Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
MXuDong 人气:0这篇文章主要介绍了Python爬虫scrapy框架Cookie池(微博Cookie池)的使用,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址)
下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool

下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!!
自己的设置主要有下面几步:
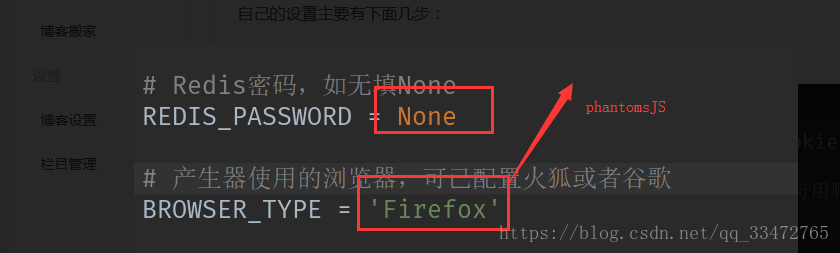
1、配置其他设置

2、设置使用的浏览器

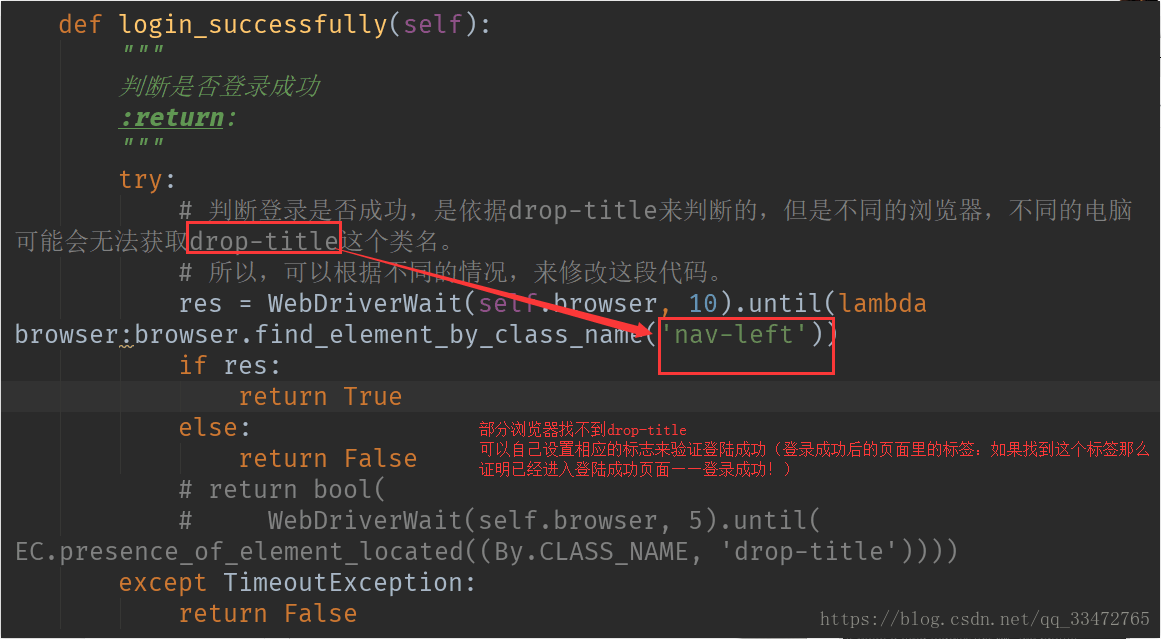
3、设置模拟登陆

源码cookies.py的修改(以下两处不修改可能会产生bug):

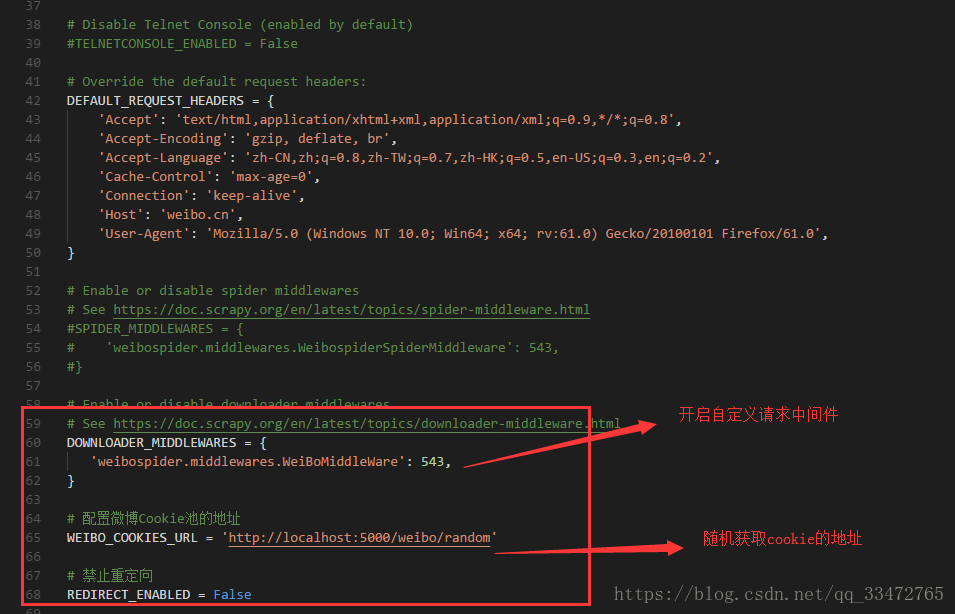
4、获取cookie
随机获取Cookies: http://localhost:5000/weibo/random(注意:cookie使用时是需要后期处理的!!)

简单的处理方式,如下代码(偶尔需要对获取的cookie处理):
def get_cookie(self):
return requests.get('http://127.0.0.1:5000/weibo/random').text
def stringToDict(self,cookie):
itemDict = {}
items = cookie.replace(':', '=').split(',')
for item in items:
key = item.split('=')[0].replace(' ', '').strip(' "')
value = item.split('=')[1].strip(' "')
itemDict[key] = value
return itemDict
scrapy爬虫的使用示例(爬取微博):
middlewares.py中自定义请求中间件
def start_requests(self):
ua = UserAgent()
headers = {
'User-Agent': ua.random,
}
cookies = self.stringToDict(str(self.get_cookie().strip('{|}')))
yield scrapy.Request(url=self.start_urls[0], headers=headers,
cookies=cookies, callback=self.parse)
cookies = self.stringToDict(str(self.get_cookie().strip('{|}')))
yield scrapy.Request(url=self.start_urls[0], headers=headers,
cookies=cookies, callback=self.parse)
settings.py 中的配置:
5、录入账号和密码:

格式规定(账号----密码)

6、验证:(注意:使用cmd)

7、使用时注意保持cmd打开运行!!
使用时一定要打开cmd,并运行如第6步。
得到Cookie是判断是否处理处理Cookie(几乎都需要!!)类比第4步!!!
加载全部内容