Redis 对过期数据的处理方法
程序员养成日记 人气:0在 redis 中,对于已经过期的数据,Redis 采用两种策略来处理这些数据,分别是惰性删除和定期删除
惰性删除
惰性删除不会去主动删除数据,而是在访问数据的时候,再检查当前键值是否过期,如果过期则执行删除并返回 null 给客户端,如果没有过期则返回正常信息给客户端。
它的优点是简单,不需要对过期的数据做额外的处理,只有在每次访问的时候才会检查键值是否过期,缺点是删除过期键不及时,造成了一定的空间浪费。
源码
robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) {
robj *val;
if (expireIfNeeded(db,key) == 1) {
/* Key expired. If we are in the context of a master, expireIfNeeded()
* returns 0 only when the key does not exist at all, so it's safe
* to return NULL ASAP. */
if (server.masterhost == NULL) {
server.stat_keyspace_misses++;
notifyKeyspaceEvent(NOTIFY_KEY_MISS, "keymiss", key, db->id);
return NULL;
}
/* However if we are in the context of a slave, expireIfNeeded() will
* not really try to expire the key, it only returns information
* about the "logical" status of the key: key expiring is up to the
* master in order to have a consistent view of master's data set.
*
* However, if the command caller is not the master, and as additional
* safety measure, the command invoked is a read-only command, we can
* safely return NULL here, and provide a more consistent behavior
* to clients accessign expired values in a read-only fashion, that
* will say the key as non existing.
*
* Notably this covers GETs when slaves are used to scale reads. */
if (server.current_client &&
server.current_client != server.master &&
server.current_client->cmd &&
server.current_client->cmd->flags & CMD_READONLY)
{
server.stat_keyspace_misses++;
notifyKeyspaceEvent(NOTIFY_KEY_MISS, "keymiss", key, db->id);
return NULL;
}
}
val = lookupKey(db,key,flags);
if (val == NULL) {
server.stat_keyspace_misses++;
notifyKeyspaceEvent(NOTIFY_KEY_MISS, "keymiss", key, db->id);
}
else
server.stat_keyspace_hits++;
return val;
}
定期删除
定期删除:Redis会周期性的随机测试一批设置了过期时间的key并进行处理。测试到的已过期的key将被删除。
具体的算法如下:
- Redis配置项hz定义了serverCron任务的执行周期,默认为10,代表了每秒执行10次;
- 每次过期key清理的时间不超过CPU时间的25%,比如hz默认为10,则一次清理时间最大为25ms;
- 清理时依次遍历所有的db;
- 从db中随机取20个key,判断是否过期,若过期,则逐出;
- 若有5个以上key过期,则重复步骤4,否则遍历下一个db;
- 在清理过程中,若达到了25%CPU时间,退出清理过程;
虽然redis的确是不断的删除一些过期数据,但是很多没有设置过期时间的数据也会越来越多,那么redis内存不够用的时候是怎么处理的呢?这里我们就会谈到淘汰策略
Redis内存淘汰策略
当redis的内存超过最大允许的内存之后,Redis会触发内存淘汰策略,删除一些不常用的数据,以保证redis服务器的正常运行
在redis 4.0以前,redis的内存淘汰策略有以下6种
- noeviction:当内存使用超过配置的时候会返回错误,不会驱逐任何键
- allkeys-lru:加入键的时候,如果过限,首先通过LRU算法驱逐最久没有使用的键
- volatile-lru:加入键的时候如果过限,首先从设置了过期时间的键集合中驱逐最久没有使用的键
- allkeys-random:加入键的时候如果过限,从所有key随机删除
- volatile-random:加入键的时候如果过限,从过期键的集合中随机驱逐
- volatile-ttl:从配置了过期时间的键中驱逐马上就要过期的键
- 在redis 4.0以后,又增加了以下两种
- volatile-lfu:从所有配置了过期时间的键中驱逐使用频率最少的键
- allkeys-lfu:从所有键中驱逐使用频率最少的键
内存淘汰策略可以通过配置文件来修改,redis.conf对应的配置项是maxmemory-policy 修改对应的值就行,默认是noeviction
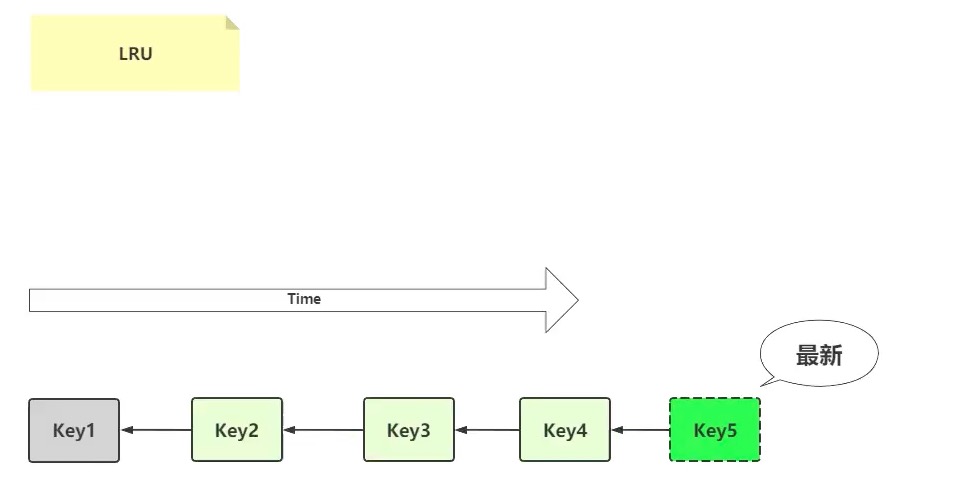
LRU(the least recently used 最近最少使用)算法
如果一个数据在最近没有被访问到,那么在未来被访问的可能性也很小,因此当空间满的时候,最久没有被访问的数据最先被置换(淘汰)
LRU算法通常通过双向链表来实现,添加元素的时候,直接插入表头,访问元素的时候,先判断元素是否在链表中存在,如果存在就把该元素移动至表头,所以链表的元素排列顺序就是元素最近被访问的顺序,当内存达到设置阈值时,LRU队尾的元素由于被访问的时间线较远,会优先踢出
但是在redis中,并没有严格实行LRU算法,之所以这样是因为LRU需要消耗大量的额外内存,需要对现有的数据结构进行较大的改造,近似LRU算法采用在现有数据结构的基础上使用随机采样法来淘汰元素,能达到和LRU算法非常近似的效果。Redis的 LRU算法给每个key增加了一个额外的长度为24bit的小字段,记录最后一次被访问的时间戳。
redis通过maxmemory-samples 5配置,对key进行采样淘汰。同时在Redis3.0以后添加了淘汰池进一步提升了淘汰准确度。
但是LRU算法是存在一定的问题
例如,这表示随着时间的推移,四个不同的键访问。每个“〜”字符为一秒钟,而“ |” 最后一行是当前时刻。
~~ B ~~ B ~~ B ~~ B ~~ B ~~ B ~~ B ~~ B ~~ B ~~ B ~~ B ~~ B〜|
~~~~~~~~~~ C ~~~~~~~~ C ~~~~~~~~~ C ~~~~~~ |
~~~~~ D ~~~~~~~~~ D ~~~~~~~ D ~~~~~~~~ D |
在上图中,按照LRU机制删除的话删除的顺序应该是C->A->B->D 其实这并不是我们想要的,因为B被访问的频率是最高的,而D被访问的频率比较低,所以我们更想让B保留,把D删除,所以我们接下来看另一种策略 LFU
**LFU(leastFrequently used 最不经常使用)**
如果一个数据在最近一段时间内很少被访问到,那么可以认为在将来他被访问到的概率也很小。所以,当空间满时,最小频率访问的数据最先被淘汰
Redis使用redisObject中的24bit lru字段来存储lfu字段, 这24bit被分为两部分:
1:高16位用来记录访问时间(单位为分钟)
2:低8位用来记录访问频率,简称counter
16 bits 8 bits
+----------------+--------+
Last decr time | LOG_C |
但是counter 8bit很容易就溢出了,技巧是用一个逻辑计数器,给予概率的对数计数器,而不是一个普通的递增计数器
```
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
```
对应的概率分布计算公式为
```
1.0/((counter - LFU_INIT_VAL)*server.lfu_log_factor+1);
```
其中LFU_INIT_VAL为5,其实简单说就是,越大的数,递增的概率越低
严格按照LFU算法,时间越久的key,counter越有可能越大,被剔除的可能性就越小。counter只增长不衰减就无法区分热点key。为了解决这个问题,redis提供了衰减因子server.lfu_decay_time,其单位为分钟,计算方法也很简单,如果一个key长时间没有访问那么他的计数器counter就要减少,减少的值由衰减因子来控制
加载全部内容