python UDF 实现对csv批量md5加密操作
lee_moonj 人气:0这篇文章主要介绍了python UDF 实现对csv批量md5加密操作,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
工作上遇到需求,一批手机号要md5加密导出。为了保证数据安全,所以没有采用网上工具来加密。
md5的加密算法是开源的且成熟的,很多语言都有对应包可以直接用,我写了一个简单的python来实现,另一位同事做了一个hiveUDF来实现,这里都给大家分享一下。
目标:
读取csv文件,并且对其中的内容进行md5加密,32位加密,将加密后的密文存入另一个csv文件。
python实现:
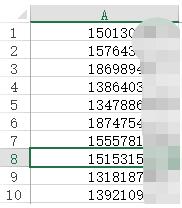
(1)准备好要读取的csv文件。单列,一行存一个手机号码。
(2)python代码:
#encoding=utf8
import hashlib #加密模块
import os
#定义一个加密函数,32位md5加密
def md5_encryption(str):
m=hashlib.md5()
m.update(str)
return m.hexdigest()
#准备要读取的csv和要被写入的csv,两个文件要和此python放在同一个文件夹里
readfilename=os.path.join(os.path.dirname(__file__),"testcsv.csv")
writefilename=os.path.join(os.path.dirname(__file__),"writecsv.csv")
print('read:',readfilename)
print('write:',writefilename)
with open(readfilename,'r') as rf:
#逐行写入加密后的密文,strip函数用于剔除换行符\n,不然是对“13000000\n”加密而不是对“13000000”加密
with open(writefilename,'w') as wf:
for row in rf.readlines():
wf.write(md5_encryption(row.strip()))
wf.write('\n')
#计算一下写入的行数
with open(writefilename,'r') as rwf:
count=0
while 1:
buffer=rwf.read(1024*8192)
if not buffer:
break
count+=buffer.count('\n')
print('line writed number:',count)
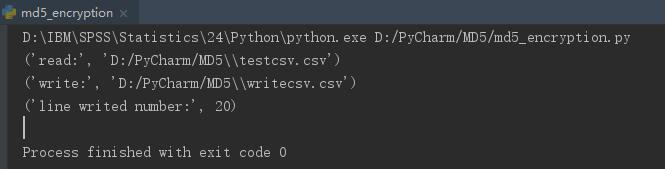
(3)结果

hive UDF 实现:
(1)用java写一个类用来实现加密,用maven打成jar包
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.commons.lang.StringUtils;
import java.security.MessageDigest;
public class MD5 extends UDF {
public String evaluate (final String str) {
if (StringUtils.isBlank(str)){
return "";
}
String digest = null;
StringBuffer buffer = new StringBuffer();
try {
MessageDigest digester = MessageDigest.getInstance("md5");
byte[] digestArray = digester.digest(str.getBytes("UTF-8"));
for (int i = 0; i < digestArray.length; i++) {
buffer.append(String.format("%02x", digestArray[i]));
}
digest = buffer.toString();
} catch (Exception e) {
e.printStackTrace();
}
return digest;
}
public static void main (String[] args ) {
MD5 md5 = new MD5();
System.out.println(md5.evaluate(" "));
}
}
(2)配置一下pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>HiveUdf</groupId> <artifactId>HiveUdf</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>0.14.0</version> </dependency> <dependency> <groupId>org.apache.calcite</groupId> <artifactId>calcite-core</artifactId> <version>0.9.2-incubating</version> </dependency> <dependency> <groupId>org.apache.calcite</groupId> <artifactId>calcite-avatica</artifactId> <version>0.9.2-incubating</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0</version> </dependency> </dependencies> </project>
(3)hive中配置udf
导入jar包:
hive> add jar hdfs:/user/udf/HiveUdf-1.0-SNAPSHOT.jar;
新建一个函数:
hive> create temporary function MD5 as 'MD5';
使用:
hive> select MD5('12345');
OK
827ccb0eea8a706c4c34a16891f84e7b
Time taken: 0.139 seconds, Fetched: 1 row(s)
hive>
hive> select phone,MD5(phone) from mid_latong_20200414 limit 5;
OK
1300****436 856299f44928e90****181b0cc1758c4
1300****436 856299f44928e90****181b0cc1758c4
1300****689 771dfa9ef00f43c****4901a3f1d1fa0
1300****689 771dfa9ef00f43c****4901a3f1d1fa0
1300****689 771dfa9ef00f43c****4901a3f1d1fa0
Time taken: 0.099 seconds, Fetched: 5 row(s)
以上就是python和hiveUDF两种实现md5加密的方法啦!
补充:python的MD5加密的一点坑
曾经在做某ctf题目时,被这点坑,坑了好久。
废话不多说,进入正题。
python MD5加密方法
import hashlib //导入hash库函数 text = "bolg.csdn.net" //要加密的文本 md5_object = hashlib.md5() //创建一个MD5对象 md5_object.update(text) //添加去要加密的文本 print md5_object.hexdigest() //输出加密后的MD5值
坑在哪?
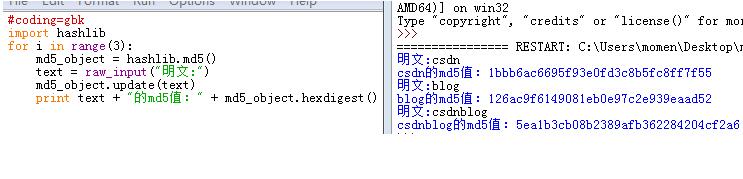
当你在进行第一次加密时,程序正常输出MD5值,但是在同一程序中进行第二次明文加密时,如果你的代码是这样写,就不会得到正确的MD5值。
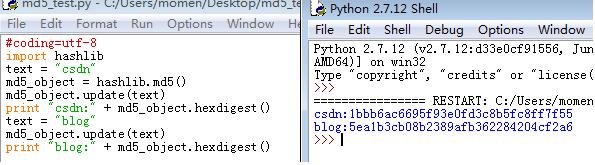
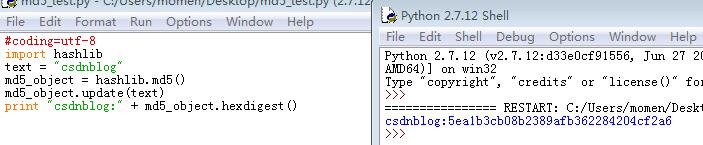
通过对第一张图片和第二张图片的比较,发现如果按照第一张图片的代码进行连续加密时,它实质上是在加密每次明文的叠加。
即第一次加密:csdn
第二次加密:csdnblog
正确做法应该是:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
加载全部内容