深入了解MongoDB 分布式集群
木石头 人气:0在分布式应用系统中,mongodb 已经成为 NoSQL 经典数据库。要想很好的使用 mongodb,仅仅知道如何使用它是不够的。只有对其架构原理等有了充分认识,才能在实际运用中使其更好地服务于应用,遇到问题知道怎么处理,而不是抓瞎抹黑。这篇文章就带你进入 mongodb 集群的大门。
集群概览
mongodb 相关的进程分为三类:
- mongo 进程 – 该进程是 mongodb 提供的 shell 客户端进程,通过该客户端可以发送命令并操作集群;
- mongos 进程 – mongodb 的路由进程,负责与客户端连接,转发客户端请求到后端集群,对客户端屏蔽集群内部结构;
- mongod 进程 – 提供数据读写的 mongodb 实例进程。
类比银行服务,mongo 进程相当于客户,mongos 进程是柜台服务员,mongod 进程是银行后台实际处理业务的人员或者流程。客户只需要和柜台服务员沟通,告知办什么业务,柜台服务员将业务转往后台,后台实际处理。
下图是 mongodb 集群的一般拓扑结构。
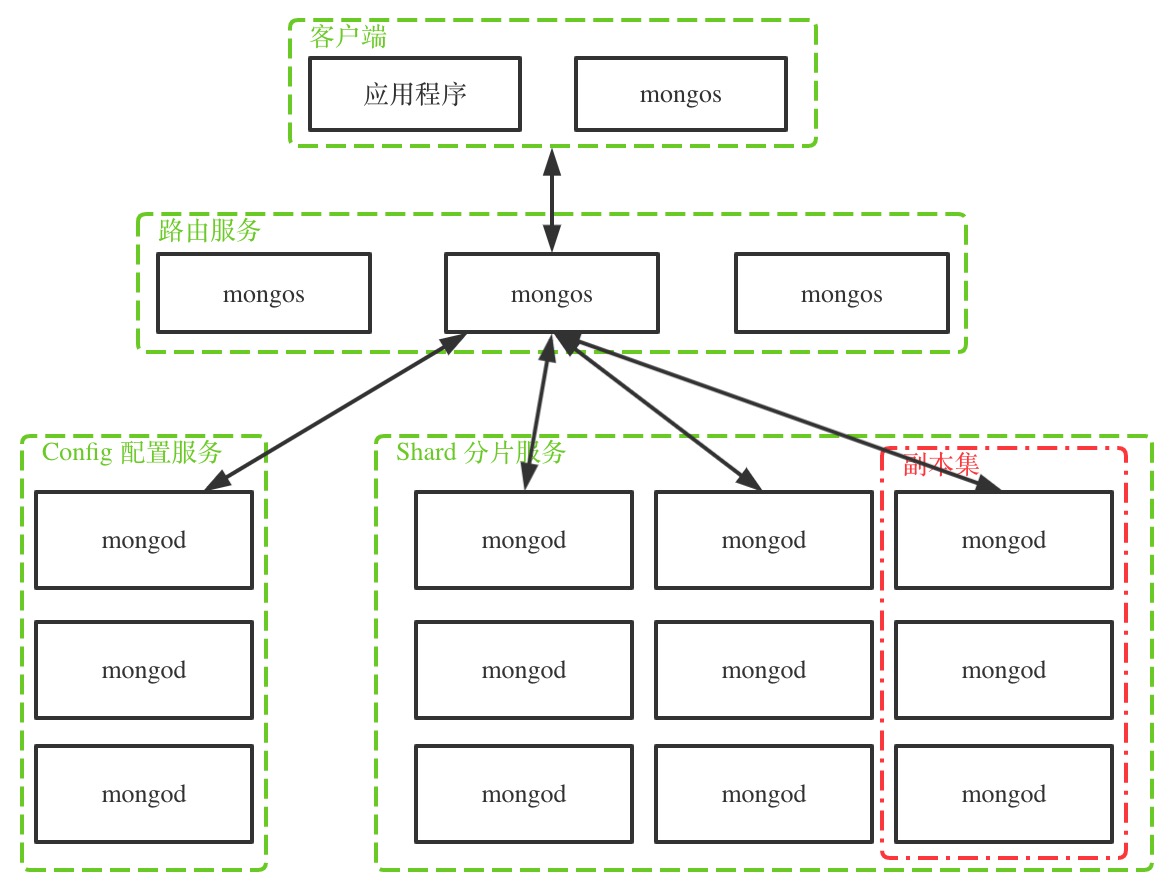
如图,mongodb 集群的节点分为三类:
- mongos 路由节点:处理客户端的连接,扮演存取路由器的角色,将请求分发到正确的数据节点上,对客户端屏蔽分布式的概念;
- config 配置节点:配置服务,保存数据结构的元数据,比如每个分片上的数据范围,数据块列表等。配置节点也是 mongod 进程,只是它存储的数据是集群相关的元数据;
- shard 分片节点:数据存储节点,分片节点由若干个副本集组成,每个副本集存储部分全体数据,所有副本集的数据组成全体数据,而副本集内部节点存放相同的数据,做数据备份与高可用。
还是拿银行业务类比,当客户办理保单保存业务时,
- 柜台服务员接受客户的保单业务请求(mongos 路由节点接收客户端的操作请求);
- 柜台服务员查询文件目录系统查看该保单应该保存到哪个仓库(mongos 节点与 config 配置节点通信,查询相关操作数据在哪个分片节点);
- 知道哪个仓库后,柜台服务员将保单给仓库管理员,仓库管理员将保单放到指定仓库中(mongos 节点将请求发送给数据所在分片节点,分片节点进行读写处理)。
mongos 路由服务
mongos 服务类似网关,连接 mongodb 集群与应用程序,对外屏蔽 mongodb 内部结构,应用程序只需要将请求发送给 mongos,而无需关心集群内部副本分片等信息。
mongos 本身不保存数据与索引信息,它通过查询 config 配置服务来获取,所以可以考虑将 mongos 与应用程序部署在同一台服务器上,当服务器宕机时 mongos 也一起失效,防止出现 mongos 闲置。
mongos 节点也可以是单个节点,但为了高可用,一般部署多个节点。就像柜台服务员一样,可以有多个,相互之间没有主备关系,都可以独立处理业务。
需要注意的是,在开启分片的情况下,应用程序应该避免直接连接分片节点进行数据修改,因为这种情况下很可能造成数据不一致等严重后果,而是通过 mongos 节点来操作。
config 配置服务
config 配置节点本质也是一个副本集,副本集中存放集群的元数据,如各个分片上的数据块列表,数据范围,身份验证等信息。如下,可以看到数据库 config,数据库中集合保存了集群的重要元数据。
mongos> use config; switched to db config mongos> show collections; changelog chunks collections databases lockpings locks migrations mongos shards tags transactions version
一般情况下,用户不应该直接变更 config 的数据,否则很可能造成严重后果。
shard 分片服务
分布式存储要解决的是两个问题:
随着业务不断发展,数据量越来越大,单机存储受限于物理条件,必然要通过增加服务器来支持不断增大的数据。所以分布式下,不可能全部数据存储在一个节点上,必然是将数据划分,部分数据放到这个节点,另外部分数据放到另外的节点上。也就是数据的伸缩性。
考虑高可用。如果同一份数据只存在一个节点上,当这个节点发生异常时,数据不可用。这就要求分布式下同一份数据需要存储在多个节点上,以达高可用效果。
在 mongodb 集群中,数据的伸缩性通过分片集来实现,高可用通过副本集来实现。
如图,全部数据为1-6,将其划分为3部分,1-2为一个分片,3-4为一个分片,5-6为一个分片。每个分片存储在不同的节点上。而每个分片有3个副本,组成副本集,每个副本都是独立的 mongod 实例。
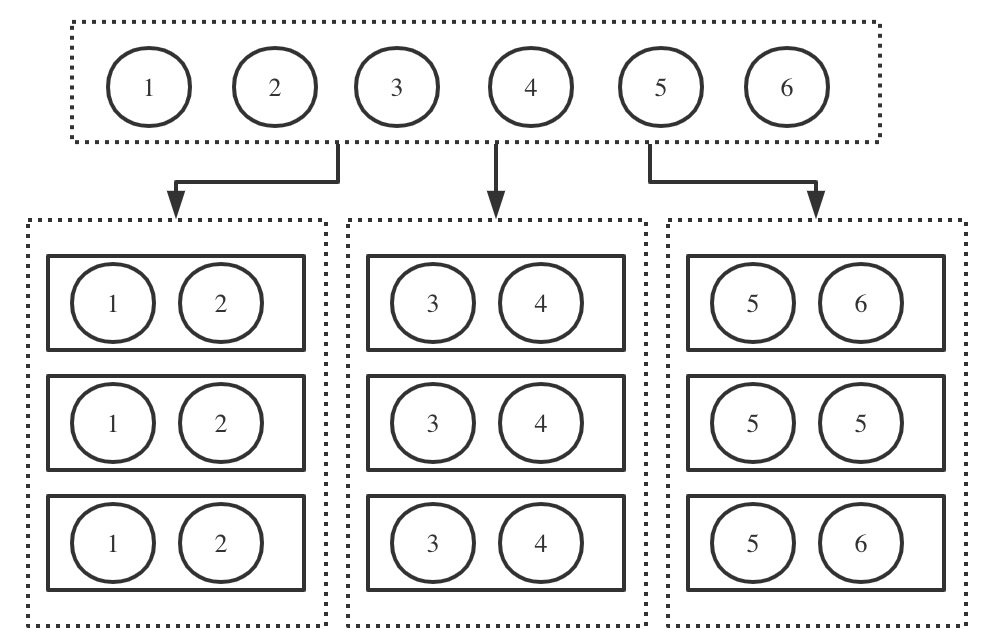
所以副本集是一个纵向概念,描述的是相同的数据存储在多个节点上;而分片是一个横向概念,描述的是全量数据被切成不同的片段,每个片段独立存储。这个片段就是分片,而分片通过副本集进行存储。
副本集
副本集包含三种角色:
- 主节点(Primary)
- 副节点(Secondary)
- 仲裁节点(Arbiter)
一个副本集由一个主节点,多个副节点,0或多个仲裁节点组成。
主节点与副节点是数据节点。主节点提供数据的写操作,数据写到主节点后,会通过同步机制同步到副节点上。默认读操作也由主节点提供,但是可以手动设置 read preference,优先从副节点读取。
仲裁节点不是数据节点,不存储数据,也不提供读写操作。仲裁节点是作为投票者存在,当主节点异常需要进行切换时,仲裁节点有投票权,但没有被投票权。仲裁节点可以在资源有限的情况下,依然支持故障恢复。比如只有2个节点的硬盘资源,在这种情况下可以增加一个不占存储的仲裁节点,组成“一主一副一仲裁”的副本集架构,当主节点宕掉时,副节点能够自动切换。
节点间通过“心跳”进行沟通,以此知道彼此的状态。当主节点异常不可用时,从其他有被投票权的节点中投票选出一个升级为主节点,继续保持服务高可用。这里投票采取“大多数”原则,即需要多于总节点数一半的节点同意,才能被选举成主节点。也因此不建议采用偶数个节点组成副本集,因为偶数情况下,如果发生半数节点网络隔离,隔离的半数节点达不到“大多数”的要求,无法选举产生新的主节点。
通过 rs.status() 可以查看副本集,参考《教你快速搭建 mongodb 集群》
分片集
分片就是将全部数据根据一定规则划分成没有交集的数据子集,每个子集就是一个分片,不同分片存放在不同节点上。这里有几个问题:
- 划分规则也就是分片策略是什么?
- 分片数据是如何存放的?
- 数据量越来越大,分片如何动态调整?
数据块 Chunk
chunk 由多个文档组成,一个分片中包含多个 chunk。chunk 是分片间数据迁移的最小单位。实际上,文档是通过分片策略计算出应该存储在哪个 chunk,而 chunk 存放在分片上。
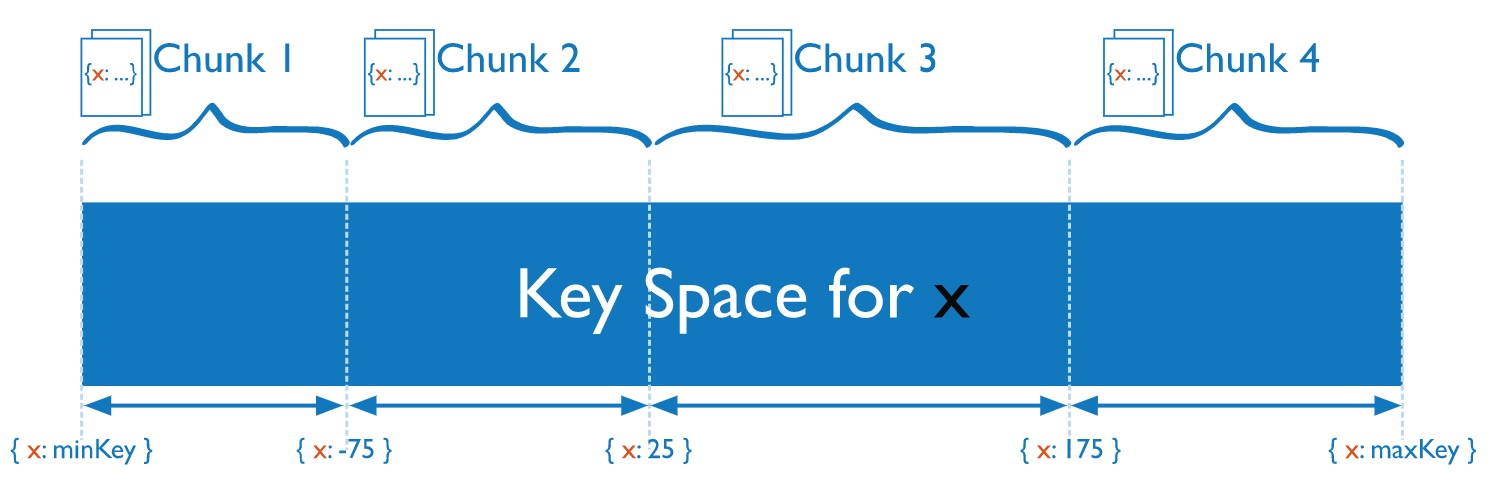
如图,假设按照文档的 x 字段值来进行分片,根据不同取值范围存放在不同的数据块,如25-175在 chunk 3上。
把书比作 mongodb 中的文档,书柜比作数据块,房间比作分片。每本书根据一定规则放到某书柜上,房间中有很多书柜。当某个房间的书柜太多,就需要以书柜为单位,迁移到相对比较宽松的房间。
chunk 的大小默认为 64MB,也可以自定义。chunk 的存在有两个意义:
- 当某个 chunk 超过大小时,会触发 chunk 分裂。
- 当分片间的 chunk 数不均衡时,会触发 chunk 迁移。
chunk 迁移由 mongodb 的平衡器来操作,默认平衡器是开启的,是运行在后台的一个进程,也可以手动关闭。
可以通过下面命令来查看平衡器状态:
sh.getBalancerState()
chunk 的大小对集群的影响:
- 比较小时,chunk 数比较多,数据分布比较均匀,但会引起频繁的数据块分裂与迁移;
- 比较大时,chunk 数比较少,数据容易分散不均匀,迁移时网络传输量大。
所以要自定义数据块大小时,一定要考虑完备,否则将大大影响集群与应用程序的性能。
片键 Shard Key
mongodb 集群不会自动将数据进行分片,需要客户端告知 mongodb 哪些数据需要进行分片,分片的规则是什么。
某个数据库启用分片:
mongos> sh.enableSharding(<database>)
设置集合的分片规则:
mongos> sh.shardCollection(<database.collection>,<key>,<unique>,<options>) # unique 与 options 为可选参数
例如,将数据库 mustone 开启分片,并设置库中 myuser 集合的文档根据 _id 字段的散列值来进行划分分片。
sh.enableSharding("mustone")
sh.shardCollection("mustone.myuser",{_id: "hashed"})
这里划分规则体现在 上, 定义了分片策略,分片策略由片键 Shard Key 与分片算法组成。片键就是文档的某一个字段,也可以是复合字段。分片算法分为两种:
- 基于范围。如 设置为 id:1 表示基于字段 id 的升序进行分片,id:-1 表示基于字段 id 的倒序进行分片,字段 id 就是 shard key(片键)。当集合中文档为空时,设置分片后,会初始化单个 chunk,chunk 的范围为(-∞,+∞)。当不断往其中插入数据到达 chunk 大小上限后,会进行 chunk 分裂与必要迁移。
- 基于hash。如上面的栗子, 设置为 _id:”hashed”,表示根据字段 _id 的哈希来分片,此时片键为 _id。初始化时会根据分片节点数初始化若干个 chunk,如3个分片节点会初始化6个 chunk,每个 shard 2个 chunk。
每个数据库会分配一个 primary shard,初始化的 chunk 或者没有开启分片的集合都默认放在这个 primary shard 上。
分片策略的选择至关重要,等数据量大了再更改分片策略将会很麻烦。分片策略的原则:
- 均匀分布原则。分片的目标就是让数据在各个分片上均匀分布,数据的存取压力也分解到各个分片上。比如以自增长的 id 升序为片键,会导致新数据永远都写在最后的 chunk 上,且 chunk 分裂与迁移也会落在该 chunk 所在分片上,造成该分片压力过大。
- 大基数原则。集合的片键可能包含的不同值的个数,称为基数。基数越大,数据就能划分得更细。基数越小,chunk 的个数就有限。比如性别,只有男女,如果作为片键,最多两个 chunk,等数据越来越大后,便无法横向扩展。
- 就近原则。尽可能让一次查询的数据分布在同一个 chunk 上,这样提升磁盘读取性能。避免毫无意义的随机片键,虽然分布均匀了,但每次查询都要跨多个 chunk 才能完成,效率低下。
需要说明的是,mongodb 分片集群虽然比较完备,但是存在一些限制,如备份相对困难,分片集合无法做关联查询等。所以要根据实际业务来评估,如果副本集已经够用了,不一定要进行分片存取。
加载全部内容