MongoDB的创建、更新和删除
人气:0概要
下面开始学习MongoDB最重要也是最基础的部分:C(创建)R(查询)U(更新)D(删除);由于R(查询)操作相对来说内容比较多,也比较繁琐,
同时使用频率也比较高,所以下一篇会拿出来单独介绍。废话不多说,连上服务器,我们直接进入正题!
一、创建
按照我们关系型数据库的思想,一个服务器要想存放数据,首先要有数据库,表,字段,约束,当然了也少不了主键,外键,索引,关系等;
但是在MongoDB的世界里边,我们不用预先的去创建这些信息从而直接来使用各个属性。
1、数据库(database)
a)、创建
use mydb(创建并切换到名称为mydb的数据库实例下。注:如果你对其不进行任何操作,该数据库是没有任何实际意义的)
2、集合(collection)
a)、创建
我们直接指定,不做任何预处理,指定一个名称为users的数据集(相当于表),并向其中插入一条用户数据。
db.users.insert({ "name" : "wjg" , "age" : 24 })
返回结果如下,表示你已经成功插入了一条数据:
WriteResult({ "nInserted" : 1 })
b)、显式创建
仅创建一个名称为collectionName的,没有任何大小和数量限制的数据集
db.createCollection("collectionName")
如果该数据集有重名,会给出已经存在的提示:
{ "ok" : 0, "errmsg" : "collection already exists", "code" : 48 }
成功之后会给出ok的提示:
{ "ok" : 1 }
3、文档(document)
a)、单一插入
注:如果没有主键“_id”,插入文档的时候MongoDB会为我们自动保存一个进去。
这里我们指定一个“_id”,当然了,“_id”肯定是不能重复的,否则无法插入成功。
db.users.insert({"_id":0,"name":"jack","age":20})
成功插入数据之后:
WriteResult({ "nInserted" : 1 })
b)、批量插入
注:一次性插入多个文档会明显提高插入速度;
插入文档的大小限制为48MB;
如果其中有一个文档插入失败了,这个文档之前的都可以插入成功,但是在它之后都会失败;(不同的驱动可能会有不同的处理方式)
db.users.insert([{"_id":1,"name":"tom","age":21},{"_id":2,"name":"joe","age":22},{"_id":3,"name":"bob","age":22}])
批量插入成功之后会返回如下信息:
BulkWriteResult({
"writeErrors":[],
"writeConcernErrors":[],
"nInserted":3,
"nUpserted":0,
"nMatched":0,
"nModified":0,
"nRemoved":0,
"upserted":[]})
分别表示的大致意思为:
插入的错误信息,其他的插入错误信息,插入的文档数量,特殊更新的文档数量,匹配到的文档数量,
更新的文档数量,移出的文档数量和特殊文档更新信息
特殊的文档更新(upsert),其定义如下:
如果没有找到符合更新条件的文档,就会以这个条件和更新文档为基础创建一个新的文档;如果找到了匹配的文档,那么就正常更新
二、更新
想要更新文档,必须要有两个参数:
一个是查询条件,用于定位到需要更新的目标文档;另一个是修改器,用于说明要对找到的文档进行哪些修改
截至此刻为止,我们已经向mydb数据库中名称为users的数据集中添加了如下几个文档:

a)、单一更新
让我们来为名字为bob的年龄增加一岁,直接将年龄更新为23岁
db.users.update({"name":"bob"},{$set:{"age":23}}) //使用了$set修改器之后,只会更新age自段的值为23
或者
db.users.update({"name":"bob"},{"age":23}) //同样会将age自段的值更新为23,但是会移出除了“_id”和本身之外的所有字段值
具体详情如下图:
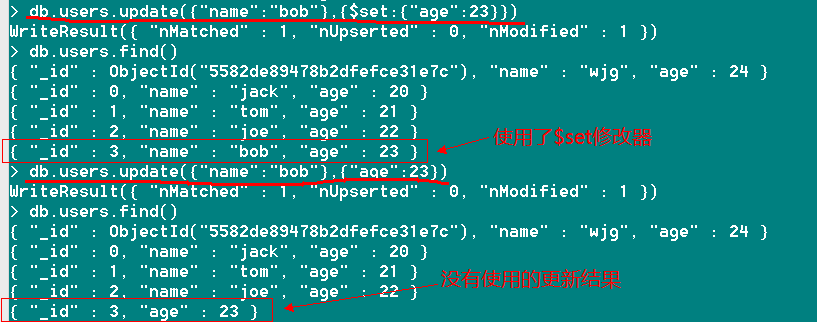
注:如果需要更新的字段不存在,那么MongoDB会按字段顺序进行插入,类似于上边提到的特殊更新。
其实细心的童鞋会发现,我们都是以name作为条件进行更新,所以并不能保证其唯一性,那么MongoDB只会更新匹配到的第一个文档。
这里还是建议大家指定一个唯一的文档进行更新,"_id"可以帮你保证!
b)、使用选择器更新(重点)
1、$set修改器
执行特殊更新操作;可以修改内嵌文档;甚至可以更改键的类型;
Ⅰ、假设需求改了,我们需要为为所有用户添加一个”hobby“的属性用于存放用户的喜好,那么我们可以这样做:
db.users.update({},{$set:{"hobby":"read"}}) //这样做是错的,哈哈。。
更新后的文档如下:

切记:update方法只会更新它匹配到的第一个文档对象,所以这个操作只会将名字为”wjg“的用户添加一个”hobby“属性,其它对象不会添加
正确方式如下:
db.users.update({},{$set:{"hobby":"write"}},false,true) //第三个参数为是否启用特殊更新,第四个为是否更新所有匹配的文档;
这俩参数默认都为false
更新后的文档如下:

可以看到我们成功更新了五个文档对象
Ⅱ、假设我们需求又变了,老板说了,每个用户的爱好会有多个。那么简单,因为我们可以直接将string类型的hobby属性改成string数组类型的
db.users.update({"_id":0},{"$set":{"hobby":["write","read","paly ping-pong"]}}) //将_id为0的hobby属性更新为数组类型的
Ⅲ、然后我们发现tom压根就没有爱好,那么我们可以使用$unset修改器将其删除
db.users.update({"_id":1},{"$unset":{"hobby":1}}) //1表示彻底删除这个键值对
Ⅳ、现在已经过去一年了,我们是时候把所有用户的年龄加一岁了。这时$inc上场
db.users.update({},{"$inc":{"age":1}},false,true) //别忘了将第四个参数置为true
注:$inc修改器只针对数字类型,如果是string或者其他类型的会提示报错:
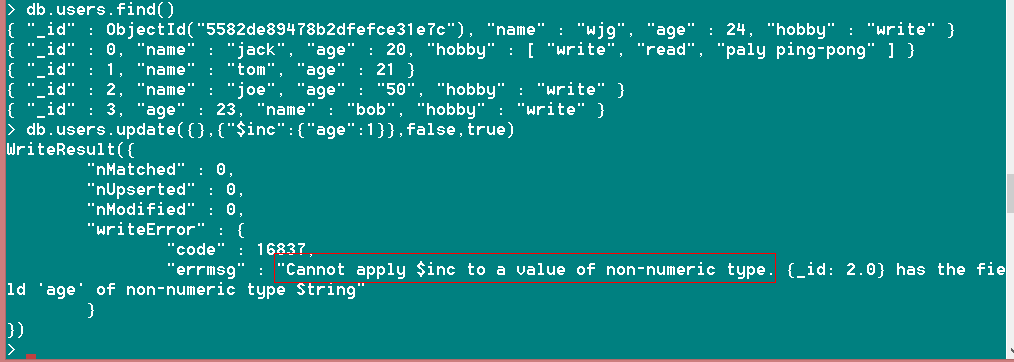
提示无法将$inc应用到非数字类型上,并且给出错误位置:”_id“为2的文档;
我们将joe的age改为数字类型的重新执行一次,就可以成功啦!
Ⅴ、过了一段时间,jack又喜欢上了游泳,那么我们可以用$push这样搞:
db.users.update({"_id":0},{"$push":{"hobby":"swim"}}) //hobby必须是一个数组,所以你在其他文档上使用是不会成功的
Ⅵ、然而jack不喜欢读书了,我们就用$pull来移除“read”元素
db.users.update({"_id":0},{"$pull":{"hobby":"read"}}) //它会移除数组中所有匹配到的“read”元素
另外:db.users.update({"_id":0},{"$pop":{"hobby":1}}) //表示移除hobby中的最后一个元素,为-1表示移除第一个元素

不知道大家有没有发现,“_id”为0的文档从第二的位置被移动到了数据集的末尾,这是因为该文档尺寸变大的原因导致的,
原先的位置已经容不下它了!
那么这就引出了另外一个概念:填充因子,它是MongoDB为每个新文档预留的增长空间。上边的这种情况就会使填充因子增加。
移动文档是一个非常缓慢的操作,尽量让填充因子的值接近1;
通过db.users.stats()查看该数据集信息,“paddingFactor”即为填充因子的大小;
三、删除
删除文档相对来说就简单了许多
1、单一删除
给定一个查询参数,只要符合条件的,都会被删除
db.users.remove({"_id":{"$lte":1}}) //删除“_id”的值小于等于1的所有文档
返回结果如下:
WriteResult({"nRemoved":2}) //成功删除了两个文档
2、清空整个数据集
db.users.remove()
如果数据较多的话,用db.users.drop()会明显提升删除速度
注:删除都是不可逆的,不能撤销,也不能恢复,所以要谨慎使用;
清空数据集的时候集合本身并不会被删除,也不会删除集合的元信息;
四、未解决问题
1、先取出来再更新,使用查询条件取出来的数据都无法用游标去获取值,但是用findOne获取的一个文档对象就可以。。。
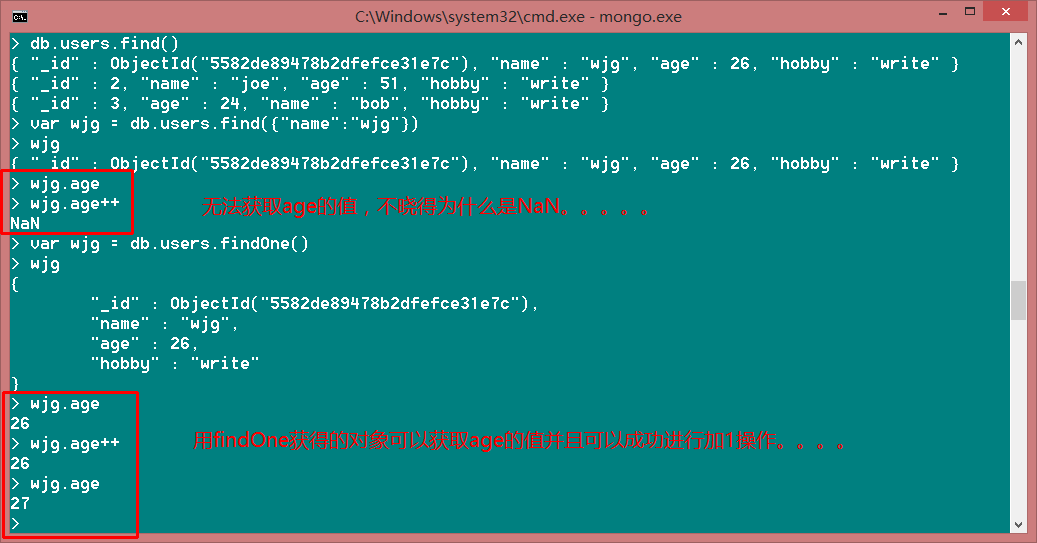
如果哪位大神知道的话麻烦告诉小弟一下,多谢、、、哈哈。。
最后一个问题已经找到,原因如下:
第一个find操作虽然获取的只是一个文档对象,看似和下边用findOne是一样的效果,但是在MongoDB的shell中第一个的结果集是被默认为多个文档集合,所以它无法判断你想获取的是哪个文档的age。
加载全部内容