论文解析 -- LeanStore: In-Memory Data Management Beyond Main Memory
fxjwind 人气:0INTRODUCTION
Managing large data sets has always been the raison d’ˆetre (a French expression commonly used in English, meaning "reason for being" or "reason to be") for database systems.
(Buffer Pool的好处和过高的overhead) Traditional systems cache pages using a buffer manager, which has complete knowledge of all page accesses and transparently loads/evicts pages from/to disk.
By storing all data on fixed-size pages, arbitrary data structures, including database tables and indexes, can be handled uniformly and transparently.
While this design succeeds in minimizing the number of I/O operations, it incurs a large overhead for in-memory workloads, which are increasingly common.
(Overhead主要两方面,查hash表,从id到point的转换;锁)
In the canonical(典范的,标准的) buffer pool implementation [1], each page access requires a hash table lookup in order to translate a logical page identifier into an in-memory pointer.
Even worse, in typical implementations the data structures involved are synchronized using multiple latches, which does not scale on modern multi-core CPUs.
As Fig. 1 shows, traditional buffer manager implementations like BerkeleyDB or WiredTiger therefore only achieve a fraction of the TPC-C performance of an in-memory B-tree.
(所以出现内存数据库,但是他们要解决的问题是超出内存的数据的问题)
This is why main-memory database systems like H-Store [2], Hekaton [3], HANA [4], HyPer [5], or Silo [6] eschew(avoid,forgo) buffer management altogether.
Relations as well as indexes are directly stored in main memory and virtual memory pointers are used instead of page identifiers.
This approach is certainly efficient. However, as data sizes grow, asking users to buy more RAM or throw away data is not a viable solution.
Scaling-out an inmemory database can be an option, but has downsides including hardware and administration cost.
For these reasons, at some point of any main-memory system’s evolution, its designers have to implement support for very large data sets.
(内存数据库的局限)Two representative proposals for efficiently managing larger-than-RAM data sets in main-memory systems are Anti-Caching [7] and Siberia [8], [9], [10].
In comparison with a traditional buffer manager, these approaches exhibit one major weakness: They are not capable of maintaining a replacement strategy over relational and index data.
Either the indexes, which can constitute a significant fraction of the overall data size [11], must always reside in RAM,
or they require a separate mechanism, which makes these techniques less general and less transparent than traditional buffer managers.
(SSD的普及让大家重新回到buffer管理)Another reason for reconsidering buffer managers are the increasingly common PCIe/M2-attached Solid State Drives (SSDs), which are block devices that require page-wise accesses.
These devices can access multiple GB per second, as they are not limited by the relatively slow SATA interface.
While modern SSDs are still at least 10 times slower than DRAM in terms of bandwidth, they are also cheaper than DRAM by a similar factor.
Thus, for economic reasons [12] alone, buffer managers are becoming attractive again.
Given the benefits of buffer managers, there remains only one question: Is it possible to design an efficient buffer manager for modern hardware?
(针对上面的问题,我们提出LeanStore,避免查hash表和锁的高效buffer pool结构)
In this work, we answer this question affirmatively(absolutely, undoubtedly) by designing, implementing, and evaluating a highly efficient storage engine called LeanStore .
Our design provides an abstraction of similar functionality as a traditional buffer manager, but without incurring its overhead.
As Fig. 1 shows, LeanStore’s performance is very close to that of an in-memory B-tree when executing TPC-C.
The reason for this low overhead is that accessing an in-memory page merely involves a simple, well-predicted if statement rather than a costly hash table lookup.
We also achieve excellent scalability on modern multicore CPUs by avoiding fine-grained latching on the hot path.
Overall, if the working set fits into RAM, our design achieves the same performance as state-of-the-art main-memory database systems.
At the same time, our buffer manager can transparently manage very large data sets on background storage and, using modern SSDs,
throughput degrades smoothly as the working set starts to exceed main memory.
RELATED WORK
(Buffer管理,经典数据库的基石)Buffer management is the foundational component in the traditional database architecture [13].
In the classical design, all data structures are stored on fixed-size pages in a translation-free manner (no marshalling/unmarshalling,非序列化).
The rest of the system uses a simple interface that hides the complexities of the I/O buffering mechanism and provides a global replacement strategy across all data structures.
Runtime function calls to pinPage /unpinPage provide the information for deciding which pages need to be kept in RAM and which can be evicted to external memory
(based on a replacement strategy like Least-Recently-Used or Second Chance).
This elegant design is one of the pillars of classical database systems.
It was also shown, however, that for transactional, fully memory-resident workloads a typical buffer manager is the biggest source of inefficiency [14].
(内存数据库的主要特征是没有buffer管理)One of the defining characteristics of main-memory databases is that they do not have a buffer manager.
Memory is instead allocated in variable-sized chunks as needed and data structures use virtual memory pointers directly instead of page identifiers.
To support data sets larger than RAM, some main-memory database systems implement a separate mechanism that classifies tuples as either “hot” or “cold”.
Hot tuples are kept in the efficient in-memory database, and cold tuples are stored on disk or SSD (usually in a completely different storage format).
Ma et al. [15] and Zhang et al. [16] survey and evaluate some of the important design decisions.
In the following we (briefly) describe the major approaches.
Anti-Caching [7] was proposed by DeBrabant et al. for H-Store.
Accesses are tracked on a per-tuple instead of a per-page granularity.
To implement this, each relation has an LRU list, which is embedded into each tuple resulting in 8 byte space overhead per tuple.
Under memory pressure, some least-recently-used tuples are moved to cold storage (disk or SSD). Indexes cover both hot as well as cold tuples.
Given that it is not uncommon for indexes to consume half of the total memory in OLTP databases [11], not being able to move indexes to cold storage is a major limitation.
Thus, Anti-Caching merely eases memory pressure for applications that almost fit into main memory and is not a general solution.
(Siberia相对于anti-caching提出一个全面的方案,通过离线分析access log的方式来区分hot和cold,并且有另外的异步线程负责cold数据迁移)
(仅仅对于内存中的hot数据建立索引,冷数据仅仅通过bloomfilter和adaptive range filter来abstract,避免每次查询都需要扫描cold数据)
Microsoft’s Siberia [10] project is maybe the most comprehensive(全面的) approach for managing large data sets in main-memory database systems.
Tuples are classified as either hot or cold in an offline fashion using a tuple access log [8].
Another offline process migrates infrequently accessed tuples between a high-performance in-memory database and a separate cold storage in a transactional fashion [10].
Siberia’s in-memory indexes only cover hot tuples [10] in order to keep these indexes small.
In addition, Bloom filters, which require around 10 bits per key, and adaptive range filters [9] are kept in main memory to avoid having to access the cold storage on each tuple lookup.
The Siberia approach, however, suffers from high complexity (multiple offline processes with many parameters, two independent storage managers), which may have prevented its widespread adoption.
(操作系统自带的page交换的问题)
A very different and seemingly promising(有希望的) alternative is to rely on the operating system’s swapping (paging) functionality.
Stoica and Ailamaki [17], for example, investigated this approach for H-Store.
Swapping has the major advantage that hot accesses incur no overhead due to hardware support (the TLB and in-CPU page table walks).
The disadvantage is that the database system loses control over page eviction, which virtually(实际上,actually) precludes(exclude,排除) in-place updates and full-blown(成熟的) ARIES-style recovery.
(以Redo,Undo日志为核心的事务恢复机制,1992,ARIES: A Transaction Recovery Method Supporting Fine ...)
The problems of letting the operating system decide when to evict pages have been discussed by Graefe et al. [18].
Another disadvantage is that the operating system does not have database-specific knowledge about access patterns (e.g., scans of large tables).
In addition, experimental results (cf. [18] and Fig. 9) show that swapping on Linux, which is the most common server operating system, does not perform well for database workloads.
We therefore believe that relying on the operating system’s swapping/mmap mechanism is not a viable(feasible,可行的) alternative to software-managed approaches.
Indeed, main-memory database vendors recommend to carefully monitor main memory consumption to avoid swapping [19], [20].
An exception are OLAP-optimized systems like MonetDB, for which relying on the operating system works quite well.
Funke et al. [21] proposed a hardware-assisted access tracking mechanism for separating hot and cold tuples in HyPer.
By modifying the Linux kernel and utilizing the processor’s Memory-Management Unit (MMU), page accesses can be tracked with very little overhead.
Their implementation utilizes the same mechanism as the kernel to implement swapping without loosing control over page eviction decisions.
It does not, however, handle index structures.
Our approach, in contrast, is portable as it does not require modifying the operating system and handles indexes transparently.
Combining our approach with hardware-assisted page access tracking would—at the price of giving up portability—improve performance further.
SAP HANA has always been marketed as an in-memory system and, for a long time, a column could only be moved to or from SSD in its entirety(整体) [22].
In a recent paper, Sherkat et al. [22] describe a new feature that enables block-wise access to columnar data .
Indexes and the delta store, however, still reside in main memory, which is a major limitation for large transactional databases.
The fact that practically all in-memory systems have added some form of support for larger-than-RAM data sets clearly shows the importance of this feature.
Yet we argue that the techniques discussed above—despite their originality(独创性)—fall short of (达不到)being robust and efficient solutions
for the cold storage problem in transactional or Hybrid Transactional/Analytical Processing (HTAP) systems.
Adding such a foundational feature to an existing in-memory system as an afterthought (an item or thing that is thought of or added later) will not lead to the best possible design.
We therefore now discuss a number of recent system proposals that were designed as storage managers from their very inception(起始).
Bw-tree/LLAMA [23], [24] is a storage engine optimized for multi-core CPUs and SSDs.
In contrast to our design, updates are performed out-of-place by creating new versions of modified entries (“deltas”).
This design decision has benefits. It enables latch-freedom and, for certain write-intensive workloads, it can reduce SSD write amplification(放大).
The downside is that creating and traversing deltas is a non-negligible(微不足道) overhead.
Performance is therefore lower than that of in-memory systems that perform updates in place.
FOEDUS [25] is another recent storage manager proposal.
It has very good scalability on multi-core CPUs as it avoids unnecessary latch acquisitions, and, like our design, it uses a buffer manager that caches fixed-size pages in main memory.
However, FOEDUS is optimized for byte-addressable Storage Class Memories like Phase Change Memory, which have different properties than SSDs (i.e., byte-addressability).
Pointer swizzling, which is crucial in our design, is an old technique that has been extensively used in object-oriented database systems [26].(序列化和反序列化的时候,对于指针的转换,因为指针地址是动态的不能直接序列化)
Swizzling for buffer managers has only recently been proposed by Graefe et al. [18], who implemented this idea in the page-based Shore-MT system.
Their design shares important characteristics with our proposal.
However, while their approach succeeds in reducing the page translation overhead, it does not address the multi-core scalability issues of page-level latches and mandatory(强制性的) page pinning.
While latch implementations that reduce the cost of contention(争抢) (e.g., MCS locks [27]) exist, these still reduce scalability because of cache invalidations during latch acquisition(获取).
Optimistic locks, in contrast, do not physically acquire the lock and therefore scale even better.
BUILDING BLOCKS(Background)
This section introduces the high-level ideas behind LeanStore, a storage manager for modern hardware (i.e., large DRAM capacities, fast SSDs, and many cores).
Pointer Swizzling
In disk-based database systems, the most important data structures (e.g., heap files, B-tree indexes) are organized as fixed-size pages.
To refer to other pages, data structures store logical page identifiers that need to be translated to memory addresses before each page access.
As shown in Fig. 2a, this translation is typically done using a hash table that contains all pages currently cached in main memory.
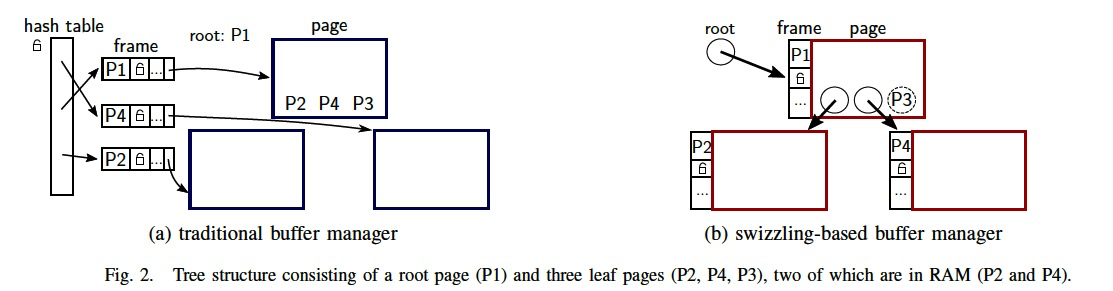
Today, database servers are equipped with main memory capacities large enough to store the working set of most workloads.
As a result, I/O operations are becoming increasingly uncommon and traditional buffer managers often become the performance bottleneck [14].
In our design, pages that reside in main memory are directly referenced using virtual memory addresses (i.e., pointers)— accessing such pages does not require a hash table lookup.
Pages that are currently on background storage, on the other hand, are still referenced by their page identifier.
This is illustrated in Fig. 2b, which shows page references as circles that either contain a pointer or a page identifier.
We use pointer tagging (one bit of the 8-byte reference) to distinguish between these two states.
Consequently, the buffer management overhead of accessing a hot page merely consists of one conditional statement that checks this bit.
This technique is called pointer swizzling [28] and has been common in object databases [29], [26].
A reference containing an in-memory pointer is called swizzled , one that stores an on-disk page identifier is called unswizzled .
Note that even swizzled pages have logical page identifiers, which are, however, only stored in their buffer frames instead of their references.
Efficient Page Replacement
(传统的LRU等Replacement策略,容易导致扩展瓶颈)Pointer swizzling is a simple and highly efficient approach for accessing hot pages.
However, it does not solve the problem of deciding which pages should be evicted to persistent storage once all buffer pool pages are occupied.
Traditional buffer managers use policies like Least Recently Used or Second Chance, which incur additional work for every page access.
Moreover, for frequently accessed pages (e.g., B-tree roots), updating access tracking information (e.g., LRU lists, Second Chance bits) sometimes becomes a scalability bottleneck.
Since our goal is to be competitive with in-memory systems, it is crucial to have a replacement strategy with very low overhead.
This is particularly important with pointer swizzling as it does not suffer from expensive page translation.
We therefore deemed(think,believe) updating tracking information for each page access too expensive and avoid it in our design.
Our replacement strategy reflects a change of perspective: (提出的一个基于随机的,低overhead的置换算法)
Instead of tracking frequently accessed pages in order to avoid evicting them, our replacement strategy identifies infrequently-accessed pages.
We argue that with the large buffer pool sizes that are common today, this is much more efficient as it avoids any additional work when accessing a hot page (except for the if statement mentioned above).
The main mechanism of our replacement strategy is to speculatively(投机的) unswizzle a page reference, but without immediately evicting the corresponding page.
If the system accidentally(偶然的) unswizzled a frequently-accessed page, this page will be quickly swizzled again—without incurring any disk I/O.
Thus, similar to the Second Chance replacement strategy, a speculatively unswizzled page will have a grace period before it is evicted.
Because of this grace period, a very simple (and therefore low-overhead) strategy for picking candidate pages can be used: We simply pick a random page in the pool.
We call the state of pages that are unswizzled but are still in main memory cooling .
At any point in time we keep a certain percentage of pages (e.g., 10%) in this state.
The pages in the cooling state are organized in a FIFO queue.
Over time, pages move further down the queue and are evicted if they reach the end of the queue.
Accessing a page in the cooling state will, however, prevent eviction as it will cause the page to be removed from the FIFO queue and the page to be swizzled.
(置换算法具体步骤)The “life cycle” of a page and its possible states are illustrated in Fig. 3.
Once a page is loaded from SSD, it is swizzled and becomes hot.
A hot page may be speculatively unswizzled and, as a result, transitions to the cooling state.
A cooling page can become either hot (on access) or cold (on eviction).
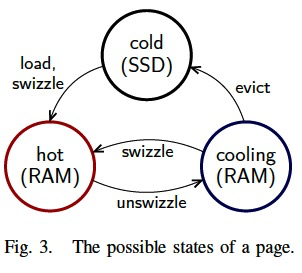
To summarize, by speculatively unswizzling random pages, we identify infrequently-accessed pages without having to track each access.
In addition, a FIFO queue serves as a probational(缓刑的) cooling stage during which pages have a chance to be swizzled.
Together, these techniques implement an effective replacement strategy at low cost.
Scalable Synchronization
(基于latches的同步方案)The design described so far implements the basic functionality of a storage engine but does not support concurrency.
Thread synchronization is tightly coupled with buffer management and therefore cannot be ignored.
For example, before evicting a particular page, the buffer manager has to ensure that this page is not currently being accessed by some other thread.
In most buffer manager implementations, synchronization is implemented using latches.
Every page currently in main memory is associated with a latch.
Additional latches protect the hash table that maps page identifiers to buffer frames.
A call to pinPage will first acquire (and, shortly thereafter, release) one or more latches before latching the page itself.
The page remains latched—and, as a consequence, cannot be evicted—until unpinPage is called.
Note that the page latches serve two distinct purposes:
They prevent eviction and they are used to implement data structure specific synchronization protocols (e.g., lock coupling in B-trees).
(基于latch的问题)Latch-based synchronization is one of the main sources of overhead in traditional buffer managers.
One problem is the sheer number (数量之多)of latch acquisitions.
In Shore-MT, for example, a single-row update transaction results in 15 latch acquisitions for the buffer pool and the page latches [30].
An even larger issue is that some latches are acquired frequently by different threads.
For example, both the latch of a B-tree root and the global latch for the hash table that translates page identifiers are often critical points of contention.
Due to the way cache coherency is implemented on typical multi-core CPUs, such “hot” latches will prevent good scalability (“cacheline ping-pong“).
(LeanStore如何避免锁争抢)As a general rule, programs that frequently write to memory locations accessed by multiple threads do not scale.
LeanStore is therefore carefully engineered to avoid such writes as much as possible by using three techniques:
First, pointer swizzling avoids the overhead and scalability problems of latching the translation hash table.
Second, instead of preventing page eviction by incrementing per-page pinning counters, we use an epoch-based technique that avoids writing to each accessed page.
Third, LeanStore provides a set of optimistic, timestamp-based primitives [31], [32], [33] that can be used by buffer-managed data structures to radically(根本上) reduce the number of latch acquisitions.
Together, these techniques (described in more detail in Section IV-F and Section IV-G) form a general framework for efficiently synchronizing arbitrary(任意的) buffer-managed data structures.
In LeanStore, lookups on swizzled pages do not acquire any latches at all, while insert/update/delete operations usually only acquire a single latch on the leaf node (unless a split/merge occurs).
As a result, performance-critical, in-memory operations are highly scalable.
LEAN STORE
In this section, we describe how LeanStore is implemented using the building blocks presented in Section III.
Data Structure Overview
(传统的buffer管理的数据结构)In a traditional buffer manager, the state of the buffer pool is represented by a hash table that maps page identifiers to buffer frames.
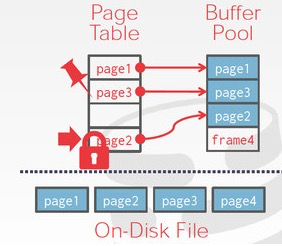
Frames contain a variety of(various) “housekeeping” information, including
(1) the memory pointer to the content of the page,
(2) the state required by the replacement strategy (e.g., the LRU list or the Second Chance bit),
and (3) information regarding(about) the state of the page on disk (e.g., dirty flag, whether the page is being loaded from disk).
These points correspond to 3 different functions that have to be implemented by any buffer manager, namely
(1) determining whether a page is in the buffer pool (and, if necessary, page translation),
(2) deciding which pages should be in main memory, and
(3) management of in-flight I/O operations.
(LeanStore的结构,最大的不同是去掉PageTable,把其中的信息拆分开存,消除全局的争抢点)
LeanStore requires similar information, but for performance reasons, it uses 3 separate, customized data structures.
The upper half of Fig. 4 shows that a traditional page translation table is not needed because its state is embedded in the buffer-managed data structures itself.
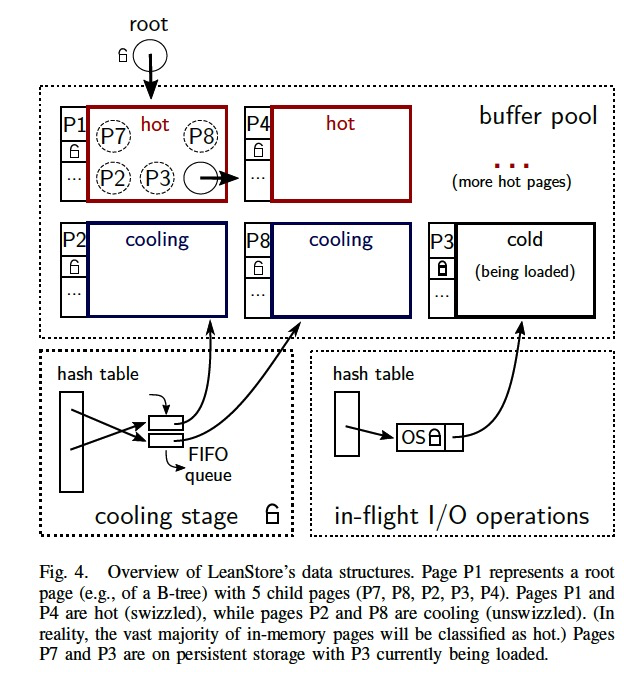
The information for implementing the replacement strategy is moved into a separate structure, which is called cooling stage and is illustrated in the lower-left corner of Fig. 4.
Finally, in-flight I/O operations are managed in yet another structure shown in the lower-right corner of Fig. 4.
Swizzling Details
(引入Swip的概念)Pointer swizzling plays a crucial role in our design.
We call the reference, i.e., the 8-byte memory location referring to a page, a swip .
A swip may either be swizzled (i.e., it stores an in-memory pointer) or unswizzled (i.e., it stores an on-disk page identifier).
In Fig. 4, swips are shown as circles storing either a pointer (arrow) or a page identifier (P. . . ).
While most swips will typically reside on buffer-managed pages, (swips大部分是在buffer page中,除了指向root page的swip在内存中)
some swips, for example the swips pointing to B-tree root pages, are stored in memory areas not managed by the buffer pool.
In the figure, this is the case for the swip labeled as “root”, which is stored outside of the buffer manager.
(第一个design decision)In a traditional buffer manager, the translation table that maps page identifiers to pointers is the single source of truth representing the state of the buffer pool.
Pages are always accessed through this indirection and latches are used for synchronization.
As a result, implementing operations like page eviction is fairly straightforward. (传统的buffer管理,虽然有overhead,但比较直观,LeanStore的方案,去掉中心的 hash table,将数据分散开后,管理更复杂)
In a pointer swizzling scheme, in contrast, the information of the translation table is decentralized and embedded in the buffer-managed data structure itself, which makes things more complicated.
Consider, for example, a page Px that is referenced by the two pages Py and Pz.
In this situation, Px can be referenced by one swizzled and one unswizzled swip at the same time.
Maintaining consistency, in particular without using global latches, is very hard and inefficient.
Therefore, in LeanStore, each page has a single owning swip , which avoids consistency issues when it is (un)swizzled. (为了简化问题,做出约束)
Consequently, each buffer-managed data structure becomes tree-like and the buffer pool in its entirety a forest of pages.
Since each page in the buffer pool is referenced by exactly one swip, we also say a page can be (un)swizzled, depending on the state of the swip referencing it.
(第二个design decision)Another design decision is that we never unswizzle (and therefore never evict) a page that has swizzled children. (只有当所有child都unswizzled,当前节点才能unswizzled;否则如果有child在memory,就会有内存指针,被写入disk是不合理的)
A B-tree inner node, for example, can only be unswizzled (and eventually evicted) if all of its child nodes have been unswizzled.
Otherwise pages containing memory pointers might be written out to disk, which would be a major problem because a pointer is only valid during the current program execution.
To avoid this situation, buffer-managed data structures implement a special swip iteration mechanism that is described in Section IV-E.
It ensures that, if an inner page happens to be selected for speculative(随机的) unswizzling and at least one of its children is swizzled, one of these children is selected instead. (swip迭代机制,当一个节点被选中,但是child中有swizzled的,那么从swizzled的child中挑选一个作为替代)
While this situation is infrequent in normal operation (as there are typically many more leaf pages than inner pages), it needs to be handled for correctness.
Also note that for tree-like data structures, preventing the eviction of a parent before its children is beneficial anyhow, as it reduces page faults(a program attempts to access a block of memory that is not stored in the physical memory)。
Cooling Stage
(buffer pool中的page耗尽的时候,会开始cooling stage过程)The cooling stage is only used when the free pages in the buffer pool are running out.
From that moment on, the buffer manager starts to keep a random subset of pages (e.g., 10% of the total pool size) in the cooling state.
Most of the in-memory pages will remain in the hot state.
Accessing them has very little overhead compared to a pure in-memory system, namely checking one bit of the swip.
(两个结构,FIFO用于按顺序evict page;hashtable用于实时查找cooling的page)As the lower left corner of Fig. 4 illustrates, cooling pages are organized in a FIFO queue.
The queue maintains pointers to cooling pages in the order in which they were unswizzled, i.e., the most recently unswizzled pages are at the beginning of the queue and older pages at the end.
When memory for a new page is needed, the least recently unswizzled page is used (after flushing it if it is dirty).
When an unswizzled swip is about to be accessed (e.g., swip P8 on page P1), it is necessary to check if the referenced page is in the cooling stage.
In addition to the queue, the cooling stage therefore maintains a hash table that maps page identifiers to the corresponding queue entries.
If the page is found in the hash table, it is removed from the hash table and from the FIFO queue before it is swizzled to make it accessible again.
(worker线程同步的进行cooling)Moving pages into the cooling stage could either be done (1) asynchronously by background threads or (2) synchronously by worker threads that access the buffer pool.
We use the second option in order to avoid the risk of background threads being too slow.
Whenever a thread requests a new, empty page or swizzles a page, it will check if the percentage of cooling pages is below a threshold and will unswizzle a page if necessary.
Our implementation uses a single latch to protect the data structures of the cooling stage.
While global latches often become scalability bottlenecks, in this particular case, there is no performance problem.
The latch is only required on the cold path, when I/O operations are necessary.
Those are orders of magnitude more expensive than a latch acquisition and acquire coarse-grained OS-internal locks anyway.
Thus the global latch is fine for both in-memory and I/O-dominated workloads.
Input/Output
Before a cold page can be accessed, it must be loaded from persistent storage.
One potential issue is that multiple threads can simultaneously try to load the same page.
For correctness reasons, one must prevent the same page from appearing multiple times in the buffer pool.
Also, it is obviously more efficient to schedule the I/O operation just once.
Like traditional buffer managers, we therefore manage and serialize in-flight I/O operations explicitly. (管理in-flight,避免重复加载,通过hashtable记录正在加载的pages)
As Fig. 4 (lower-right corner) illustrates, we maintain a hash table for all pages currently being loaded from disk (P3 in the figure).
The hash table maps page identifiers to I/O frames , which contain an operating system mutex and a pointer to a newly allocated page.
A thread that triggers a load first acquires a global latch, creates an I/O frame, and acquires its mutex.
It then releases the global latch and loads the page using a blocking system call (e.g., pread on Unix).
Other threads will find the existing I/O frame and block on its mutex until the first thread finishes the read operation.
We currently use the same latch to protect both the cooling stage and the I/O component.
This simplifies the implementation considerably.
It is important to note, however, that this latch is released before doing any I/O system calls. (仍然要加全局锁,但锁会在进行真正的IO前就释放)
This enables concurrent I/O operations, which are crucial for good performance with SSDs.
Also let us re-emphasize that this global latch is not a scalability bottleneck, because—even with fast SSDs—an I/O operation is still much more expensive than the latch acquisition.
Buffer-Managed Data Structures
(以callback接口的方式,支持任意结构的非侵入的interation,完成unswizzling,如图5)
The main feature of a buffer manager is its support for arbitrary data structures while maintaining a single replacement strategy across the entire buffer pool.
Another advantage is that this is achieved without the need to understand the physical organization of pages (e.g., the layout of B-tree leaves),
which allows implementing buffer-managed data structures without modifying the buffer manager code itself.
In the following we describe how LeanStore similarly supports (almost) arbitrary(任意的) data structures in a non-invasive way(非侵入性的).
As mentioned in Section IV-B, our swizzling scheme requires that child pages are unswizzled before their parents.
To implement this, the buffer manager must be able to iterate over all swips on a page.
In order to avoid having to know the page layout, every buffer-managed data structure therefore implements an “iteration callback”.
When called for a leaf page, this callback simply does nothing, whereas for an inner page, it iterates over all swips stored on that page.
Any buffer-managed data structure must implement this callback and register it with the buffer manager.
In addition, pages must be self-describing, i.e., it needs to be possible to determine which callback function the page is associated with.
For this reason, every page stores a marker that indicates the page structure (e.g., B-tree leaf or B-tree inner node).
Using the callback mechanism, the buffer manager can determine whether a page can be unswizzled.
If a page has no children or all child pages are unswizzled, that page can be unswizzled.
If a swizzled child swip is encountered, on the other hand, the buffer manager will abort unswizzling that node.
Instead, it will try to unswizzle one of the encountered swizzled child pages (randomly picking one of these).
Note that this mechanism, which is illustrated in Fig. 5, implicitly prioritizes inner pages over leaf pages during replacement.
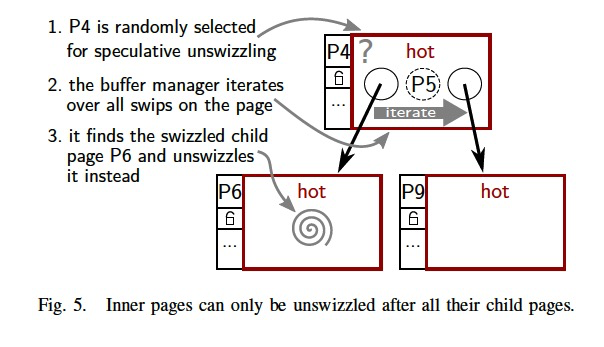
In order to unswizzle a page, besides the callback mechanism, it is also necessary to find the parent page of the eviction candidate.
Our implementation uses parent pointers, which are stored in the buffer frame.
The parent pointers allow one to easily access the parent page when unswizzling and must be maintained by each data structure.
Maintaining these parent pointers is not expensive in our design, because child nodes are always unswizzled before their parents and because parent pointers are not persisted.
(如何解决单个page对应多个swip)As mentioned earlier, in our current implementation every page has one swip, i.e., one incoming reference.
This design decision simplifies bookkeeping for unswizzling and was also made by Graefe et al.’s swizzling-based buffer manager [18].
However, this is not a fundamental limitation of our approach.
An alternative implementation, in which a page can have multiple incoming pointers, would also be possible.
One way to achieve this is to store multiple parent pointers in each frame, which would already be enough to implement inter-leaf pointers in B+ -trees.
A more general approach would be to keep storing only one parent per page, but have two classes of swips.
There would be normal swips that, as in our current design, are linked through parent pointers.
In addition, one would have “fat” swips that contain both the page identifier and a pointer.
While our design does impose some constraints on data structures (fixed-size pages and parent pointers), the internal page layout as well as the structural organization are flexible.
For example, in prior work [34], we developed a hash index that can directly be used on top of LeanStore:
In this data structure, the fixed-size root page uses a number of hash bits to partition the key space (similar to Extendible Hashing).
Each partition is then represented as a space-efficient hash table (again using fixed-size pages).
Heaps can be implemented similar to B-trees using the tuple identifier as a key.
Given that tuple identifiers are often (nearly) dense, one can use special node layouts to avoid the binary search used in B-trees and support very fast scans.
The custom node layout also allows implementing columnar storage and compression.
Optimistic Latches
As Fig. 4 illustrates, each page in the buffer pool is associated with a latch. (看图4,其实每个page都是有latch的)
In principle, it would be possible to implement synchronization similar to that of a traditional buffer manager.
By acquiring per-page latches on every page access, pages are “pinned” in the buffer pool, which prevents their eviction.
Unfortunately, as discussed in Section III-C, requiring frequent latch acquisitions would prevent any buffer-managed data structure from being scalable on multi-core CPUs.
To be competitive with pure in-memory systems (in terms of performance and scalability), for a buffer manager it is therefore crucial to offer means for efficient synchronization.
The first important technique is to replace the conventional per-page latches with optimistic latches [31], [32], [33].
Internally, these latches have an update counter that is incremented after every modification.
Readers can proceed without acquiring any latches, but validate their reads using the version counters instead (similar to optimistic concurrency control).
The actual synchronization protocol is data-structure specific and different variants can be implemented based on optimistic latches.
One possible technique is Optimistic Lock Coupling [33], which ensures consistent reads in tree data structures without physically acquiring any latches during traversal.
Optimistic Lock Coupling has been shown to be good at synchronizing the adaptive radix tree [35], [33] and B-tree [36].
In this scheme, writers usually only acquire one latch for the page that is modified, and only structure modification operations (e.g., splits) latch multiple pages.
Epoch-Based Reclamation
With optimistic latches, pages that are being read are neither latched nor pinned.
This may cause problems if some thread wants to evict or delete a page while another thread is still reading the page. (读不加锁,怎么保证正在被读的page不被evict)
To solve this problem, we adopt an epoch-based mechanism, which is often used to implement memory reclamation(回收) in latch-free data structures [6], [32], [23].
The basic idea is to have one global epoch counter which grows periodically, and per-thread local epoch counters.
These are shown at the right of Fig. 6.
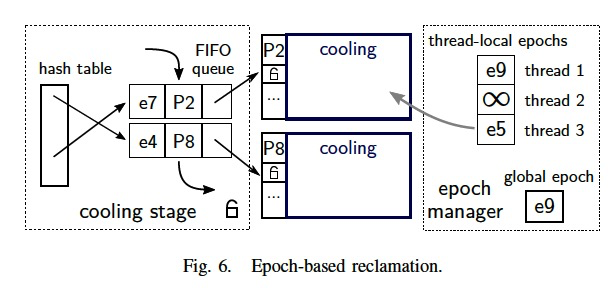
(每次读不加细粒度锁,但是任然需要加epoch级别的粗粒度的锁,首先有个全局的epoch,然后当thread开始读buffer数据前,设置local epoch;当前page被cooling的时候,也会记录epoch)
(当page evict的时候,判断当前的page的cooling epoch要比所有thread的最小的local epoch要大)
Before a thread accesses any buffer-managed data structure, it sets its local epoch to the current global epoch, which conceptually means that the thread has entered that epoch.
In Fig. 6, thread 1 has entered epoch e9, while thread 3 is still in epoch e5. When a thread is finished accessing the data structure,
it sets its local epoch to a special value that indicates that the thread does not access any data at the moment (thread 2 in the example).
When a page is unswizzled, it cannot be reused immediately (as other threads might still be reading from it).
For this reason, we associate pages in the cooling stage with the global epoch at the time of unswizzling.
(Note that only cooling pages need to be associated with an epoch, not hot pages.) In the example in Fig. 6, page P8 was put into the cooling stage during epoch e4, and page P2 in epoch e7.
Right before a page is actually evicted (which happens when the page reaches the end of the FIFO queue), its associated epoch is compared with the minimum of all local epochs.
Only if the minimum is larger than the associated epoch, the page can be safely reused since then it is ensured that no thread can read that page anymore.
Since the minimum observed epoch of all threads in the example is e5, P8 can be safely evicted, while P2 is kept in the cooling stage until after thread 3 is finished with its current operation.
(如何决定global epoch的increase的频率)It is unlikely that this check leads to further delay, since it takes quite some time for a page to reach the end of the FIFO queue.
Checking this condition is, however, necessary for correctness.
Note that incrementing the global epoch very frequently may result in unnecessary cache invalidations in all cores, whereas very infrequent increments may prevent unswizzled pages from being reclaimed in a timely fashion.
Therefore, the frequency of global epoch increments should be proportional to the number of pages deleted/evicted but should be lower by a constant factor (e.g., 100).
(Thread不应该hold一个epoch太长时间,会影响reclaim)To make epochs robust, threads should exit their epoch frequently, because any thread that holds onto its epoch for too long can completely stop page eviction and reclamation.
For example, it might be disastrous to perform a large full table scan while staying in the same local epoch.
Therefore, we break large operations like table scans into smaller operations, for each of which we acquire and release the epoch.
We also ensure that I/O operations, which may take a fairly long time, are never performed while holding on to an epoch.
This is implemented as follows: If a page fault occurs, the faulting thread (1) unlocks all page locks, (2) exits the epoch, and (3) executes an I/O operation.
Once the I/O request finishes, we trigger a restart of the current data structure operation by throwing a C++ exception.
Each data structure operation installs an exception handler that restarts the operation from scratch (i.e., it enters the current global epoch and re-traverses the tree).
This simple and robust approach works well for two reasons:
First, in-memory operations are very cheap in comparison with I/O.
Second, large logical operations (e.g., a large scan) are broken down into many small operations;
after a restart only a small amount of work has to be repeated.
Memory Allocation and NUMA-Awareness
Besides enabling support for larger-than-RAM data sets, a buffer manager also implicitly provides functionality for memory management—similar to a memory allocator for an in-memory system.
Memory management in a buffer pool is simplified, however, due to fixed-size pages (and therefore only a single allocation size).
Buffer-managed systems also prevent memory fragmentation, which often plagues(瘟疫,困扰) long-running in-memory systems.
LeanStore performs one memory allocation for the desired buffer pool size.
This allocation can either be provided physically by the operating system on demand (i.e., first access) or be pre-faulted on startup.
LeanStore also supports Non-Uniform Memory Access (NUMA)-aware allocation in order to improve performance on multi-socket systems.
In this mode, newly allocated pages are allocated on the same NUMA node as the requesting thread.
NUMA-awareness is implemented by logically partitioning the buffer pool and the free lists into as many partitions as there are NUMA nodes.
Besides the buffer pool memory itself, all other data structures (including the cooling stage) are centralized in order to maintain a global replacement strategy.
NUMA-awareness is a best effort optimization: if no more local pages are available, a remote NUMA page will be assigned.
Implementation Details and Optimizations
Let us close this section by mentioning some implementation details and optimizations that are important for performance.
On top of LeanStore, we implemented a fairly straightforward B+-tree (values are only stored in leaf nodes).
The most interesting aspect of the implementation is the synchronization mechanism.
Reads are validated using the version counters embedded into every latch and may need to restart if a conflict is detected. (读不加锁,只做validate)
Range scans that span multiple leaf nodes are broken up into multiple individual lookups by using fence keys [37].
Together with the efficient synchronization protocol, breaking up range lookups obviates the need for the leaf links, which are common in traditional disk-based B+-trees.
An insert, delete, or update operation will first traverse the tree like a lookup, i.e., without acquiring any latches. (update首先需要lookup,不加锁;仅对找到的leaf page加锁)
Once the leaf page that needs to be modified is found, it is latched, which excludes any potential writers (and invalidates potential readers).
If no structure-modifying operation (e.g., a node split) is needed (e.g., there is space to insert one more entry), the operation can directly be performed and the latch can be released. (不改变结构的情况下,IO前可以先释放latch)
Structure-modifying operations release the leaf latch and restart from the root node—but this time latching all affected inner nodes.
In LeanStore, buffer frames are physically interleaved(交错的) with the page content (Fig. 2b). (frame和page内容是存在一起的)
This is in contrast with most traditional buffer managers that store a pointer to the page content in the buffer frame (Fig. 2a).
Interleaving the buffer frames improves locality and therefore reduces the number of cache misses because the header of each page is very frequently accessed. (访问point后,大概率会访问page header,所以放一起更高效)
A second, more subtle(微妙的), advantage of interleaving is that it avoids performance problems caused by the limited CPU cache associativity:
At typical power-of-two(二次幂) page sizes (and without interleaving), the headers of all pages fall into the same associativity set and only a small number of headers can reside in cache (e.g., 8 for the L1 caches of Intel CPUs).
Because we avoid pinning pages, a page cannot be reused immediately after unswizzling it.
This applies not only to pages that are speculatively unswizzled but also to pages that are explicitly deleted (e.g., during a merge operation in a Btree).
One solution is to use the same mechanism described in Section IV-G, i.e., to put the deleted page into the cooling stage.
In our implementation, each thread has a small threadlocal cache for deleted pages .
Just like in the cooling stage, the entries are associated with the epoch (of the moment of their deletion).
When a thread requests a new, empty page, it consults its local cache and, if the global epoch has advanced sufficiently, chooses a page from the local cache instead of the cooling stage.
As a result, deleted pages are reused fairly quickly, which improves cache locality and avoids negative effects on the replacement strategy.
Previously, we argued against asynchronous background processes, because they can cause unpredictable behavior and often have complex, hard-to-tune parameters.
We make one exception for writing out dirty pages in the background.
Like in traditional buffer managers, we use a separate background writer thread to hide the write latency that would otherwise be incurred by worker threads.
Our background writer cyclically traverses the FIFO queue of the cooling stage, flushes dirty pages, and clears the dirty flag.
To enable fast scans, LeanStore implements I/O prefetching.
Using the in-flight I/O component, scans can schedule multiple page requests without blocking.
These I/Os are then executed in the background.
Once a prefetching request is finished, the corresponding page becomes available to other threads through the cooling stage.
Another optimization for large scans is hinting .
Leaf pages accessed by scans can be classified as cooling instead of hot after being loaded from SSD. (Scan访问的page,变成cooling状态,可以更快的evict)
These pages are therefore likely to be evicted quickly.
Also, since the cooling stage size is limited, no hot pages need to be unswizzled.
As a consequence, only a small fraction of the buffer pool will be invalidated during the scan—avoiding thrashing.
加载全部内容