Kafka 消费组消费者分配策略
堅持╅信念★ 人气:0微信公众号:苏言论
理论联系实际,畅言技术与生活。
消费组和消费者是kafka中比较重要的概念,理解和掌握原理有利于优化kafka性能和处理消费积压问题。Kafka topic 由多个分区组成,分区分布在集群节点上;
Topic:topic01 PartitionCount:10 ReplicationFactor:2 Configs:
Topic: topic01 Partition: 0 Leader: 1 Replicas: 1,4 Isr: 1,4
Topic: topic01 Partition: 1 Leader: 2 Replicas: 2,5 Isr: 2,5
Topic: topic01 Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: topic01 Partition: 3 Leader: 4 Replicas: 4,2 Isr: 4,2
Topic: topic01 Partition: 4 Leader: 5 Replicas: 5,3 Isr: 5,3
Topic: topic01 Partition: 5 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: topic01 Partition: 6 Leader: 2 Replicas: 2,4 Isr: 2,4
Topic: topic01 Partition: 7 Leader: 3 Replicas: 3,5 Isr: 3,5
Topic: topic01 Partition: 8 Leader: 4 Replicas: 4,1 Isr: 4,1
Topic: topic01 Partition: 9 Leader: 5 Replicas: 5,2 Isr: 5,2
当外部程序消费topic数据时,kafka将其视为消费组(ConsumerGroup),每个消费组包含1个或多个消费者(Consumer),消费者数量最多可以为分区总数量,并不是可以无限量。当消费组中的任意一个消费者终止时,kafka会对消费组进行平衡(Rebalance),再根据存活消费数和消费者分配策略重新分配消费者。在0.10.x版本中,kafka提供两种分配策略(RangeAssignor、RoundRobinAssignor),0.11.x 版本新增策略(StickyAssignor),结构如下;
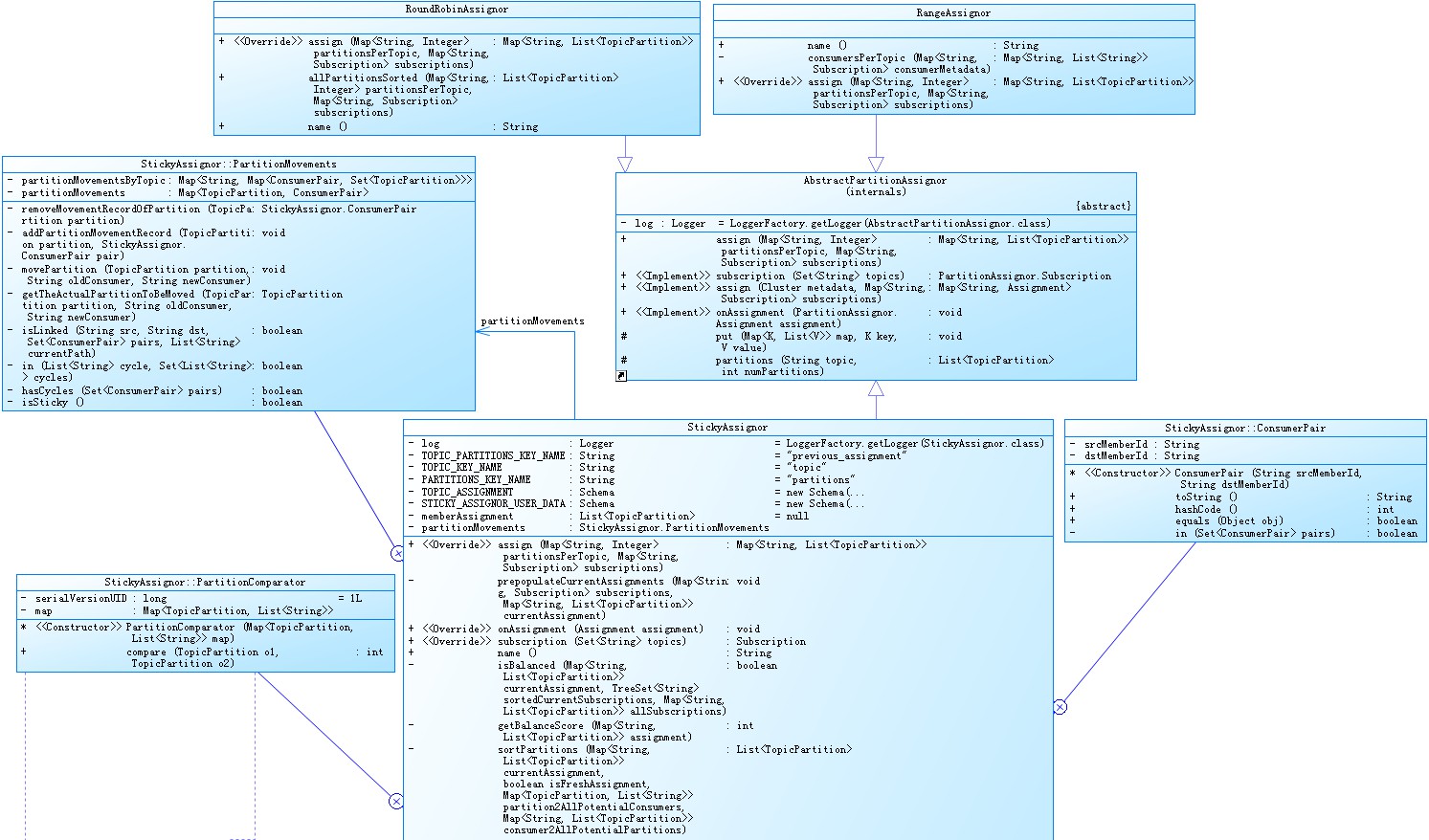
1 RangeAssignor 策略
RangeAssignor 以主题为单位,以数据顺序排列可用分区,以字典顺序排列消费者,将topic分区数除以消费者总数,以确定分配给每个消费者的分区数;如果没有平均分配,那么前几个消费者将拥有一个额外的分区。实现代码;
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
String topic = topicEntry.getKey();
List<String> consumersForTopic = topicEntry.getValue();
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
Collections.sort(consumersForTopic);
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size(); //topic分区数除以消费者总数
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size(); //计算额外分区
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
比如有两个topic(topic1 ,topic2) ,每个topic都有三个分区;
- topic1 ,分区:topic1p0,topic1p1,topic1p2
- topic2 ,分区:topic2p0,topic2p1,topic2p2
和一个消费组(consumer_group1),有(consumer1,consumer2)两个消费者,使用RangeAssignor策略可能会得到如下的分配:
- consumer1: [topic1p0,topic1p1,topic2p0,topic2p1]
- consumer2: [topic1p2,topic2p2]
如果此时消费组(consumer_group1)有新的消费者consumer3加入,使用RangeAssignor策略可能会得到如下的分配:
- consumer1: [topic1p0,topic2p0]
- consumer2: [topic1p2,topic2p2]
- consumer3: [topic1p1,topic2p1]
2 RoundRobinAssignor 策略
RoundRobinAssignor 是kafka默认策略,对所有分区和所有消费者循环分配,分区更均衡;实现代码;
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
CircularIterator<String> assigner = new CircularIterator<>(Utils.sorted(subscriptions.keySet()));
for (TopicPartition partition : allPartitionsSorted(partitionsPerTopic, subscriptions)) {
final String topic = partition.topic();
while (!subscriptions.get(assigner.peek()).topics().contains(topic))
assigner.next();
assignment.get(assigner.next()).add(partition);
}
继续以上例topic和消费组为例,RoundRobinAssignor 策略可能会得到如下的分配;
- consumer1: [topic1p0,topic1p1,topic2p2,]
- consumer2: [topic2p0,topic2p1,topic1p2]
3 StickyAssignor 策略
StickyAssignor 策略是最复杂且是0.11.x 版本出现的新策略,该策略主要作用:
- 使topic分区分配尽可能均匀的分配给消费者
- 当某个消费者终止触发重新分配时,尽可能保留现有分配,将已经终止的消费者所分配的分区移动到另一个消费者,避免全部分区重新平衡,节省开销。
这个策略自0.11.x 版本出现后,一直到新版本有不同bug被发现,低版本慎用。
4 java多线程消费实例
public class KafkaTopicConsumer {
private KafkaConsumer<String, String> consumer;
private int consumerId=0; //消费实例id
private final long timeOut=10000;
public KafkaTopicConsumer(int consumerId){
this.consumerId=consumerId;
Properties props = new Properties();
props.put("client.id", "client-" + consumerId);
props.put("bootstrap.servers","192.168.1.10:9092,192.168.1.11:9092");
props.put("group.id", "test-group03");
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("enable.auto.commit", "false");
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//设置分区策略
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.RangeAssignor");
consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList("topic1","topic2"));
}
public void consume() {
while (true){
ConsumerRecords<String, String> records=consumer.poll(timeOut);
System.out.println("records count:"+records.count());
for (ConsumerRecord<String, String> record : records) {
System.out.println(String.format("client-id = %d , topic = %s, partition = %d , offset = %d, key = %s, value = %s", this.consumerId,record.topic(), record.partition(), record.offset(), record.key(), record.value()));
}
consumer.commitSync();
}
}
public static void main(String[] args) {
int threadSize=Integer.parseInt(args[0]);
for (int i = 0; i < threadSize; i++) {
int id = i;
new Thread() {
@Override
public void run() {
new KafkaTopicConsumer(id).consume();
}
}.start();
}
}//
}
启动三个多线程实例消费,分区分配到每个消费者的情况;
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
test-group03 topic2 0 0 3333 3333 client-0_/192.168.1.13
test-group03 topic1 0 500 3333 2833 client-0_/192.168.1.13
test-group03 topic2 2 0 3333 3333 client-2_/192.168.1.13
test-group03 topic1 2 500 3333 2833 client-2_/192.168.1.13
test-group03 topic2 1 500 3334 2834 client-1_/192.168.1.13
test-group03 topic1 1 0 3334 3334 client-1_/192.168.1.13
对于大的topic,将topic单独消费以避免数据积压和topic各自影响数据处理速度,比如文章开始时提到的10分区的topic(topic01),根据硬件资源和分区策略设置合理的消费者,数据量大时最优的消费者数量为分区总数。
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG OWNER
test-group02 topic01 6 373460 1026328 652868 client-6_/192.168.1.13
test-group02 topic01 2 375660 1048756 673096 client-2_/192.168.1.13
test-group02 topic01 5 374625 1013157 638532 client-5_/192.168.1.13
test-group02 topic01 3 347001 1066967 719966 client-3_/192.168.1.13
test-group02 topic01 0 375570 1013261 637691 client-0_/192.168.1.13
test-group02 topic01 9 376545 1094088 717543 client-9_/192.168.1.13
test-group02 topic01 8 347082 1066948 719866 client-8_/192.168.1.13
test-group02 topic01 7 375100 1048827 673727 client-7_/192.168.1.13
test-group02 topic01 1 372447 1026467 654020 client-1_/192.168.1.13
test-group02 topic01 4 377052 1093926 716874 client-4_/192.168.1.13
5 总结
Kafka提供三种分配策略(RangeAssignor、RoundRobinAssignor、StickyAssignor),其中StickyAssignor策略是0.11.x 版本新增的,每种策略不尽相同,RangeAssignor策略以主题为单位,以数据顺序排列可用分区,以字典顺序排列消费者计算分配;RoundRobinAssignor 对所有分区和所有消费者循环均匀分配;但这两种分配策略当有消费者终止或加入时均会触发消费组平衡;StickyAssignor 策略当某个消费者终止时,尽可能保留现有分配,将已经终止的消费者所分配的分区移动到另一个消费者,避免全部分区重新平衡,节省开销;对于topic分区数较多、数量较大使用StickyAssignor策略有较大优势。
参考文献
- https://kafka.apache.org/0100/javadoc - kafka 0.10.0.1 API
- https://kafka.apache.org/0100/documentation.html - kafka DOCUMENTATION
加载全部内容