python中常用的数据结构介绍
极客算法 人气:0这篇文章主要介绍了python中常用的数据结构介绍,帮助大家更好的理解和学习python的基础知识,感兴趣的朋友可以了解下
栈
# 使用List作为栈 stack = [3, 4, 5] # 入栈 stack.append(6) # 出栈 val = stack.pop() # 栈定元素 val = stack[-1]
队列
队列是FIFO, 但是List对于First Out效率不够高。通常用双端队列Deque来实现队列
Deque的特点是,两端添加和删除都是O(1)的时间复杂度
from collections import deque
queue = deque(["Eric", "John", "Michael"])
# 入队列
queue.append("Terry")
# 出队列
queue.popleft()
元组
与List非常相似,但是Tuple是不可变的数据结构
# 创建, 等号右边可以用括号扩起来 empty = () xyz = 12345, 54321, 'hello!' one = 12345, ## Unpacking x, y, z = xyz x, = one
Tuple内部是可以有List这样可变的元素的
a = [1,2,3] b = [4,5,6] # 创建, 等号右边可以用括号扩起来 t = (a, b) # ([1, 2, 3], [4, 5, 6]) a.append(4) b.append(7) print(t) # ([1, 2, 3, 4], [4, 5, 6, 7])
如果Tuple足够满足,那么Tuple由以下两个优势:
- 元组由于不可修改天然的线程安全
- 元组在占用的空间上面都优于列表
import sys t = tuple(range(2 ** 24)) l = [i for i in range(2 ** 24)] # 比较内存使用 print(sys.getsizeof(t), sys.getsizeof(l))
Tuple创建方式
import timeit
# 从Range转换Tuple 这种速度最快,推荐此方法
timeit.timeit('''t = tuple(range(10000))''', number = 10000)
# 从List创建Tuple
timeit.timeit('''t = tuple([i for i in range(10000)])''', number = 10000)
# 从Range创建Tuple
timeit.timeit('''t = tuple(i for i in range(10000))''', number = 10000)
# Unpacking生成器创建Tuple
timeit.timeit('''t = *(i for i in range(10000)),''', number = 10000)
Range
序列数据结构(List, Tuple, Range)的一种, 常与For循环一起使用
# 0 - 9 val = range(10) val = range(0, 10) val = range(0, 10, 1)
集合
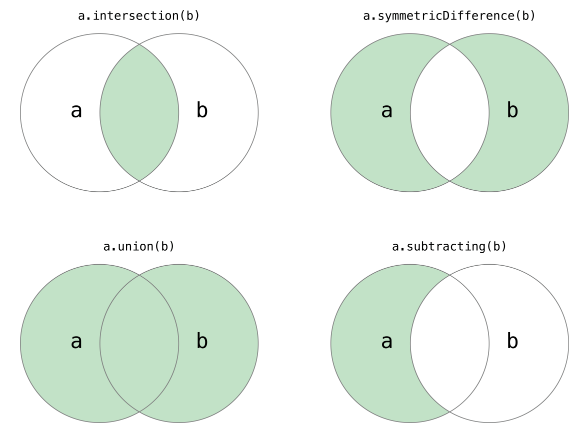
empty = set()
a = {1, 2, 3, 3, 3, 2}
b = {1, 3, 5, 7, 9}
# 超集和子集
a <= b
a.issubset(b)
b.issuperset(a)
# 交集
intersection = a & b
# 并集
union = a | b
# 差
subtraction = a - b
# 对称差
symmetric_difference = a ^ b
字典
字典由(Key: Value)对组成,对于Key的要求是不可变类型(String, Number等),
所以Tuple可以作为Key,但是List却不行。
# {'sape': 4139, 'guido': 4127, 'jack': 4098}
d = dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
# {2: 4, 4: 16, 6: 36}
d = {x: x**2 for x in (2, 4, 6)}
# {'sape': 4139, 'guido': 4127, 'jack': 4098}
d = dict(sape=4139, guido=4127, jack=4098)
但是如果Tuple内包含可变类型,那么也不能作为Key, 会出现如下错误:
TypeError: unhashable type: 'list'
生成式
生成式(List Comprehensions)提供一种简洁的方式创建列表
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] # 创建列表 squares = [] for x in range(10): squares.append(x**2) # 生成式 squares = [x**2 for x in range(10)]
条件语句
# [(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)] [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
使用函数
# ['3.1', '3.14', '3.142', '3.1416', '3.14159'] from math import pi [str(round(pi, i)) for i in range(1, 6)]
生成式嵌套
matrix = [ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], ] # 行列 matrix = [[row[i] for i in range(len(row))] for row in matrix] # 列行 transposed = [[row[i] for row in matrix] for i in range(4)] transposed = list(zip(*matrix))
生成器
生成器与生成式语法相似,只是生成器是懒加载模式,不会立即生成整个列表
import sys # 元素已经就绪,耗费较多的内存 l = [i for i in range(2 ** 24)] print(sys.getsizeof(l)) # 146916504 // 8 = 2 ** 24 # 创建生成器对象, 不占用额外空间,但是需要数据的时候需要内部运算 l = (i for i in range(2 ** 24)) print(sys.getsizeof(l)) # 128
除了上面的生成器语法,还有一种就是通过yield关键字
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
yield a
if __name__ == '__main__':
for val in fib(20):
print(val)
循环
列表循环
l = ['tic', 'tac', 'toe'] for index in range(len(l)) print(index, l[index]) for val in l: print(val) for index, val in enumerate(l): print(index, val)
字典循环
d = {'gallahad': 'the pure', 'robin': 'the brave'}
for key in d:
print(key, d[key])
for key, val in d.items():
print(key, val)
reversed
# [0, 2, 4, 6, 8] for num in range(0, 10, 2): print(num) # [8, 6, 4, 2, 0] for num in reversed(range(0, 10, 2)): print(num)
zip
返回Tuple的迭代器, 第i个元素来自于参数中每一个第i个元素, 长度等于最短的那个参数
加载全部内容