Redis性能大幅提升之Batch批量读写详解
649727360 人气:0这篇文章主要给大家介绍了关于Redis性能大幅提升之Batch批量读写的相关资料,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来跟着小编一起来学习学习吧。
前言
本文主要介绍的是关于Redis性能提升之Batch批量读写的相关内容,分享出来供大家参考学习,下面来看看详细的介绍:
提示:本文针对的是StackExchange.Redis
一、问题呈现
前段时间在开发的时候,遇到了redis批量读的问题,由于在StackExchange.Redis里面我确实没有找到PipeLine命令,找到的是Batch命令,因此对其用法进行了探究一下。
下面的代码是我之前写的:
public List<StudentEntity> Get(List<int> ids)
{
List<StudentEntity> result = new List<StudentEntity>();
try
{
var db = RedisCluster.conn.GetDatabase();
foreach (int id in ids.Keys)
{
string key = KeyManager.GetKey(id);
var dic = db.HashGetAll(key).ToDictionary(k => k.Name, v => v.Value);
StudentEntity se = new StudentEntity();
if (dic.Keys.Contains(StudentEntityRedisHashKey.id.ToString()))
{
pe.id = FormatUtils.ConvertToInt32(dic[StudentEntityRedisHashKey.id.ToString()], -1);
}
if (dic.Keys.Contains(StudentEntityRedisHashKey.name.ToString()))
{
pe.name= dic[StudentEntityRedisHashKey.name.ToString()];
}
result.Add(se);
}
catch (Exception ex)
{
}
return result;
}
从上面的代码中可以看出,并不是批量读,经过性能测试,性能确实是要远远低于用Batch操作,因为HashGetAll方法被执行了多次。
下面给出批量方法:
二、解决问题方法
具体的用法是:
var batch = db.CreateBatch(); ...//这里写具体批量操作的方法 batch.Execute();
2.1批量写:
具体代码:
public bool InsertBatch(List<StudentEntity> seList)
{
bool result = false;
try
{
var db = RedisCluster.conn.GetDatabase();
var batch = db.CreateBatch();
foreach (var se in seList)
{
string key = KeyManager.GetKey(se.id);
batch.HashSetAsync(key, StudentEntityRedisHashKey.id.ToString(), te.id);
batch.HashSetAsync(key, StudentEntityRedisHashKey.name.ToString(), te.name);
}
batch.Execute();
result = true;
}
catch (Exception ex)
{
}
return result;
}
这个方法里执行的是批量插入学生实体数据,这里只是针对Hash,其它的也一样操作。
2.2批量读:
具体代码:
public List<StudentEntity> GetBatch(List<int> ids)
{
List<StudentEntity> result = new List<StudentEntity>();
List<Task<StackExchange.Redis.HashEntry[]>> valueList = new List<Task<StackExchange.Redis.HashEntry[]>>();
try
{
var db = RedisCluster.conn.GetDatabase();
var batch = db.CreateBatch();
foreach(int id in ids)
{
string key = KeyManager.GetKey(id);
Task<StackExchange.Redis.HashEntry[]> tres = batch.HashGetAllAsync(key);
valueList.Add(tres);
}
batch.Execute();
foreach(var hashEntry in valueList)
{
var dic = hashEntry.Result.ToDictionary(k => k.Name, v => v.Value);
StudentEntity se= new StudentEntity();
if (dic.Keys.Contains(StudentEntityRedisHashKey.id.ToString()))
{
se.id= FormatUtils.ConvertToInt32(dic[StudentEntityRedisHashKey.id.ToString()], -1);
}
if (dic.Keys.Contains(StudentEntityRedisHashKey.name.ToString()))
{
se.name= dic[StudentEntityRedisHashKey.name.ToString()];
}
result.Add(se);
}
}
catch (Exception ex)
{
}
return result;
}
这个方法是批量读取学生实体数据,批量拿到实体数据后,将其转化成我们需要的数据。下面给出性能对比。
2.3性能对比:
10条数据,约4-5倍差距:
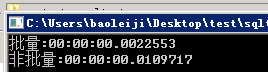
1000条数据,约28倍的差距:
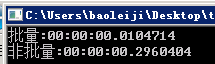
随着数据了增多,差距将越来越大。
三、源码测试案例
上面是批量读写实体数据,下面给出StackExchange.Redis源码测试案例里的批量读写写法:
public void TestBatchSent()
{
using (var muxer = Config.GetUnsecuredConnection())
{
var conn = muxer.GetDatabase(0);
conn.KeyDeleteAsync("batch");
conn.StringSetAsync("batch", "batch-sent");
var tasks = new List<Task>();
var batch = conn.CreateBatch();
tasks.Add(batch.KeyDeleteAsync("batch"));
tasks.Add(batch.SetAddAsync("batch", "a"));
tasks.Add(batch.SetAddAsync("batch", "b"));
tasks.Add(batch.SetAddAsync("batch", "c"));
batch.Execute();
var result = conn.SetMembersAsync("batch");
tasks.Add(result);
Task.WhenAll(tasks.ToArray());
var arr = result.Result;
Array.Sort(arr, (x, y) => string.Compare(x, y));
...
}
}
这个方法里也给出了批量写和读的操作。
总结
好了,先说到这里了。以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流,谢谢大家对的支持。
加载全部内容