Raft算法系列教程4:日志不一致的解决
楚楚99 人气:0网络不可能一直处于正常情况,因为Leader或者某个Follower有可能会崩溃,从而导致日志不能一直保持一致。因此存在以下三种情况:
(1)Follower缺失当前Leader上存在的日志条目。
(2)Follower存在当前Leader不存在的日志条目。(比如旧的Leader仅仅将AppendEntries RPC消息发送到一部分Follower就崩溃掉,然后新当选Leader的服务器恰好是没有收到该AppendEntries RPC消息的服务器)
(3)Follower即缺失当前Leader上存在的日志条目,也存在当前Leader不存在的日志条目
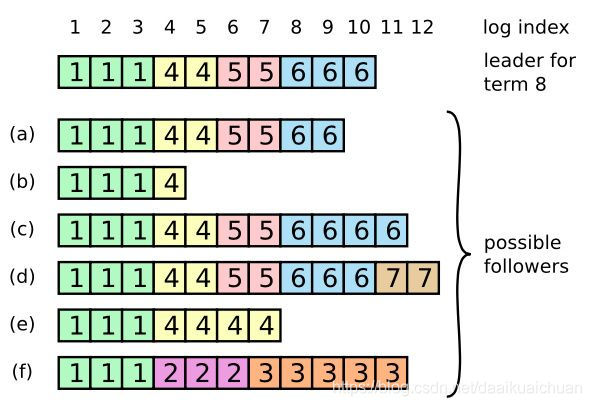
图中最上方是日志的索引号(1-12),每个方块代表一条日志信息,方块内数字代表该日志所处的任期号。
图中当前Leader(图中最上方一行日志代表当前Leader日志)处于任期号为8的时刻。以此图说明以上三种情况存在的原因:
Follower a、b(Follower崩溃没有接收到Leader发送的AppendEntries RPC消息)满足以上说明的第一种情况。
Follower c在任期为6的时刻,Followerd在任期为7的时刻为Leader,但没有完全完成日志的发送便崩溃了,满足以上说明的第三种情况。
Follower e在任期为4的时刻,Followerf在任期为2、3的时刻为Leader,但没有完全完成日志的发送便崩溃了,同时在其他服务器当选Leader时刻也没有接收到新的Leader发送的AppendEntries RPC消息,满足第三种情况。
日志不一致的解决方案
Leader通过强迫Follower的日志重复自己的日志来处理不一致之处。这意味着Follower日志中的冲突日志将被Leader日志中的条目覆盖。因此Leader必须找到与Follower最开始日志发生冲突的位置,然后删除掉Follower上所有与Leader发生冲突的日志,最后将自己的日志发送给Follower以解决冲突。
Leader不会删除或覆盖自己本地的日志条目
这些步骤从之前说到的日志的一致性检查开始。
当发生日志冲突时,Follower将会拒绝由Leader发送的AppendEntries RPC消息,并返回一个响应消息告知Leader日志发生了冲突。
Leader为每一个Follower维护一个nextIndex值。该值用于确定需要发送给该Follower的下一条日志的位置索引。(该值在当前服务器成功当选Leader后会重置为本地日志的最后一条索引号+1)
当Leader了解到日志发生冲突之后,便递减nextIndex值。并重新发送AppendEntries RPC到该Follower。并不断重复这个过程,一直到Follower接受该消息。
一旦Follower接受了AppendEntries RPC消息,Leader则根据nextIndex值可以确定发生冲突的位置,从而强迫Follower的日志重复自己的日志以解决冲突问题。
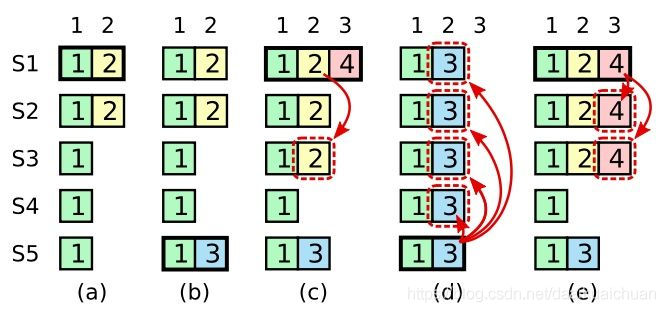
情况a:如上图,服务器S1在任期为2的时刻仅将日志<index:2,term:2>发送到了服务器S2便崩溃掉。
情况b:服务器S5在任期为3的时刻当选Leader(S5的计时器率先超时,递增任期号为3,高于服务器S3和S4,因此可以当选Leader),但没来得及发送日志便崩溃掉。
情况c:服务器S1在任期为4的时刻再次当选Leader(S1重启时,任期仍然为2,收到新的LeaderS5发送的心跳信息后更新任期为3,而在LeaderS5崩溃后,服务器S1为第一个计时器超时的,因此发起投票,任期更新为4,大于网络中其他服务器任期,成功当选Leader),同时将日志<index:2,term:2>发送到了服务器S2和S3,但还没有通知服务器对日志进行提交便崩溃掉。
情况d:情况(a->d)如果在任期为2时服务器S1作为Leader崩溃掉,S5在任期为3的时刻当选Leader,由于日志<index:2,term:2>还没有被复制到大部分服务器上,并没有被提交,所以S5可以通过自己的日志<index:2,term:3>覆盖掉日志<index:2,term:2>。
情况e:情况(a->e)如果在任期为2时服务器S1作为Leader,并将<index:2,term:2>发送到S2和S3,成功复制到大多数成员服务器上。并且成功提交了该日志,那么即便S1崩溃掉,S5也无法成功当选Leader,因为S5不具备网络中最新的已被提交的日志条目。
加载全部内容