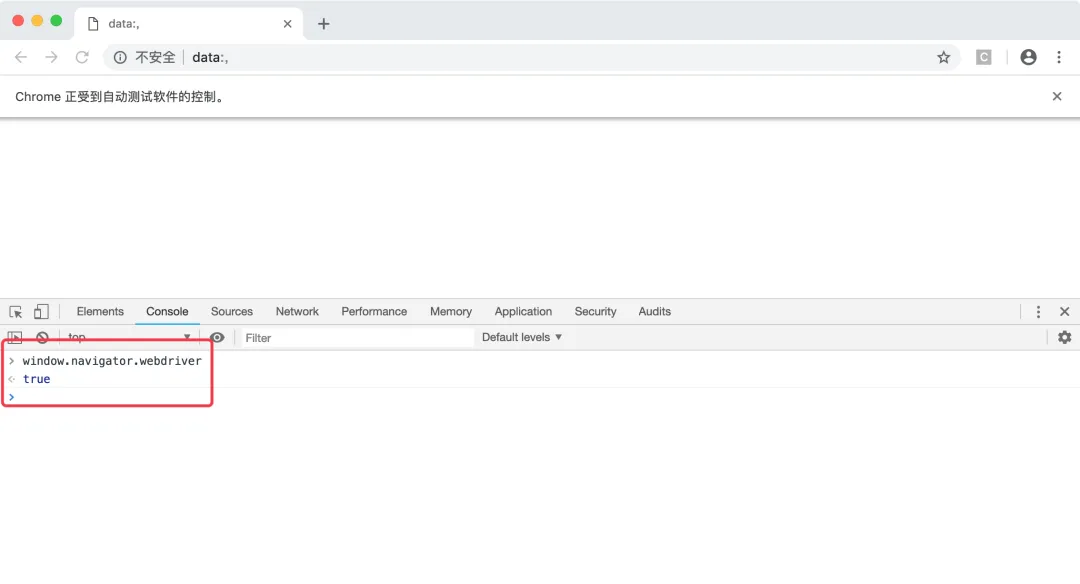
所以,如果网站通过js代码获取这个参数,返回值为undefined说明是正常的浏览器,返回true说明用的是Selenium模拟浏览器。
解决办法
那么对于这种情况,在爬虫开发的过程中如何防止这个参数告诉网站你在模拟浏览器呢?执行对应的js,改掉它的值。
IJavaScriptExecutor js = (IJavaScriptExecutor)driver;
string returnjs = (string)js.ExecuteScript("Object.defineProperties(navigator, {webdriver:{get:()=>undefined}});");
运行效果
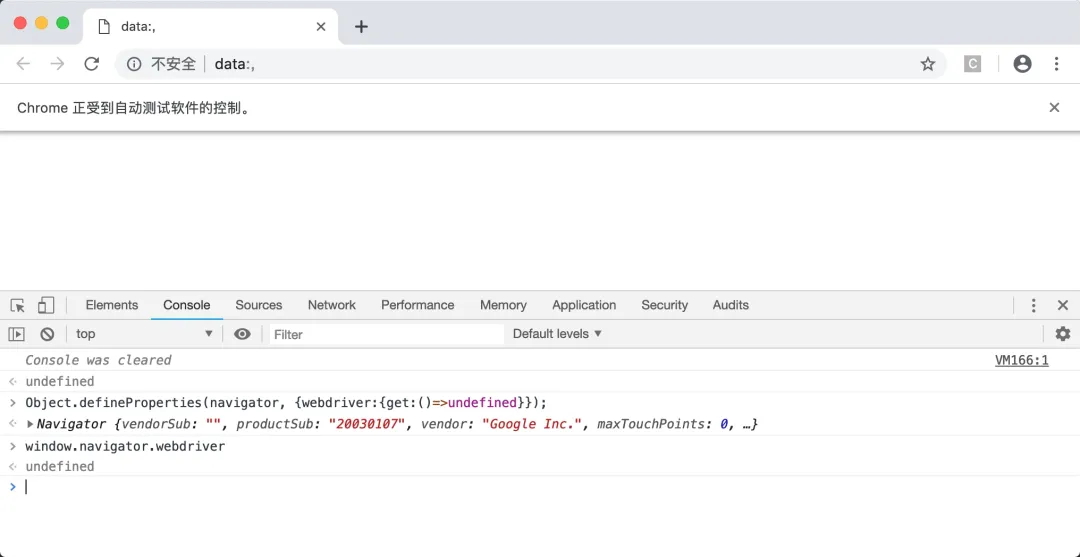
完美,达到预期效果。
加载全部内容