Redis 中的布隆过滤器的实现
JayChen 人气:0什么是『布隆过滤器』
布隆过滤器是一个神奇的数据结构,可以用来判断一个元素是否在一个集合中。很常用的一个功能是用来去重。在爬虫中常见的一个需求:目标网站 URL 千千万,怎么判断某个 URL 爬虫是否宠幸过?简单点可以爬虫每采集过一个 URL,就把这个 URL 存入数据库中,每次一个新的 URL 过来就到数据库查询下是否访问过。
select id from table where url = 'https://jaychen.cc'
但是随着爬虫爬过的 URL 越来越多,每次请求前都要访问数据库一次,并且对于这种字符串的 SQL 查询效率并不高。除了数据库之外,使用 Redis 的 set 结构也可以满足这个需求,并且性能优于数据库。但是 Redis 也存在一个问题:耗费过多的内存。这个时候布隆过滤器就很横的出场了:这个问题让我来。
相比于数据库和 Redis,使用布隆过滤器可以很好的避免性能和内存占用的问题。
布隆过滤器本质是一个位数组,位数组就是数组的每个元素都只占用 1 bit 。每个元素只能是 0 或者 1。这样申请一个 10000 个元素的位数组只占用 10000 / 8 = 1250 B 的空间。布隆过滤器除了一个位数组,还有 K 个哈希函数。当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
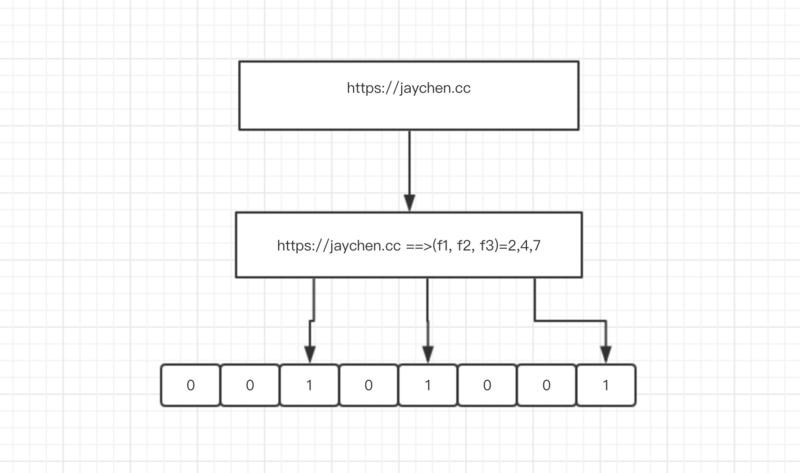
举个🌰,假设布隆过滤器有 3 个哈希函数:f1, f2, f3 和一个位数组 arr。现在要把 https://jaychen.cc 插入布隆过滤器中:
- 对值进行三次哈希计算,得到三个值 n1, n2, n3。
- 把位数组中三个元素 arr[n1], arr[n2], arr[3] 置为 1。
当要判断一个值是否在布隆过滤器中,对元素再次进行哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
看不懂文字看下面的灵魂画手的图解释👇👇👇
看了上面的说明,必然会提出一个问题:当插入的元素原来越多,位数组中被置为 1 的位置就越多,当一个不在布隆过滤器中的元素,经过哈希计算之后,得到的值在位数组中查询,有可能这些位置也都被置为 1。这样一个不存在布隆过滤器中的也有可能被误判成在布隆过滤器中。但是如果布隆过滤器判断说一个元素不在布隆过滤器中,那么这个值就一定不在布隆过滤器中。简单来说:
- 布隆过滤器说某个元素在,可能会被误判。
- 布隆过滤器说某个元素不在,那么一定不在。
这个布隆过滤器的缺陷放到上面爬虫的需求中,可能存在某些没有访问过的 URL 可能会被误判为访问过,但是如果是访问过的 URL 一定不会被误判为没访问过。
Redis 中的布隆过滤器
redis 在 4.0 的版本中加入了 module 功能,布隆过滤器可以通过 module 的形式添加到 redis 中,所以使用 redis 4.0 以上的版本可以通过加载 module 来使用 redis 中的布隆过滤器。但是这不是最简单的方式,使用 docker 可以直接在 redis 中体验布隆过滤器。
> docker run -d -p 6379:6379 --name bloomfilter redislabs/rebloom > docker exec -it bloomfilter redis-cli
redis 布隆过滤器主要就两个命令:
bf.add添加元素到布隆过滤器中:bf.add urls https://jaychen.cc。bf.exists判断某个元素是否在过滤器中:bf.exists urls https://jaychen.cc。
上面说过布隆过滤器存在误判的情况,在 redis 中有两个值决定布隆过滤器的准确率:
error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
redis 中有一个命令可以来设置这两个值:
bf.reserve urls 0.01 100
三个参数的含义:
- 第一个值是过滤器的名字。
- 第二个值为
error_rate的值。 - 第三个值为
initial_size的值。
使用这个命令要注意一点:执行这个命令之前过滤器的名字应该不存在,如果执行之前就存在会报错:(error) ERR item exists
加载全部内容